 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLION-DG: Layer-Informed Initialization with Deep Gradient Protocols for Accelerated Neural Network Training
Jan 05, 2026Weight initialization remains decisive for neural network optimization, yet existing methods are largely layer-agnostic. We study initialization for deeply-supervised architectures with auxiliary classifiers, where untrained auxiliary heads can destabilize early training through gradient interference. We propose LION-DG, a layer-informed initialization that zero-initializes auxiliary classifier heads while applying standard He-initialization to the backbone. We prove that this implements Gradient Awakening: auxiliary gradients are exactly zero at initialization, then phase in naturally as weights grow -- providing an implicit warmup without hyperparameters. Experiments on CIFAR-10 and CIFAR-100 with DenseNet-DS and ResNet-DS architectures demonstrate: (1) DenseNet-DS: +8.3% faster convergence on CIFAR-10 with comparable accuracy, (2) Hybrid approach: Combining LSUV with LION-DG achieves best accuracy (81.92% on CIFAR-10), (3) ResNet-DS: Positive speedup on CIFAR-100 (+11.3%) with side-tap auxiliary design. We identify architecture-specific trade-offs and provide clear guidelines for practitioners. LION-DG is simple, requires zero hyperparameters, and adds no computational overhead.
Defensive M2S: Training Guardrail Models on Compressed Multi-turn Conversations
Jan 01, 2026Guardrail models are essential for ensuring the safety of Large Language Model (LLM) deployments, but processing full multi-turn conversation histories incurs significant computational cost. We propose Defensive M2S, a training paradigm that fine-tunes guardrail models on Multi-turn to Single-turn (M2S) compressed conversations rather than complete dialogue histories. We provide a formal complexity analysis showing that M2S reduces training cost from $O(n^2)$ to $O(n)$ for $n$-turn conversations. Empirically, on our training dataset (779 samples, avg. 10.6 turns), M2S requires only 169K tokens compared to 15.7M tokens for the multi-turn baseline -- a 93$\times$ reduction. We evaluate Defensive M2S across three guardrail model families (LlamaGuard, Nemotron, Qwen3Guard) and three compression templates (hyphenize, numberize, pythonize) on SafeDialBench, a comprehensive multi-turn jailbreak benchmark. Our best configuration, Qwen3Guard with hyphenize compression, achieves 93.8% attack detection recall while reducing inference tokens by 94.6% (from 3,231 to 173 tokens per conversation). This represents a 38.9 percentage point improvement over the baseline while dramatically reducing both training and inference costs. Our findings demonstrate that M2S compression can serve as an effective efficiency technique for guardrail deployment, enabling scalable safety screening of long multi-turn conversations.
Geometric Regularization in Mixture-of-Experts: The Disconnect Between Weights and Activations
Jan 01, 2026Mixture-of-Experts (MoE) models achieve efficiency through sparse activation, but the role of geometric regularization in expert specialization remains unclear. We apply orthogonality loss to enforce expert diversity and find it fails on multiple fronts: it does not reduce weight-space overlap (MSO actually increases by up to 114%), activation-space overlap remains high (~0.6) regardless of regularization, and effects on performance are inconsistent -- marginal improvement on WikiText-103 (-0.9%), slight degradation on TinyStories (+0.9%), and highly variable results on PTB (std > 1.0). Our analysis across 7 regularization strengths reveals no significant correlation (r = -0.293, p = 0.523) between weight and activation orthogonality. These findings demonstrate that weight-space regularization neither achieves its geometric goal nor reliably improves performance, making it unsuitable for MoE diversity.
HOLOGRAPH: Active Causal Discovery via Sheaf-Theoretic Alignment of Large Language Model Priors
Dec 30, 2025Causal discovery from observational data remains fundamentally limited by identifiability constraints. Recent work has explored leveraging Large Language Models (LLMs) as sources of prior causal knowledge, but existing approaches rely on heuristic integration that lacks theoretical grounding. We introduce HOLOGRAPH, a framework that formalizes LLM-guided causal discovery through sheaf theory--representing local causal beliefs as sections of a presheaf over variable subsets. Our key insight is that coherent global causal structure corresponds to the existence of a global section, while topological obstructions manifest as non-vanishing sheaf cohomology. We propose the Algebraic Latent Projection to handle hidden confounders and Natural Gradient Descent on the belief manifold for principled optimization. Experiments on synthetic and real-world benchmarks demonstrate that HOLOGRAPH provides rigorous mathematical foundations while achieving competitive performance on causal discovery tasks with 50-100 variables. Our sheaf-theoretic analysis reveals that while Identity, Transitivity, and Gluing axioms are satisfied to numerical precision (<10^{-6}), the Locality axiom fails for larger graphs, suggesting fundamental non-local coupling in latent variable projections. Code is available at [https://github.com/hyunjun1121/holograph](https://github.com/hyunjun1121/holograph).
