 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLightNobel: Improving Sequence Length Limitation in Protein Structure Prediction Model via Adaptive Activation Quantization
May 09, 2025


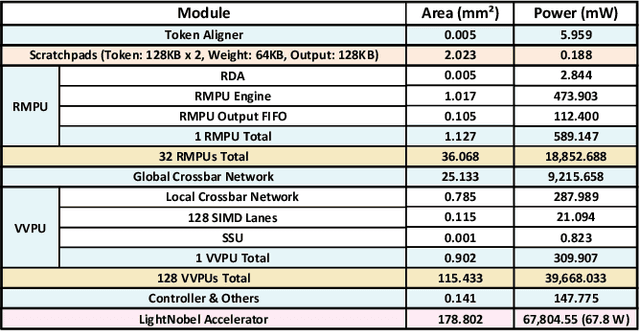
Recent advances in Protein Structure Prediction Models (PPMs), such as AlphaFold2 and ESMFold, have revolutionized computational biology by achieving unprecedented accuracy in predicting three-dimensional protein folding structures. However, these models face significant scalability challenges, particularly when processing proteins with long amino acid sequences (e.g., sequence length > 1,000). The primary bottleneck that arises from the exponential growth in activation sizes is driven by the unique data structure in PPM, which introduces an additional dimension that leads to substantial memory and computational demands. These limitations have hindered the effective scaling of PPM for real-world applications, such as analyzing large proteins or complex multimers with critical biological and pharmaceutical relevance. In this paper, we present LightNobel, the first hardware-software co-designed accelerator developed to overcome scalability limitations on the sequence length in PPM. At the software level, we propose Token-wise Adaptive Activation Quantization (AAQ), which leverages unique token-wise characteristics, such as distogram patterns in PPM activations, to enable fine-grained quantization techniques without compromising accuracy. At the hardware level, LightNobel integrates the multi-precision reconfigurable matrix processing unit (RMPU) and versatile vector processing unit (VVPU) to enable the efficient execution of AAQ. Through these innovations, LightNobel achieves up to 8.44x, 8.41x speedup and 37.29x, 43.35x higher power efficiency over the latest NVIDIA A100 and H100 GPUs, respectively, while maintaining negligible accuracy loss. It also reduces the peak memory requirement up to 120.05x in PPM, enabling scalable processing for proteins with long sequences.
Personalized Lip Reading: Adapting to Your Unique Lip Movements with Vision and Language
Sep 02, 2024Lip reading aims to predict spoken language by analyzing lip movements. Despite advancements in lip reading technologies, performance degrades when models are applied to unseen speakers due to their sensitivity to variations in visual information such as lip appearances. To address this challenge, speaker adaptive lip reading technologies have advanced by focusing on effectively adapting a lip reading model to target speakers in the visual modality. The effectiveness of adapting language information, such as vocabulary choice, of the target speaker has not been explored in the previous works. Moreover, existing datasets for speaker adaptation have limited vocabulary size and pose variations, limiting the validation of previous speaker-adaptive methods in real-world scenarios. To address these issues, we propose a novel speaker-adaptive lip reading method that adapts a pre-trained model to target speakers at both vision and language levels. Specifically, we integrate prompt tuning and the LoRA approach, applying them to a pre-trained lip reading model to effectively adapt the model to target speakers. In addition, to validate its effectiveness in real-world scenarios, we introduce a new dataset, VoxLRS-SA, derived from VoxCeleb2 and LRS3. It contains a vocabulary of approximately 100K words, offers diverse pose variations, and enables the validation of adaptation methods in wild, sentence-level lip reading for the first time. Through various experiments, we demonstrate that the existing speaker-adaptive method also improves performance in the wild at the sentence level. Moreover, with the proposed adaptation method, we show that the proposed method achieves larger improvements when applied to the target speaker, compared to the previous works.
Persona Extraction Through Semantic Similarity for Emotional Support Conversation Generation
Mar 07, 2024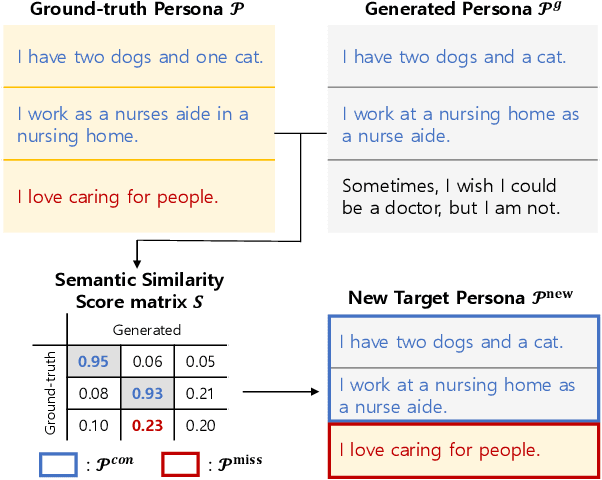


