 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMMS-LLaMA: Efficient LLM-based Audio-Visual Speech Recognition with Minimal Multimodal Speech Tokens
Mar 14, 2025



Audio-Visual Speech Recognition (AVSR) achieves robust speech recognition in noisy environments by combining auditory and visual information. However, recent Large Language Model (LLM) based AVSR systems incur high computational costs due to the high temporal resolution of audio-visual speech processed by LLMs. In this work, we introduce an efficient multimodal speech LLM framework that minimizes token length while preserving essential linguistic content. Our approach employs an early av-fusion module for streamlined feature integration, an audio-visual speech Q-Former that dynamically allocates tokens based on input duration, and a refined query allocation strategy with a speech rate predictor to adjust token allocation according to speaking speed of each audio sample. Extensive experiments on the LRS3 dataset show that our method achieves state-of-the-art performance with a WER of 0.74% while using only 3.5 tokens per second. Moreover, our approach not only reduces token usage by 86% compared to the previous multimodal speech LLM framework, but also improves computational efficiency by reducing FLOPs by 35.7%.
Long-Form Speech Generation with Spoken Language Models
Dec 24, 2024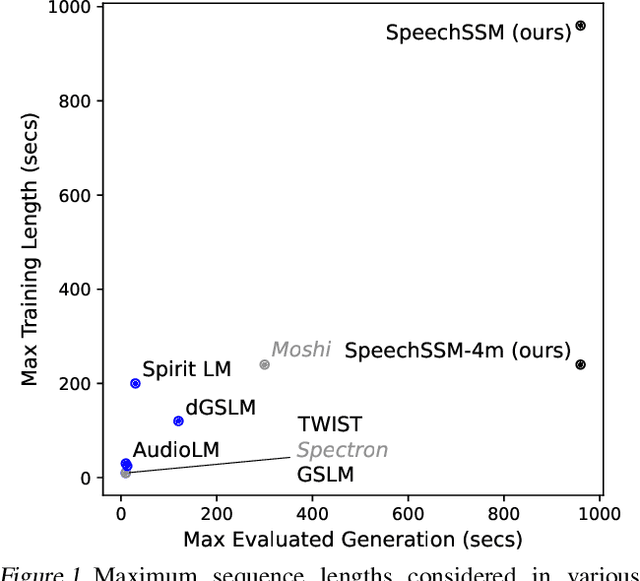
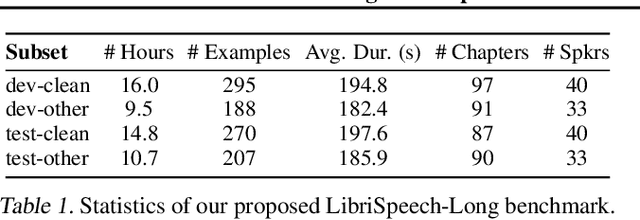

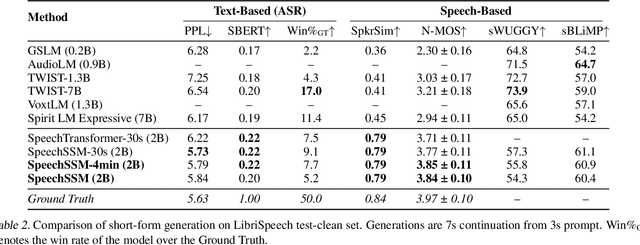
We consider the generative modeling of speech over multiple minutes, a requirement for long-form multimedia generation and audio-native voice assistants. However, current spoken language models struggle to generate plausible speech past tens of seconds, from high temporal resolution of speech tokens causing loss of coherence, to architectural issues with long-sequence training or extrapolation, to memory costs at inference time. With these considerations we propose SpeechSSM, the first speech language model to learn from and sample long-form spoken audio (e.g., 16 minutes of read or extemporaneous speech) in a single decoding session without text intermediates, based on recent advances in linear-time sequence modeling. Furthermore, to address growing challenges in spoken language evaluation, especially in this new long-form setting, we propose: new embedding-based and LLM-judged metrics; quality measurements over length and time; and a new benchmark for long-form speech processing and generation, LibriSpeech-Long. Speech samples and the dataset are released at https://google.github.io/tacotron/publications/speechssm/