MacroBench: A Novel Testbed for Web Automation Scripts via Large Language Models
Oct 05, 2025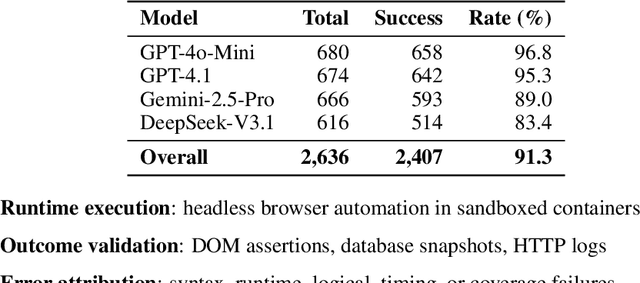
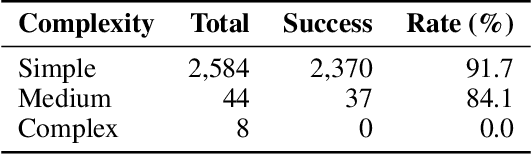
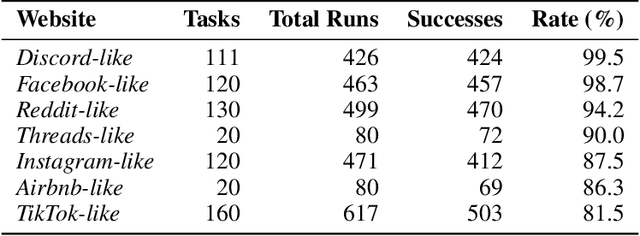
We introduce MacroBench, a code-first benchmark that evaluates whether LLMs can synthesize reusable browser automation programs from natural language goals by reading HTML/DOM and emitting Python with Selenium. MacroBench instantiates seven self-hosted sites: Airbnb-like, TikTok-like, Reddit-like, Instagram-like, Facebook-like, Discord-like, and Threads-like, covering 681 tasks across interaction complexity and targeting difficulty. Our end-to-end protocol validates generated code via static checks, sandboxed execution, and outcome verification including DOM assertions and database snapshots, and includes a safety suite for scraping, spam/abuse, and credential/privacy prompts. Across 2636 model-task runs, we observe stratified success: GPT-4o-Mini achieves 96.8 percent, GPT-4.1 achieves 95.3 percent, Gemini-2.5-Pro achieves 89.0 percent, and DeepSeek-V3.1 achieves 83.4 percent. Models handle simple tasks reliably at 91.7 percent but fail on complex workflows at 0.0 percent, and none meet production-quality coding practices despite functional completion. We release our complete benchmark pipeline, evaluation framework, and experimental results to enable reproducible assessment of macro synthesis for web automation.
X-Teaming Evolutionary M2S: Automated Discovery of Multi-turn to Single-turn Jailbreak Templates
Sep 10, 2025Multi-turn-to-single-turn (M2S) compresses iterative red-teaming into one structured prompt, but prior work relied on a handful of manually written templates. We present X-Teaming Evolutionary M2S, an automated framework that discovers and optimizes M2S templates through language-model-guided evolution. The system pairs smart sampling from 12 sources with an LLM-as-judge inspired by StrongREJECT and records fully auditable logs. Maintaining selection pressure by setting the success threshold to $\theta = 0.70$, we obtain five evolutionary generations, two new template families, and 44.8% overall success (103/230) on GPT-4.1. A balanced cross-model panel of 2,500 trials (judge fixed) shows that structural gains transfer but vary by target; two models score zero at the same threshold. We also find a positive coupling between prompt length and score, motivating length-aware judging. Our results demonstrate that structure-level search is a reproducible route to stronger single-turn probes and underscore the importance of threshold calibration and cross-model evaluation. Code, configurations, and artifacts are available at https://github.com/hyunjun1121/M2S-x-teaming.
ObjexMT: Objective Extraction and Metacognitive Calibration for LLM-as-a-Judge under Multi-Turn Jailbreaks
Aug 23, 2025Large language models (LLMs) are increasingly used as judges of other models, yet it is unclear whether a judge can reliably infer the latent objective of the conversation it evaluates, especially when the goal is distributed across noisy, adversarial, multi-turn jailbreaks. We introduce OBJEX(MT), a benchmark that requires a model to (i) distill a transcript into a single-sentence base objective and (ii) report its own confidence. Accuracy is scored by an LLM judge using semantic similarity between extracted and gold objectives; correctness uses a single human-aligned threshold calibrated once on N=100 items (tau* = 0.61); and metacognition is evaluated with ECE, Brier score, Wrong@High-Conf, and risk-coverage curves. We evaluate gpt-4.1, claude-sonnet-4, and Qwen3-235B-A22B-FP8 on SafeMT Attack_600, SafeMTData_1K, MHJ, and CoSafe. claude-sonnet-4 attains the highest objective-extraction accuracy (0.515) and the best calibration (ECE 0.296; Brier 0.324), while gpt-4.1 and Qwen3 tie at 0.441 accuracy yet show marked overconfidence (mean confidence approx. 0.88 vs. accuracy approx. 0.44; Wrong@0.90 approx. 48-52%). Performance varies sharply across datasets (approx. 0.167-0.865), with MHJ comparatively easy and Attack_600/CoSafe harder. These results indicate that LLM judges often misinfer objectives with high confidence in multi-turn jailbreaks and suggest operational guidance: provide judges with explicit objectives when possible and use selective prediction or abstention to manage risk. We release prompts, scoring templates, and complete logs to facilitate replication and analysis.
