 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecoding Strategies for Diffusion-Based ASR: A Systematic Evaluation of Confidence-Based Thresholding
May 28, 2026While LLM-based Automatic Speech Recognition (ASR) achieves high accuracy, its speed is limited by sequential autoregressive decoding. Diffusion Language Models (DLMs) offer a parallel alternative, yet their decoding strategies remain under-explored in ASR contexts. This paper analyzes three decoding schemes for DLM-based ASR: fixed-number, static confidence threshold, and dynamic confidence threshold. We propose measuring round-wise accuracy using Negative Log-Likelihood-based uncertainty as a proxy for decoding progress. Our results show that both threshold-based strategies significantly outperform fixed-number schemes in accuracy and speed. We attribute this to a property unique to ASR: most tokens reach high confidence early, allowing reliable ones to be harvested aggressively while leaving only difficult tokens for later rounds. Notably, the static-threshold strategy matches the accuracy of autoregressive decoding while offering superior efficiency.
Diffusion Large Language Models for Visual Speech Recognition
May 27, 2026Existing Visual Speech Recognition (VSR) systems commonly rely on left-to-right autoregressive decoding, which can force premature decisions on visually ambiguous tokens before sufficient context is available. We propose DLLM-VSR, to the best of our knowledge, the first Diffusion Large Language Model (DLLM)-based VSR framework, formulating transcription as iterative masked denoising with flexible-order decoding. With confidence-based unmasking, DLLM-VSR commits high-confidence positions early and uses the committed tokens as bidirectional context to refine ambiguous ones. To adapt DLLMs to VSR, we introduce a two-stage masked-denoising training strategy that separates visual-to-text content alignment from length modeling. We further observe a performance gap with oracle-length decoding, which assumes access to the true transcript length, indicating that reducing target-length uncertainty can improve DLLM-based VSR. To reduce this gap, we develop length-guided candidate decoding, which uses video duration to construct plausible transcript-length hypotheses, decodes under multiple hypotheses, and reranks candidates using length plausibility and decoding confidence. The proposed method achieves a state-of-the-art WER of 19.5\% on LRS3 using only its labeled training data.
GCAgent: Long-Video Understanding via Schematic and Narrative Episodic Memory
Nov 15, 2025Long-video understanding remains a significant challenge for Multimodal Large Language Models (MLLMs) due to inherent token limitations and the complexity of capturing long-term temporal dependencies. Existing methods often fail to capture the global context and complex event relationships necessary for deep video reasoning. To address this, we introduce GCAgent, a novel Global-Context-Aware Agent framework that achieves comprehensive long-video understanding. Our core innovation is the Schematic and Narrative Episodic Memory. This memory structurally models events and their causal and temporal relations into a concise, organized context, fundamentally resolving the long-term dependency problem. Operating in a multi-stage Perception-Action-Reflection cycle, our GCAgent utilizes a Memory Manager to retrieve relevant episodic context for robust, context-aware inference. Extensive experiments confirm that GCAgent significantly enhances long-video understanding, achieving up to 23.5\% accuracy improvement on the Video-MME Long split over a strong MLLM baseline. Furthermore, our framework establishes state-of-the-art performance among comparable 7B-scale MLLMs, achieving 73.4\% accuracy on the Long split and the highest overall average (71.9\%) on the Video-MME benchmark, validating our agent-based reasoning paradigm and structured memory for cognitively-inspired long-video understanding.
MMS-LLaMA: Efficient LLM-based Audio-Visual Speech Recognition with Minimal Multimodal Speech Tokens
Mar 14, 2025



Audio-Visual Speech Recognition (AVSR) achieves robust speech recognition in noisy environments by combining auditory and visual information. However, recent Large Language Model (LLM) based AVSR systems incur high computational costs due to the high temporal resolution of audio-visual speech processed by LLMs. In this work, we introduce an efficient multimodal speech LLM framework that minimizes token length while preserving essential linguistic content. Our approach employs an early av-fusion module for streamlined feature integration, an audio-visual speech Q-Former that dynamically allocates tokens based on input duration, and a refined query allocation strategy with a speech rate predictor to adjust token allocation according to speaking speed of each audio sample. Extensive experiments on the LRS3 dataset show that our method achieves state-of-the-art performance with a WER of 0.74% while using only 3.5 tokens per second. Moreover, our approach not only reduces token usage by 86% compared to the previous multimodal speech LLM framework, but also improves computational efficiency by reducing FLOPs by 35.7%.