Empathetic Response in Audio-Visual Conversations Using Emotion Preference Optimization and MambaCompressor
Dec 23, 2024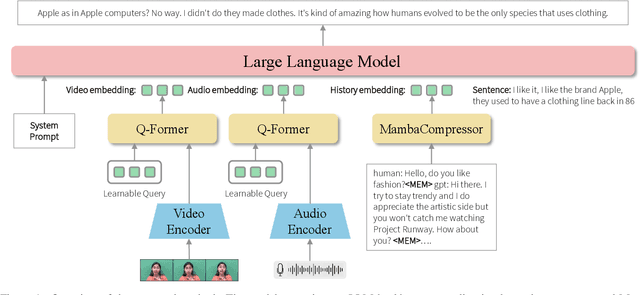
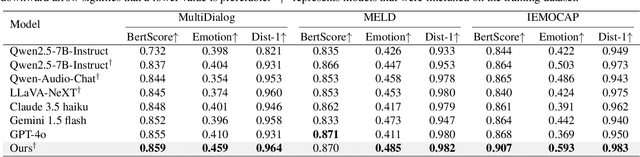
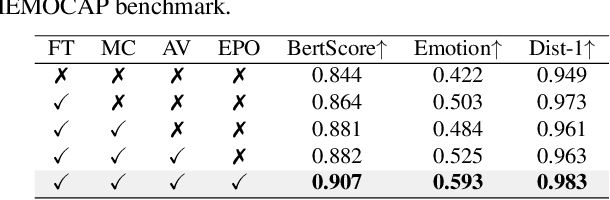
Chatbot research is advancing with the growing importance of chatbots in fields that require human interactions, such as customer support and mental health care. Despite these advancements, chatbots still face significant challenges in understanding subtle nuances and managing long conversation histories. To address these issues, our study introduces a dual approach: firstly, we employ Emotional Preference Optimization (EPO) to train chatbots not only with correct responses but also with counter-emotional responses-those that are contextually similar but emotionally divergent. This training enables the model to discern fine nuance distinctions between correct and counter-emotional responses, thereby enhancing the quality of its responses. Secondly, we introduce MambaCompressor to effectively compress and manage extensive conversation histories, significantly reducing time and memory complexities while improving the chatbot's contextual understanding. Our comprehensive experiments across multiple datasets demonstrate that our model significantly outperforms existing models in generating empathetic responses and efficiently managing lengthy dialogues.
AV-EmoDialog: Chat with Audio-Visual Users Leveraging Emotional Cues
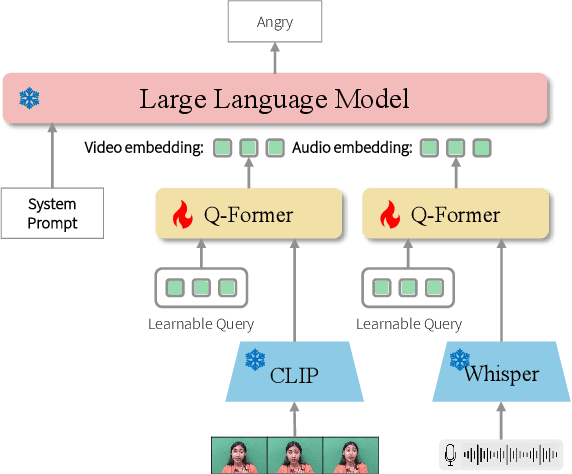
Dec 23, 2024In human communication, both verbal and non-verbal cues play a crucial role in conveying emotions, intentions, and meaning beyond words alone. These non-linguistic information, such as facial expressions, eye contact, voice tone, and pitch, are fundamental elements of effective interactions, enriching conversations by adding emotional and contextual depth. Recognizing the importance of non-linguistic content in communication, we present AV-EmoDialog, a dialogue system designed to exploit verbal and non-verbal information from users' audio-visual inputs to generate more responsive and empathetic interactions. AV-EmoDialog systematically exploits the emotional cues in audio-visual dialogues; extracting speech content and emotional tones from speech, analyzing fine-grained facial expressions from visuals, and integrating these cues to generate emotionally aware responses in an end-to-end manner. Through extensive experiments, we validate that the proposed AV-EmoDialog outperforms existing multimodal LLMs in generating not only emotionally appropriate but also contextually appropriate responses.
