 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Empirical Study of World Model Quantization
Feb 02, 2026World models learn an internal representation of environment dynamics, enabling agents to simulate and reason about future states within a compact latent space for tasks such as planning, prediction, and inference. However, running world models rely on hevay computational cost and memory footprint, making model quantization essential for efficient deployment. To date, the effects of post-training quantization (PTQ) on world models remain largely unexamined. In this work, we present a systematic empirical study of world model quantization using DINO-WM as a representative case, evaluating diverse PTQ methods under both weight-only and joint weight-activation settings. We conduct extensive experiments on different visual planning tasks across a wide range of bit-widths, quantization granularities, and planning horizons up to 50 iterations. Our results show that quantization effects in world models extend beyond standard accuracy and bit-width trade-offs: group-wise weight quantization can stabilize low-bit rollouts, activation quantization granularity yields inconsistent benefits, and quantization sensitivity is highly asymmetric between encoder and predictor modules. Moreover, aggressive low-bit quantization significantly degrades the alignment between the planning objective and task success, leading to failures that cannot be remedied by additional optimization. These findings reveal distinct quantization-induced failure modes in world model-based planning and provide practical guidance for deploying quantized world models under strict computational constraints. The code will be available at https://github.com/huawei-noah/noah-research/tree/master/QuantWM.
EAQuant: Enhancing Post-Training Quantization for MoE Models via Expert-Aware Optimization
Jun 16, 2025Mixture-of-Experts (MoE) models have emerged as a cornerstone of large-scale deep learning by efficiently distributing computation and enhancing performance. However, their unique architecture-characterized by sparse expert activation and dynamic routing mechanisms-introduces inherent complexities that challenge conventional quantization techniques. Existing post-training quantization (PTQ) methods struggle to address activation outliers, router consistency and sparse expert calibration, leading to significant performance degradation. To bridge this gap, we propose EAQuant, a novel PTQ framework tailored for MoE architectures. Our method systematically tackles these challenges through three key innovations: (1) expert-aware smoothing aggregation to suppress activation outliers and stabilize quantization, (2) router logits distribution alignment to preserve expert selection consistency post-quantization, and (3) expert-level calibration data balance to optimize sparsely activated experts. Extensive experiments across W4A4 and extreme W3A4 quantization configurations demonstrate that EAQuant significantly outperforms existing methods, achieving average score improvements of 1.15 - 2.28% across three diverse MoE architectures, with particularly pronounced gains in reasoning tasks and robust performance retention under aggressive quantization. By integrating these innovations, EAQuant establishes a new state-of-the-art for high-precision, efficient MoE model compression. Our code is available at https://github.com/darren-fzq/EAQuant.
GPT4Image: Can Large Pre-trained Models Help Vision Models on Perception Tasks?
Jun 07, 2023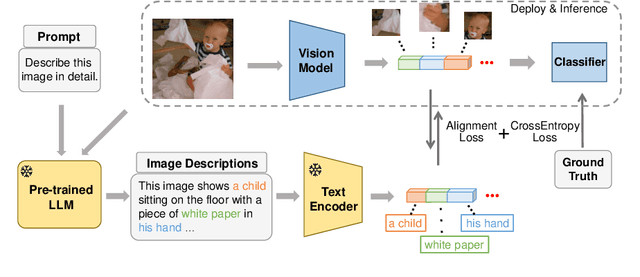


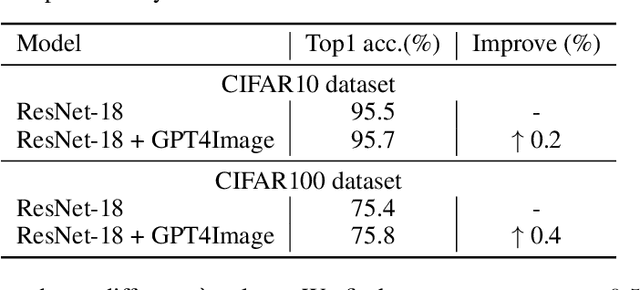
The recent upsurge in pre-trained large models (e.g. GPT-4) has swept across the entire deep learning community. Such powerful large language models (LLMs) demonstrate advanced generative ability and multimodal understanding capability, which quickly achieve new state-of-the-art performances on a variety of benchmarks. The pre-trained LLM usually plays the role as a universal AI model that can conduct various tasks, including context reasoning, article analysis and image content comprehension. However, considering the prohibitively high memory and computational cost for implementing such a large model, the conventional models (such as CNN and ViT), are still essential for many visual perception tasks. In this paper, we propose to enhance the representation ability of ordinary vision models for perception tasks (e.g. image classification) by taking advantage of large pre-trained models. We present a new learning paradigm in which the knowledge extracted from large pre-trained models are utilized to help models like CNN and ViT learn enhanced representations and achieve better performance. Firstly, we curate a high quality description set by prompting a multimodal LLM to generate descriptive text for all training images. Furthermore, we feed these detailed descriptions into a pre-trained encoder to extract text embeddings with rich semantic information that encodes the content of images. During training, text embeddings will serve as extra supervising signals and be aligned with image representations learned by vision models. The alignment process helps vision models learn better and achieve higher accuracy with the assistance of pre-trained LLMs. We conduct extensive experiments to verify that the proposed algorithm consistently improves the performance for various vision models with heterogeneous architectures.