Zero-AVSR: Zero-Shot Audio-Visual Speech Recognition with LLMs by Learning Language-Agnostic Speech Representations
Mar 08, 2025We explore a novel zero-shot Audio-Visual Speech Recognition (AVSR) framework, dubbed Zero-AVSR, which enables speech recognition in target languages without requiring any audio-visual speech data in those languages. Specifically, we introduce the Audio-Visual Speech Romanizer (AV-Romanizer), which learns language-agnostic speech representations by predicting Roman text. Then, by leveraging the strong multilingual modeling capabilities of Large Language Models (LLMs), we propose converting the predicted Roman text into language-specific graphemes, forming the proposed Cascaded Zero-AVSR. Taking it a step further, we explore a unified Zero-AVSR approach by directly integrating the audio-visual speech representations encoded by the AV-Romanizer into the LLM. This is achieved through finetuning the adapter and the LLM using our proposed multi-task learning scheme. To capture the wide spectrum of phonetic and linguistic diversity, we also introduce a Multilingual Audio-Visual Romanized Corpus (MARC) consisting of 2,916 hours of audio-visual speech data across 82 languages, along with transcriptions in both language-specific graphemes and Roman text. Extensive analysis and experiments confirm that the proposed Zero-AVSR framework has the potential to expand language support beyond the languages seen during the training of the AV-Romanizer.
Personalized Lip Reading: Adapting to Your Unique Lip Movements with Vision and Language
Sep 02, 2024Lip reading aims to predict spoken language by analyzing lip movements. Despite advancements in lip reading technologies, performance degrades when models are applied to unseen speakers due to their sensitivity to variations in visual information such as lip appearances. To address this challenge, speaker adaptive lip reading technologies have advanced by focusing on effectively adapting a lip reading model to target speakers in the visual modality. The effectiveness of adapting language information, such as vocabulary choice, of the target speaker has not been explored in the previous works. Moreover, existing datasets for speaker adaptation have limited vocabulary size and pose variations, limiting the validation of previous speaker-adaptive methods in real-world scenarios. To address these issues, we propose a novel speaker-adaptive lip reading method that adapts a pre-trained model to target speakers at both vision and language levels. Specifically, we integrate prompt tuning and the LoRA approach, applying them to a pre-trained lip reading model to effectively adapt the model to target speakers. In addition, to validate its effectiveness in real-world scenarios, we introduce a new dataset, VoxLRS-SA, derived from VoxCeleb2 and LRS3. It contains a vocabulary of approximately 100K words, offers diverse pose variations, and enables the validation of adaptation methods in wild, sentence-level lip reading for the first time. Through various experiments, we demonstrate that the existing speaker-adaptive method also improves performance in the wild at the sentence level. Moreover, with the proposed adaptation method, we show that the proposed method achieves larger improvements when applied to the target speaker, compared to the previous works.
Let's Go Real Talk: Spoken Dialogue Model for Face-to-Face Conversation
Jun 12, 2024



In this paper, we introduce a novel Face-to-Face spoken dialogue model. It processes audio-visual speech from user input and generates audio-visual speech as the response, marking the initial step towards creating an avatar chatbot system without relying on intermediate text. To this end, we newly introduce MultiDialog, the first large-scale multimodal (i.e., audio and visual) spoken dialogue corpus containing 340 hours of approximately 9,000 dialogues, recorded based on the open domain dialogue dataset, TopicalChat. The MultiDialog contains parallel audio-visual recordings of conversation partners acting according to the given script with emotion annotations, which we expect to open up research opportunities in multimodal synthesis. Our Face-to-Face spoken dialogue model incorporates a textually pretrained large language model and adapts it into the audio-visual spoken dialogue domain by incorporating speech-text joint pretraining. Through extensive experiments, we validate the effectiveness of our model in facilitating a face-to-face conversation. Demo and data are available at https://multidialog.github.io and https://huggingface.co/datasets/IVLLab/MultiDialog, respectively.