Experimental Analysis of Productive Interaction Strategy with ChatGPT: User Study on Function and Project-level Code Generation Tasks
Aug 06, 2025The application of Large Language Models (LLMs) is growing in the productive completion of Software Engineering tasks. Yet, studies investigating the productive prompting techniques often employed a limited problem space, primarily focusing on well-known prompting patterns and mainly targeting function-level SE practices. We identify significant gaps in real-world workflows that involve complexities beyond class-level (e.g., multi-class dependencies) and different features that can impact Human-LLM Interactions (HLIs) processes in code generation. To address these issues, we designed an experiment that comprehensively analyzed the HLI features regarding the code generation productivity. Our study presents two project-level benchmark tasks, extending beyond function-level evaluations. We conducted a user study with 36 participants from diverse backgrounds, asking them to solve the assigned tasks by interacting with the GPT assistant using specific prompting patterns. We also examined the participants' experience and their behavioral features during interactions by analyzing screen recordings and GPT chat logs. Our statistical and empirical investigation revealed (1) that three out of 15 HLI features significantly impacted the productivity in code generation; (2) five primary guidelines for enhancing productivity for HLI processes; and (3) a taxonomy of 29 runtime and logic errors that can occur during HLI processes, along with suggested mitigation plans.
Language-guided Learning for Object Detection Tackling Multiple Variations in Aerial Images
May 29, 2025Despite recent advancements in computer vision research, object detection in aerial images still suffers from several challenges. One primary challenge to be mitigated is the presence of multiple types of variation in aerial images, for example, illumination and viewpoint changes. These variations result in highly diverse image scenes and drastic alterations in object appearance, so that it becomes more complicated to localize objects from the whole image scene and recognize their categories. To address this problem, in this paper, we introduce a novel object detection framework in aerial images, named LANGuage-guided Object detection (LANGO). Upon the proposed language-guided learning, the proposed framework is designed to alleviate the impacts from both scene and instance-level variations. First, we are motivated by the way humans understand the semantics of scenes while perceiving environmental factors in the scenes (e.g., weather). Therefore, we design a visual semantic reasoner that comprehends visual semantics of image scenes by interpreting conditions where the given images were captured. Second, we devise a training objective, named relation learning loss, to deal with instance-level variations, such as viewpoint angle and scale changes. This training objective aims to learn relations in language representations of object categories, with the help of the robust characteristics against such variations. Through extensive experiments, we demonstrate the effectiveness of the proposed method, and our method obtains noticeable detection performance improvements.
DIP-R1: Deep Inspection and Perception with RL Looking Through and Understanding Complex Scenes
May 29, 2025Multimodal Large Language Models (MLLMs) have demonstrated significant visual understanding capabilities, yet their fine-grained visual perception in complex real-world scenarios, such as densely crowded public areas, remains limited. Inspired by the recent success of reinforcement learning (RL) in both LLMs and MLLMs, in this paper, we explore how RL can enhance visual perception ability of MLLMs. Then we develop a novel RL-based framework, Deep Inspection and Perception with RL (DIP-R1) designed to enhance the visual perception capabilities of MLLMs, by comprehending complex scenes and looking through visual instances closely. DIP-R1 guides MLLMs through detailed inspection of visual scene via three simply designed rule-based reward modelings. First, we adopt a standard reasoning reward encouraging the model to include three step-by-step processes: 1) reasoning for understanding visual scenes, 2) observing for looking through interested but ambiguous regions, and 3) decision-making for predicting answer. Second, a variance-guided looking reward is designed to examine uncertain regions for the second observing process. It explicitly enables the model to inspect ambiguous areas, improving its ability to mitigate perceptual uncertainties. Third, we model a weighted precision-recall accuracy reward enhancing accurate decision-making. We explore its effectiveness across diverse fine-grained object detection data consisting of challenging real-world environments, such as densely crowded scenes. Built upon existing MLLMs, DIP-R1 achieves consistent and significant improvement across various in-domain and out-of-domain scenarios. It also outperforms various existing baseline models and supervised fine-tuning methods. Our findings highlight the substantial potential of integrating RL into MLLMs for enhancing capabilities in complex real-world perception tasks.