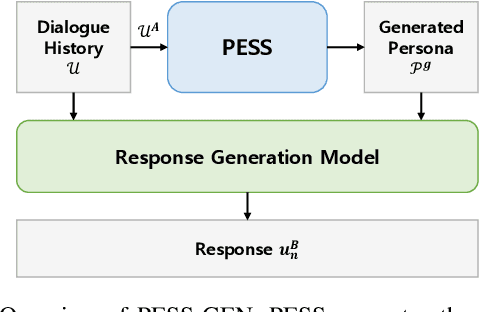
Providing emotional support through dialogue systems is becoming increasingly important in today's world, as it can support both mental health and social interactions in many conversation scenarios. Previous works have shown that using persona is effective for generating empathetic and supportive responses. They have often relied on pre-provided persona rather than inferring them during conversations. However, it is not always possible to obtain a user persona before the conversation begins. To address this challenge, we propose PESS (Persona Extraction through Semantic Similarity), a novel framework that can automatically infer informative and consistent persona from dialogues. We devise completeness loss and consistency loss based on semantic similarity scores. The completeness loss encourages the model to generate missing persona information, and the consistency loss guides the model to distinguish between consistent and inconsistent persona. Our experimental results demonstrate that high-quality persona information inferred by PESS is effective in generating emotionally supportive responses.
Where Visual Speech Meets Language: VSP-LLM Framework for Efficient and Context-Aware Visual Speech Processing
Feb 23, 2024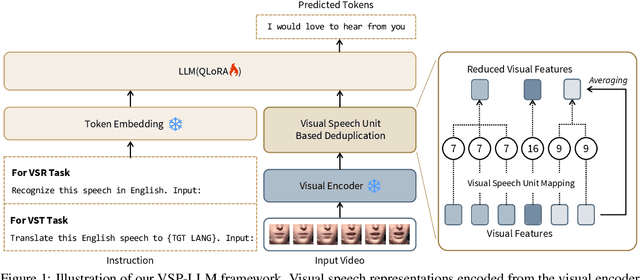
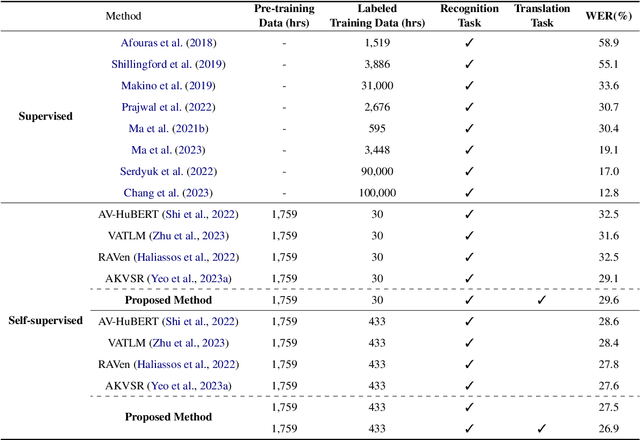

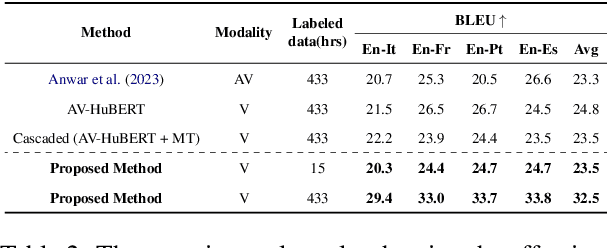
In visual speech processing, context modeling capability is one of the most important requirements due to the ambiguous nature of lip movements. For example, homophenes, words that share identical lip movements but produce different sounds, can be distinguished by considering the context. In this paper, we propose a novel framework, namely Visual Speech Processing incorporated with LLMs (VSP-LLM), to maximize the context modeling ability by bringing the overwhelming power of LLMs. Specifically, VSP-LLM is designed to perform multi-tasks of visual speech recognition and translation, where the given instructions control the type of task. The input video is mapped to the input latent space of a LLM by employing a self-supervised visual speech model. Focused on the fact that there is redundant information in input frames, we propose a novel deduplication method that reduces the embedded visual features by employing visual speech units. Through the proposed deduplication and Low Rank Adaptors (LoRA), VSP-LLM can be trained in a computationally efficient manner. In the translation dataset, the MuAViC benchmark, we demonstrate that VSP-LLM can more effectively recognize and translate lip movements with just 15 hours of labeled data, compared to the recent translation model trained with 433 hours of labeld data.