 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDebiased Fine-Tuning for Vision-language Models by Prompt Regularization
Jan 29, 2023



We present a new paradigm for fine-tuning large-scale visionlanguage pre-trained models on downstream task, dubbed Prompt Regularization (ProReg). Different from traditional fine-tuning which easily overfits to the downstream task data, ProReg uses the prediction by prompting the pretrained model to regularize the fine-tuning. The motivation is: by prompting the large model "a photo of a [CLASS]", the fil-lin answer is only dependent on the pretraining encyclopedic knowledge while independent of the task data distribution, which is usually biased. Specifically, given a training sample prediction during fine-tuning, we first calculate its KullbackLeibler loss of the prompt prediction and Cross-Entropy loss of the ground-truth label, and then combine them with a proposed sample-wise adaptive trade-off weight, which automatically adjusts the transfer between the pretrained and downstream domains. On various out-of-distribution benchmarks, we show the consistently strong performance of ProReg compared with conventional fine-tuning, zero-shot prompt, prompt tuning, and other state-of-the-art methods.
Humans need not label more humans: Occlusion Copy & Paste for Occluded Human Instance Segmentation
Oct 07, 2022



Modern object detection and instance segmentation networks stumble when picking out humans in crowded or highly occluded scenes. Yet, these are often scenarios where we require our detectors to work well. Many works have approached this problem with model-centric improvements. While they have been shown to work to some extent, these supervised methods still need sufficient relevant examples (i.e. occluded humans) during training for the improvements to be maximised. In our work, we propose a simple yet effective data-centric approach, Occlusion Copy & Paste, to introduce occluded examples to models during training - we tailor the general copy & paste augmentation approach to tackle the difficult problem of same-class occlusion. It improves instance segmentation performance on occluded scenarios for "free" just by leveraging on existing large-scale datasets, without additional data or manual labelling needed. In a principled study, we show whether various proposed add-ons to the copy & paste augmentation indeed contribute to better performance. Our Occlusion Copy & Paste augmentation is easily interoperable with any models: by simply applying it to a recent generic instance segmentation model without explicit model architectural design to tackle occlusion, we achieve state-of-the-art instance segmentation performance on the very challenging OCHuman dataset. Source code is available at https://github.com/levan92/occlusion-copy-paste.
Joint Contrastive Learning for Unsupervised Domain Adaptation
Jun 18, 2020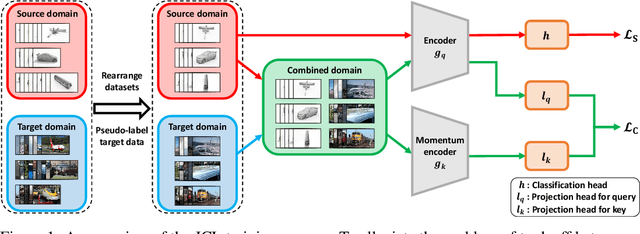
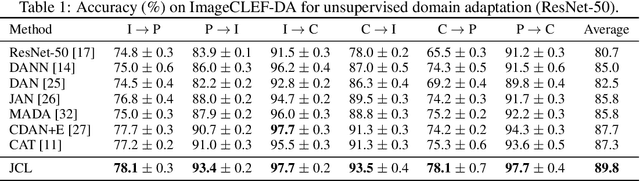
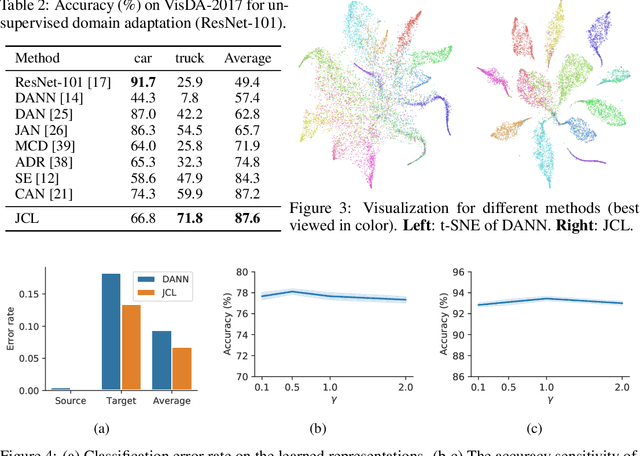

Enhancing feature transferability by matching marginal distributions has led to improvements in domain adaptation, although this is at the expense of feature discrimination. In particular, the ideal joint hypothesis error in the target error upper bound, which was previously considered to be minute, has been found to be significant, impairing its theoretical guarantee. In this paper, we propose an alternative upper bound on the target error that explicitly considers the joint error to render it more manageable. With the theoretical analysis, we suggest a joint optimization framework that combines the source and target domains. Further, we introduce Joint Contrastive Learning (JCL) to find class-level discriminative features, which is essential for minimizing the joint error. With a solid theoretical framework, JCL employs contrastive loss to maximize the mutual information between a feature and its label, which is equivalent to maximizing the Jensen-Shannon divergence between conditional distributions. Experiments on two real-world datasets demonstrate that JCL outperforms the state-of-the-art methods.