Where Visual Speech Meets Language: VSP-LLM Framework for Efficient and Context-Aware Visual Speech Processing
Feb 23, 2024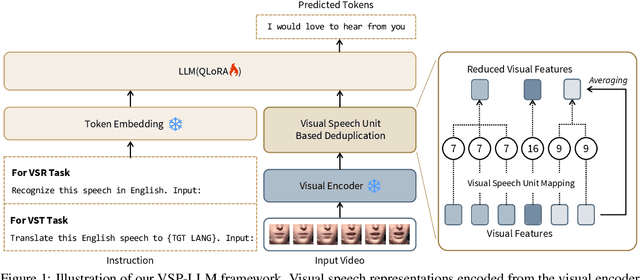
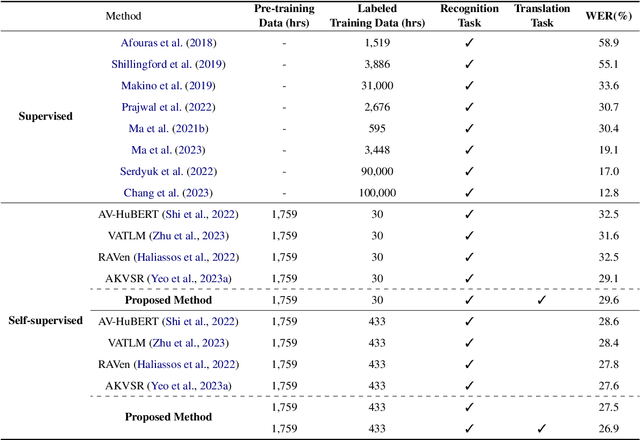

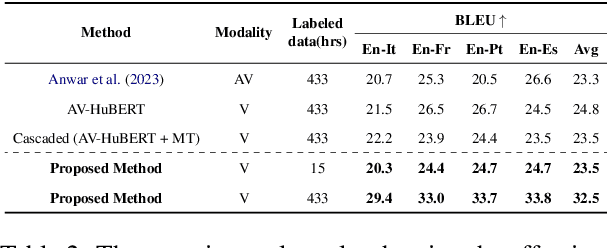
In visual speech processing, context modeling capability is one of the most important requirements due to the ambiguous nature of lip movements. For example, homophenes, words that share identical lip movements but produce different sounds, can be distinguished by considering the context. In this paper, we propose a novel framework, namely Visual Speech Processing incorporated with LLMs (VSP-LLM), to maximize the context modeling ability by bringing the overwhelming power of LLMs. Specifically, VSP-LLM is designed to perform multi-tasks of visual speech recognition and translation, where the given instructions control the type of task. The input video is mapped to the input latent space of a LLM by employing a self-supervised visual speech model. Focused on the fact that there is redundant information in input frames, we propose a novel deduplication method that reduces the embedded visual features by employing visual speech units. Through the proposed deduplication and Low Rank Adaptors (LoRA), VSP-LLM can be trained in a computationally efficient manner. In the translation dataset, the MuAViC benchmark, we demonstrate that VSP-LLM can more effectively recognize and translate lip movements with just 15 hours of labeled data, compared to the recent translation model trained with 433 hours of labeld data.