Let's Go Real Talk: Spoken Dialogue Model for Face-to-Face Conversation
Jun 12, 2024



In this paper, we introduce a novel Face-to-Face spoken dialogue model. It processes audio-visual speech from user input and generates audio-visual speech as the response, marking the initial step towards creating an avatar chatbot system without relying on intermediate text. To this end, we newly introduce MultiDialog, the first large-scale multimodal (i.e., audio and visual) spoken dialogue corpus containing 340 hours of approximately 9,000 dialogues, recorded based on the open domain dialogue dataset, TopicalChat. The MultiDialog contains parallel audio-visual recordings of conversation partners acting according to the given script with emotion annotations, which we expect to open up research opportunities in multimodal synthesis. Our Face-to-Face spoken dialogue model incorporates a textually pretrained large language model and adapts it into the audio-visual spoken dialogue domain by incorporating speech-text joint pretraining. Through extensive experiments, we validate the effectiveness of our model in facilitating a face-to-face conversation. Demo and data are available at https://multidialog.github.io and https://huggingface.co/datasets/IVLLab/MultiDialog, respectively.
Persona Extraction Through Semantic Similarity for Emotional Support Conversation Generation
Mar 07, 2024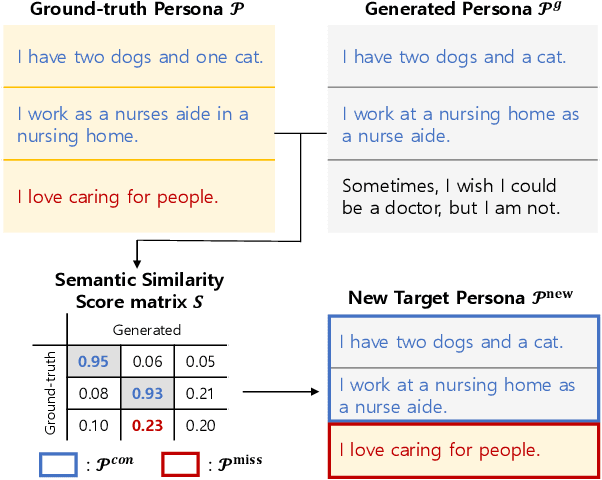


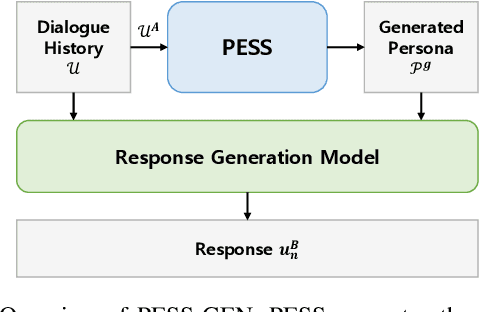
Providing emotional support through dialogue systems is becoming increasingly important in today's world, as it can support both mental health and social interactions in many conversation scenarios. Previous works have shown that using persona is effective for generating empathetic and supportive responses. They have often relied on pre-provided persona rather than inferring them during conversations. However, it is not always possible to obtain a user persona before the conversation begins. To address this challenge, we propose PESS (Persona Extraction through Semantic Similarity), a novel framework that can automatically infer informative and consistent persona from dialogues. We devise completeness loss and consistency loss based on semantic similarity scores. The completeness loss encourages the model to generate missing persona information, and the consistency loss guides the model to distinguish between consistent and inconsistent persona. Our experimental results demonstrate that high-quality persona information inferred by PESS is effective in generating emotionally supportive responses.
Multilingual Visual Speech Recognition with a Single Model by Learning with Discrete Visual Speech Units
Jan 18, 2024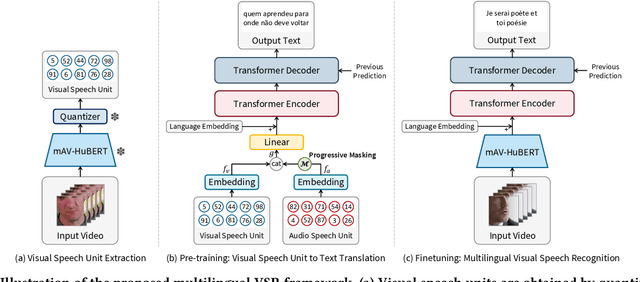
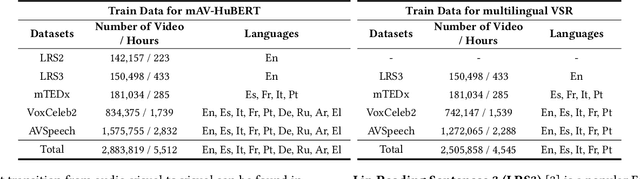
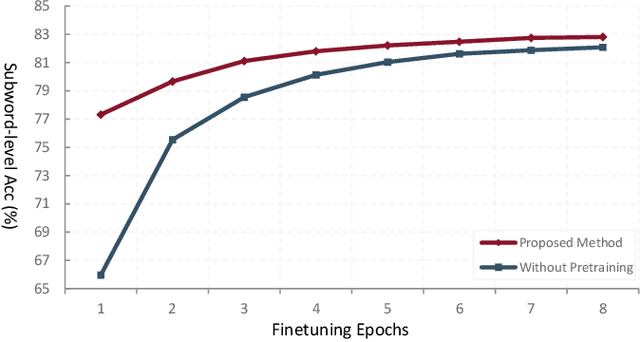
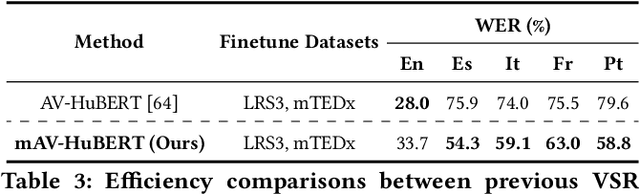
