 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReprogramming Audio-driven Talking Face Synthesis into Text-driven
Paper and Code
Jun 28, 2023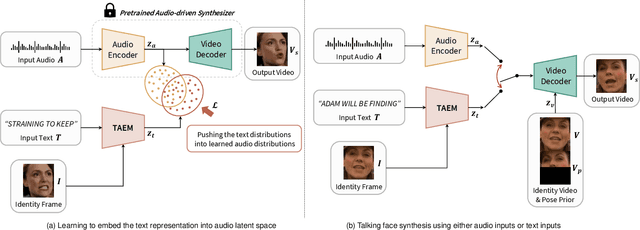
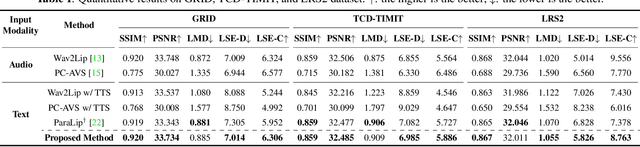
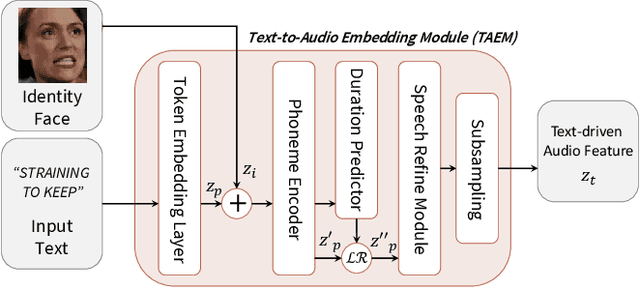
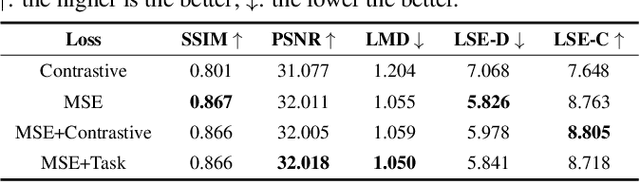
In this paper, we propose a method to reprogram pre-trained audio-driven talking face synthesis models to be able to operate with text inputs. As the audio-driven talking face synthesis model takes speech audio as inputs, in order to generate a talking avatar with the desired speech content, speech recording needs to be performed in advance. However, this is burdensome to record audio for every video to be generated. In order to alleviate this problem, we propose a novel method that embeds input text into the learned audio latent space of the pre-trained audio-driven model. To this end, we design a Text-to-Audio Embedding Module (TAEM) which is guided to learn to map a given text input to the audio latent features. Moreover, to model the speaker characteristics lying in the audio features, we propose to inject visual speaker embedding into the TAEM, which is obtained from a single face image. After training, we can synthesize talking face videos with either text or speech audio.