Multilingual Visual Speech Recognition with a Single Model by Learning with Discrete Visual Speech Units
Jan 18, 2024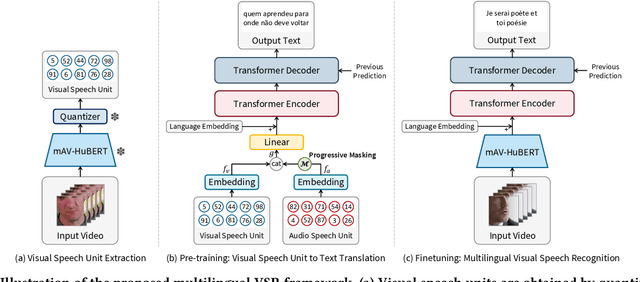
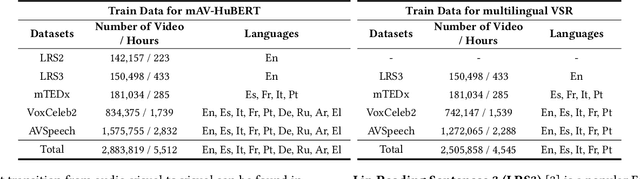
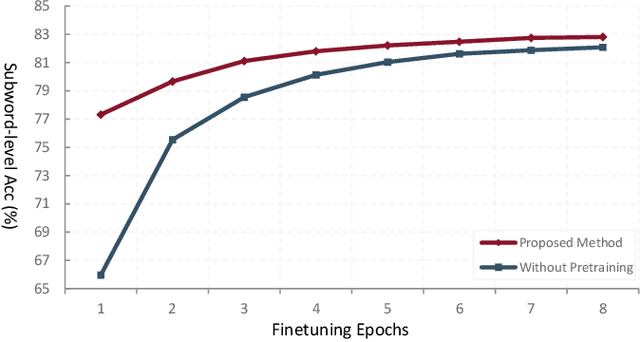
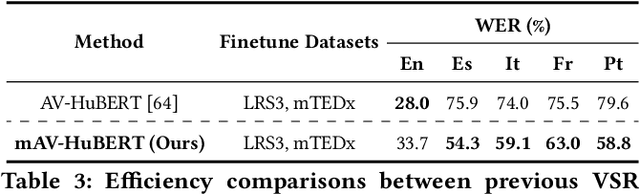
This paper explores sentence-level Multilingual Visual Speech Recognition with a single model for the first time. As the massive multilingual modeling of visual data requires huge computational costs, we propose a novel strategy, processing with visual speech units. Motivated by the recent success of the audio speech unit, the proposed visual speech unit is obtained by discretizing the visual speech features extracted from the self-supervised visual speech model. To correctly capture multilingual visual speech, we first train the self-supervised visual speech model on 5,512 hours of multilingual audio-visual data. Through analysis, we verify that the visual speech units mainly contain viseme information while suppressing non-linguistic information. By using the visual speech units as the inputs of our system, we pre-train the model to predict corresponding text outputs on massive multilingual data constructed by merging several VSR databases. As both the inputs and outputs are discrete, we can greatly improve the training efficiency compared to the standard VSR training. Specifically, the input data size is reduced to 0.016% of the original video inputs. In order to complement the insufficient visual information in speech recognition, we apply curriculum learning where the inputs of the system begin with audio-visual speech units and gradually change to visual speech units. After pre-training, the model is finetuned on continuous features. We set new state-of-the-art multilingual VSR performances by achieving comparable performances to the previous language-specific VSR models, with a single trained model.
Visual Speech Recognition for Low-resource Languages with Automatic Labels From Whisper Model
Sep 15, 2023


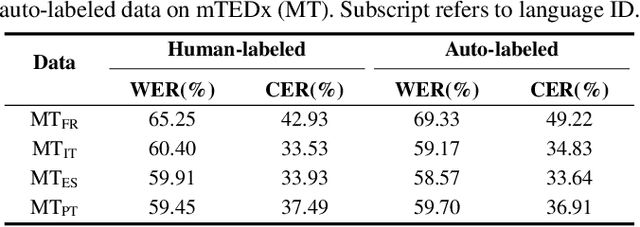
This paper proposes a powerful Visual Speech Recognition (VSR) method for multiple languages, especially for low-resource languages that have a limited number of labeled data. Different from previous methods that tried to improve the VSR performance for the target language by using knowledge learned from other languages, we explore whether we can increase the amount of training data itself for the different languages without human intervention. To this end, we employ a Whisper model which can conduct both language identification and audio-based speech recognition. It serves to filter data of the desired languages and transcribe labels from the unannotated, multilingual audio-visual data pool. By comparing the performances of VSR models trained on automatic labels and the human-annotated labels, we show that we can achieve similar VSR performance to that of human-annotated labels even without utilizing human annotations. Through the automated labeling process, we label large-scale unlabeled multilingual databases, VoxCeleb2 and AVSpeech, producing 1,002 hours of data for four low VSR resource languages, French, Italian, Spanish, and Portuguese. With the automatic labels, we achieve new state-of-the-art performance on mTEDx in four languages, significantly surpassing the previous methods. The automatic labels are available online: https://github.com/JeongHun0716/Visual-Speech-Recognition-for-Low-Resource-Languages