Fast Camera Image Denoising on Mobile GPUs with Deep Learning, Mobile AI 2021 Challenge: Report
May 17, 2021

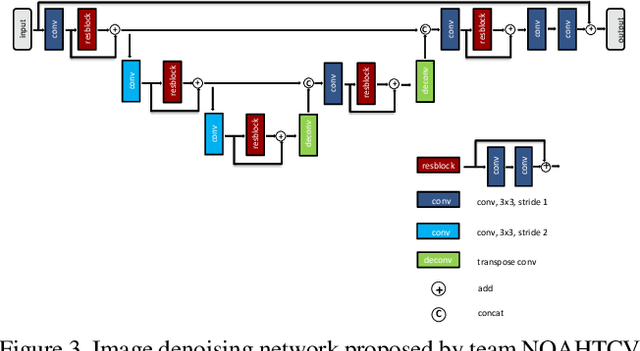
Image denoising is one of the most critical problems in mobile photo processing. While many solutions have been proposed for this task, they are usually working with synthetic data and are too computationally expensive to run on mobile devices. To address this problem, we introduce the first Mobile AI challenge, where the target is to develop an end-to-end deep learning-based image denoising solution that can demonstrate high efficiency on smartphone GPUs. For this, the participants were provided with a novel large-scale dataset consisting of noisy-clean image pairs captured in the wild. The runtime of all models was evaluated on the Samsung Exynos 2100 chipset with a powerful Mali GPU capable of accelerating floating-point and quantized neural networks. The proposed solutions are fully compatible with any mobile GPU and are capable of processing 480p resolution images under 40-80 ms while achieving high fidelity results. A detailed description of all models developed in the challenge is provided in this paper.
NTIRE 2021 Challenge on Quality Enhancement of Compressed Video: Methods and Results
May 02, 2021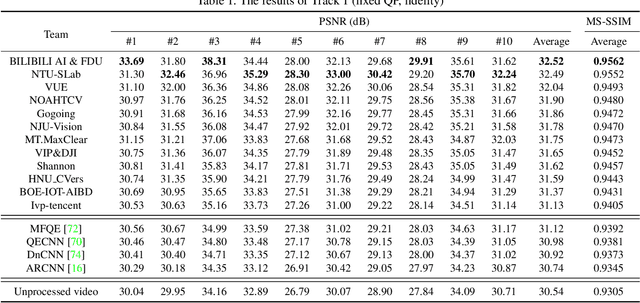
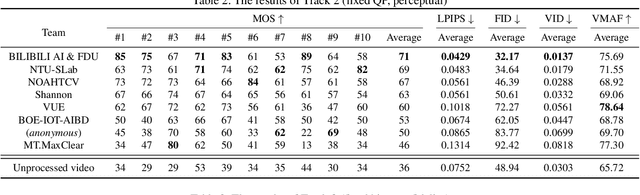
This paper reviews the first NTIRE challenge on quality enhancement of compressed video, with a focus on the proposed methods and results. In this challenge, the new Large-scale Diverse Video (LDV) dataset is employed. The challenge has three tracks. Tracks 1 and 2 aim at enhancing the videos compressed by HEVC at a fixed QP, while Track 3 is designed for enhancing the videos compressed by x265 at a fixed bit-rate. Besides, the quality enhancement of Tracks 1 and 3 targets at improving the