 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Practical and Efficient Image-to-Speech Captioning with Vision-Language Pre-training and Multi-modal Tokens
Paper and Code
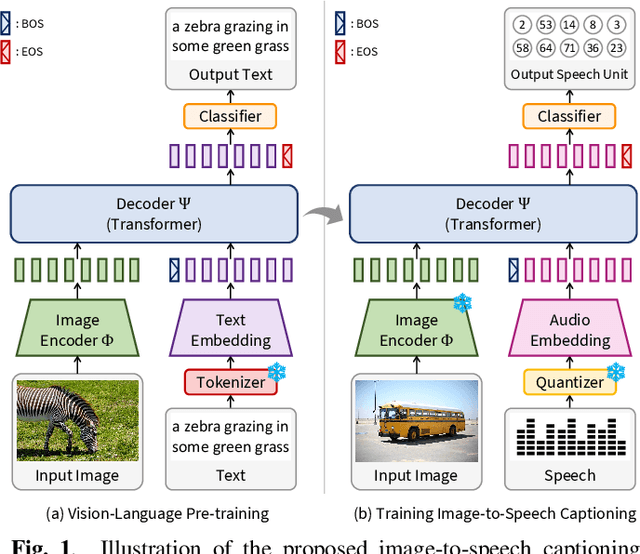

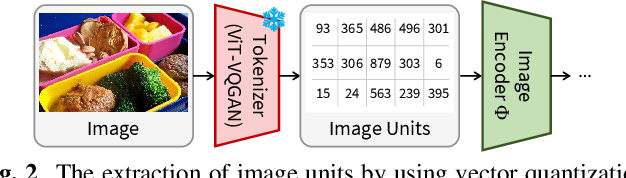

In this paper, we propose methods to build a powerful and efficient Image-to-Speech captioning (Im2Sp) model. To this end, we start with importing the rich knowledge related to image comprehension and language modeling from a large-scale pre-trained vision-language model into Im2Sp. We set the output of the proposed Im2Sp as discretized speech units, i.e., the quantized speech features of a self-supervised speech model. The speech units mainly contain linguistic information while suppressing other characteristics of speech. This allows us to incorporate the language modeling capability of the pre-trained vision-language model into the spoken language modeling of Im2Sp. With the vision-language pre-training strategy, we set new state-of-the-art Im2Sp performances on two widely used benchmark databases, COCO and Flickr8k. Then, we further improve the efficiency of the Im2Sp model. Similar to the speech unit case, we convert the original image into image units, which are derived through vector quantization of the raw image. With these image units, we can drastically reduce the required data storage for saving image data to just 0.8% when compared to the original image data in terms of bits. Demo page: https://ms-dot-k.github.io/Image-to-Speech-Captioning.