This paper explores sentence-level Multilingual Visual Speech Recognition with a single model for the first time. As the massive multilingual modeling of visual data requires huge computational costs, we propose a novel strategy, processing with visual speech units. Motivated by the recent success of the audio speech unit, the proposed visual speech unit is obtained by discretizing the visual speech features extracted from the self-supervised visual speech model. To correctly capture multilingual visual speech, we first train the self-supervised visual speech model on 5,512 hours of multilingual audio-visual data. Through analysis, we verify that the visual speech units mainly contain viseme information while suppressing non-linguistic information. By using the visual speech units as the inputs of our system, we pre-train the model to predict corresponding text outputs on massive multilingual data constructed by merging several VSR databases. As both the inputs and outputs are discrete, we can greatly improve the training efficiency compared to the standard VSR training. Specifically, the input data size is reduced to 0.016% of the original video inputs. In order to complement the insufficient visual information in speech recognition, we apply curriculum learning where the inputs of the system begin with audio-visual speech units and gradually change to visual speech units. After pre-training, the model is finetuned on continuous features. We set new state-of-the-art multilingual VSR performances by achieving comparable performances to the previous language-specific VSR models, with a single trained model.
AV2AV: Direct Audio-Visual Speech to Audio-Visual Speech Translation with Unified Audio-Visual Speech Representation
Dec 05, 2023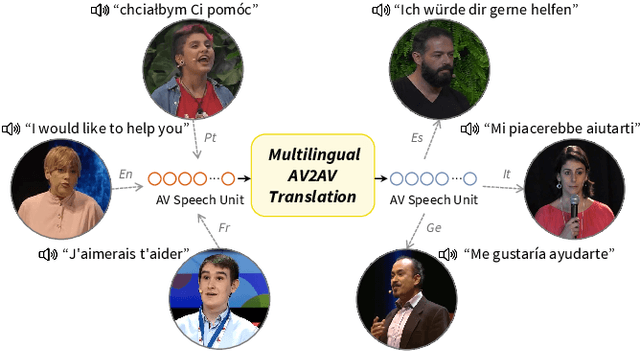
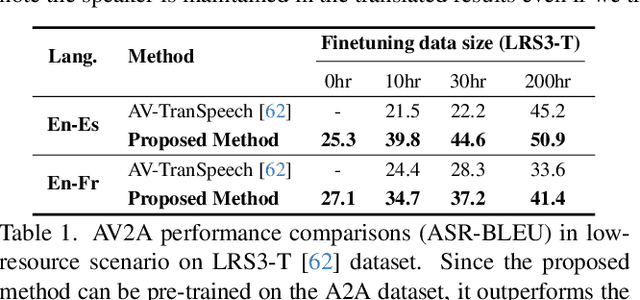
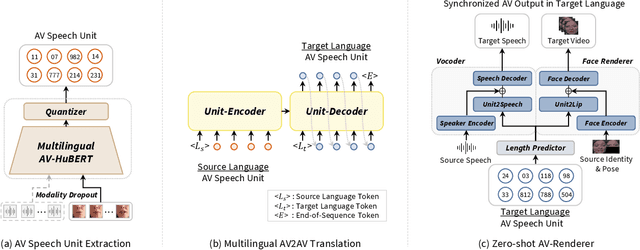
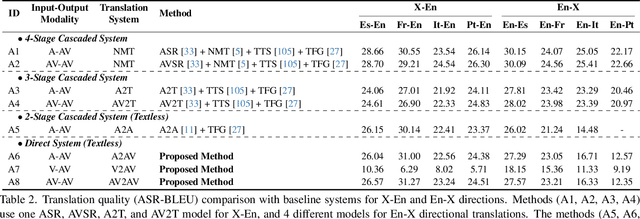
This paper proposes a novel direct Audio-Visual Speech to Audio-Visual Speech Translation (AV2AV) framework, where the input and output of the system are multimodal (i.e., audio and visual speech). With the proposed AV2AV, two key advantages can be brought: 1) We can perform real-like conversations with individuals worldwide in a virtual meeting by utilizing our own primary languages. In contrast to Speech-to-Speech Translation (A2A), which solely translates between audio modalities, the proposed AV2AV directly translates between audio-visual speech. This capability enhances the dialogue experience by presenting synchronized lip movements along with the translated speech. 