fidelity (PSNR), and Track 2 targets at enhancing the perceptual quality. The three tracks totally attract 482 registrations. In the test phase, 12 teams, 8 teams and 11 teams submitted the final results of Tracks 1, 2 and 3, respectively. The proposed methods and solutions gauge the state-of-the-art of video quality enhancement. The homepage of the challenge: https://github.com/RenYang-home/NTIRE21_VEnh
Efficient Multi-Stage Video Denoising with Recurrent Spatio-Temporal Fusion
Mar 09, 2021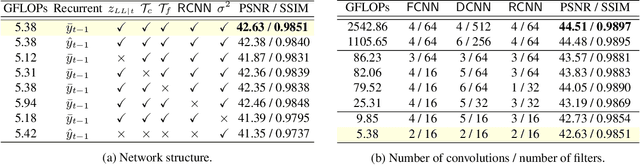
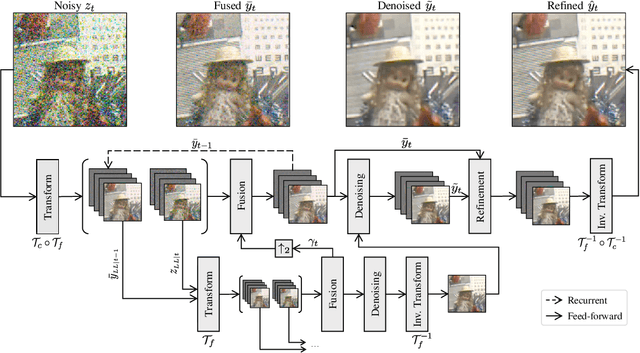
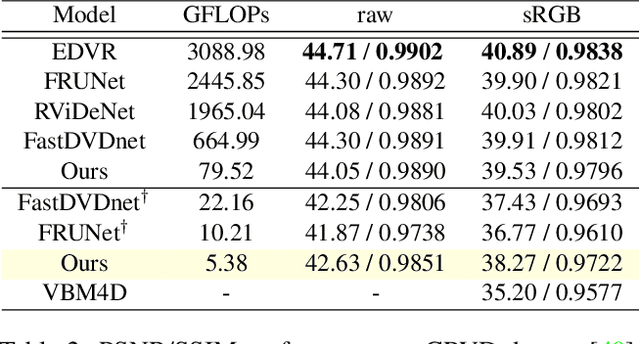
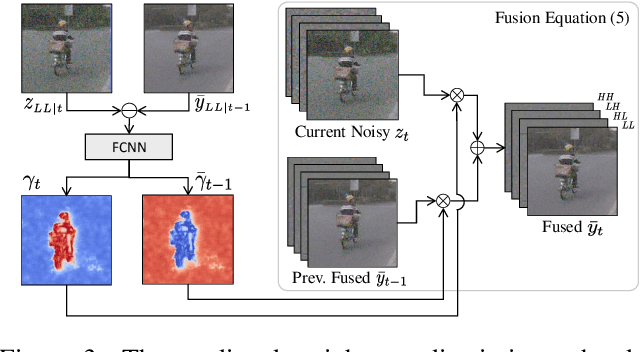
In recent years, methods based on deep learning have achieved unparalleled performance at the cost of large computational complexity. In this work, we propose an Efficient Multi-stage Video Denoising algorithm, called EMVD, to drastically reduce the complexity while maintaining or even improving the performance. First, a fusion stage reduces the noise through a recursive combination of all past frames in the video. Then, a denoising stage removes the noise in the fused frame. Finally, a refinement stage restores the missing high frequency in the denoised frame. All stages operate on a transform-domain representation obtained by learnable and invertible linear operators which simultaneously increase accuracy and decrease complexity of the model. A single loss on the final output is sufficient for successful convergence, hence making EMVD easy to train. Experiments on real raw data demonstrate that EMVD outperforms the state of the art when complexity is constrained, and even remains competitive against methods whose complexities are several orders of magnitude higher. The low complexity and memory requirements of EMVD enable real-time video denoising on low-powered commercial SoC.