 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmpathetic Response in Audio-Visual Conversations Using Emotion Preference Optimization and MambaCompressor
Dec 23, 2024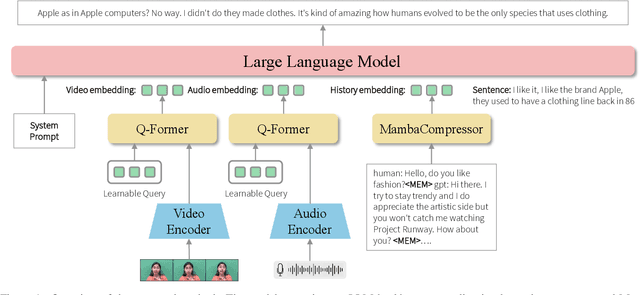
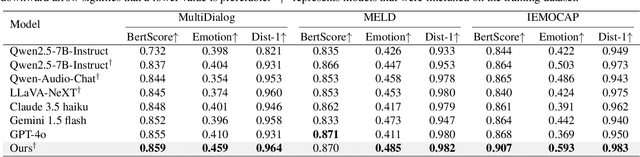
Chatbot research is advancing with the growing importance of chatbots in fields that require human interactions, such as customer support and mental health care. Despite these advancements, chatbots still face significant challenges in understanding subtle nuances and managing long conversation histories. To address these issues, our study introduces a dual approach: firstly, we employ Emotional Preference Optimization (EPO) to train chatbots not only with correct responses but also with counter-emotional responses-those that are contextually similar but emotionally divergent. This training enables the model to discern fine nuance distinctions between correct and counter-emotional responses, thereby enhancing the quality of its responses. Secondly, we introduce MambaCompressor to effectively compress and manage extensive conversation histories, significantly reducing time and memory complexities while improving the chatbot's contextual understanding. Our comprehensive experiments across multiple datasets demonstrate that our model significantly outperforms existing models in generating empathetic responses and efficiently managing lengthy dialogues.
AV-EmoDialog: Chat with Audio-Visual Users Leveraging Emotional Cues
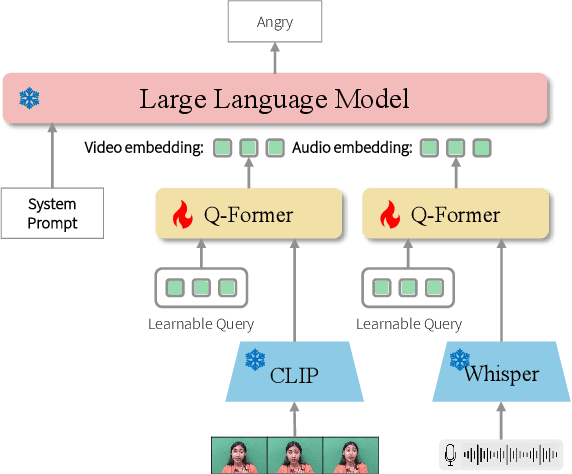
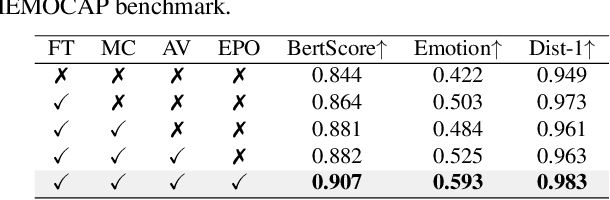
Dec 23, 2024In human communication, both verbal and non-verbal cues play a crucial role in conveying emotions, intentions, and meaning beyond words alone. These non-linguistic information, such as facial expressions, eye contact, voice tone, and pitch, are fundamental elements of effective interactions, enriching conversations by adding emotional and contextual depth. Recognizing the importance of non-linguistic content in communication, we present AV-EmoDialog, a dialogue system designed to exploit verbal and non-verbal information from users' audio-visual inputs to generate more responsive and empathetic interactions. AV-EmoDialog systematically exploits the emotional cues in audio-visual dialogues; extracting speech content and emotional tones from speech, analyzing fine-grained facial expressions from visuals, and integrating these cues to generate emotionally aware responses in an end-to-end manner. Through extensive experiments, we validate that the proposed AV-EmoDialog outperforms existing multimodal LLMs in generating not only emotionally appropriate but also contextually appropriate responses.
CODE: Contrasting Self-generated Description to Combat Hallucination in Large Multi-modal Models
Jun 04, 2024



Large Multi-modal Models (LMMs) have recently demonstrated remarkable abilities in visual context understanding and coherent response generation. However, alongside these advancements, the issue of hallucinations has emerged as a significant challenge, producing erroneous responses that are unrelated to the visual contents. In this paper, we introduce a novel contrastive-based decoding method, COuntering DEscription Contrastive Decoding (CODE), which leverages self-generated descriptions as contrasting references during the decoding phase of LMMs to address hallucination issues. CODE utilizes the comprehensive descriptions from model itself as visual counterpart to correct and improve response alignment with actual visual content. By dynamically adjusting the information flow and distribution of next-token predictions in the LMM's vocabulary, CODE enhances the coherence and informativeness of generated responses. Extensive experiments demonstrate that our method significantly reduces hallucinations and improves cross-modal consistency across various benchmarks and cutting-edge LMMs. Our method provides a simple yet effective decoding strategy that can be integrated to existing LMM frameworks without additional training.