2) We can improve the robustness of the spoken language translation system. By employing the complementary information of audio-visual speech, the system can effectively translate spoken language even in the presence of acoustic noise, showcasing robust performance. To mitigate the problem of the absence of a parallel AV2AV translation dataset, we propose to train our spoken language translation system with the audio-only dataset of A2A. This is done by learning unified audio-visual speech representations through self-supervised learning in advance to train the translation system. Moreover, we propose an AV-Renderer that can generate raw audio and video in parallel. It is designed with zero-shot speaker modeling, thus the speaker in source audio-visual speech can be maintained at the target translated audio-visual speech. The effectiveness of AV2AV is evaluated with extensive experiments in a many-to-many language translation setting. The demo page is available on https://choijeongsoo.github.io/av2av.
Intuitive Multilingual Audio-Visual Speech Recognition with a Single-Trained Model
Oct 23, 2023We present a novel approach to multilingual audio-visual speech recognition tasks by introducing a single model on a multilingual dataset. Motivated by a human cognitive system where humans can intuitively distinguish different languages without any conscious effort or guidance, we propose a model that can capture which language is given as an input speech by distinguishing the inherent similarities and differences between languages. To do so, we design a prompt fine-tuning technique into the largely pre-trained audio-visual representation model so that the network can recognize the language class as well as the speech with the corresponding language. Our work contributes to developing robust and efficient multilingual audio-visual speech recognition systems, reducing the need for language-specific models.
Reprogramming Audio-driven Talking Face Synthesis into Text-driven
Jun 28, 2023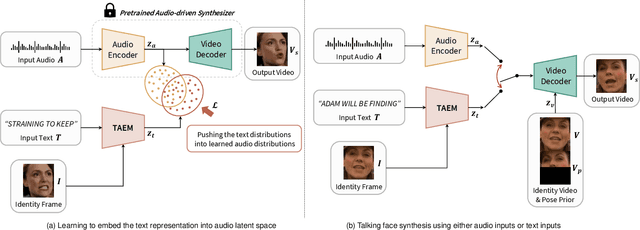
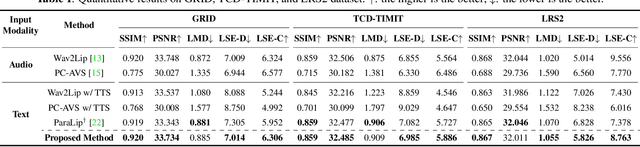
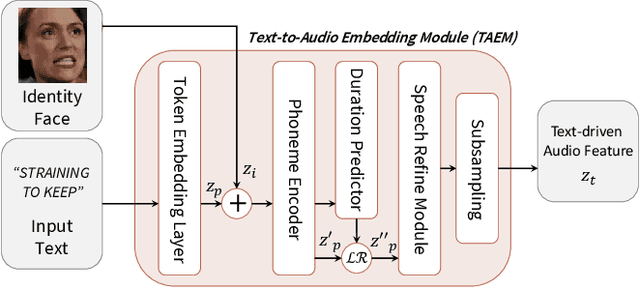
In this paper, we propose a method to reprogram pre-trained audio-driven talking face synthesis models to be able to operate with text inputs. As the audio-driven talking face synthesis model takes speech audio as inputs, in order to generate a talking avatar with the desired speech content, speech recording needs to be performed in advance. However, this is burdensome to record audio for every video to be generated. In order to alleviate this problem, we propose a novel method that embeds input text into the learned audio latent space of the pre-trained audio-driven model. To this end, we design a Text-to-Audio Embedding Module (TAEM) which is guided to learn to map a given text input to the audio latent features. Moreover, to model the speaker characteristics lying in the audio features, we propose to inject visual speaker embedding into the TAEM, which is obtained from a single face image. After training, we can synthesize talking face videos with either text or speech audio.