 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeORBIS: Output-Guided Token Reduction with Distribution-Aware Matching for Video Diffusion Acceleration
May 21, 2026Diffusion Transformer (DiT) has emerged as a powerful model architecture for generating high-quality images and videos. In the case of video DiT, 3D Spatio-Temporal Attention increases token length in proportion to the number of frames, sharply increasing computational cost. Token reduction methods mitigate this cost by exploiting spatial redundancy, but existing approaches rely on inaccurate similarity estimates and lightweight matching algorithms, resulting in poor matching quality and only marginal acceleration. To overcome these limitations, we propose ORBIS, an SW-HW co-designed accelerator for video DiT. ORBIS leverages the output activation from the previous timestep to obtain more accurate inter-token similarity, substantially improving matching quality and enabling a higher token reduction ratio. We further introduce a Distribution-Aware Token Matching (DATM) algorithm that captures global token distribution and explicitly minimizes token-pair loss for additional gains. To fully hide DATM latency, we design specialized, deeply pipelined hardware and minimize its hardware cost through quantization, occupying only 2.4% of total area with negligible accuracy loss. Extensive experiments show that ORBIS achieves about 2x higher token reduction ratio than the state-of-the-art approach, AsymRnR, while delivering up to 4.5x speedup and 79.3% energy reduction compared to an NVIDIA A100 GPU.
Rethinking Token Reduction for Diffusion Models via Output-Similarity-Awareness
May 21, 2026Diffusion Transformers (DiTs) achieve superior image generation quality but suffer from quadratic computational complexity relative to token count. While various token reduction (TR) methods have been proposed to mitigate this cost, they overlook the primary objective of generative models: minimizing recovery error, which requires reflecting output token similarity. They rely solely on input token similarity inherited from reduction-only ViT paradigms, leading to a fundamental misalignment with this objective. To bridge this gap, we propose DiTo, a novel TR paradigm that shifts the focus toward output-centric token reduction. Based on the observation that output token similarity is consistently preserved across adjacent timesteps, DiTo utilizes prior-step similarities as an effective proxy to establish token correspondences at a Matching timestep, which are then reused across multiple subsequent Reduction timesteps. To optimize this interleaved scheduling, we propose Pair Match Ratio (PMR)-guided Interval Scheduling to determine the optimal matching frequency. Furthermore, to mitigate localized approximation errors and resulting blocking artifacts caused by repeated reuse, we propose Frequency-aware Token Matching by incorporating a selection-frequency penalty. Extensive experiments demonstrate that DiTo consistently outperforms existing TR methods with 1.6-3.9 dB higher PSNR at comparable speedups, achieving a superior Pareto frontier.
POP: Online Structural Pruning Enables Efficient Inference of Large Foundation Models
Feb 06, 2026Large foundation models (LFMs) achieve strong performance through scaling, yet current structural pruning methods derive fixed pruning decisions during inference, overlooking sparsity patterns that emerge in the autoregressive token generation. In this paper, we propose POP (Partition-guided Online Pruning), an efficient online structural pruning framework that enables context-conditioned dynamic pruning with minimal computational overhead. POP partitions model channels into retained, candidate, and pruned regions, where prefilling defines a coarse pruning partition, and the decoding stage generates a fine-grained mask within the candidate region, avoiding full-channel re-evaluation. The coarse pruning partition preserves consistently important weights, while the fine-grained masking provides context-conditioned variation during decoding. Moreover, POP is a lightweight, plug-and-play method that requires no preprocessing, including offline calibration, retraining, or learning predictors. Extensive evaluations across diverse LFMs, including large language models (LLMs), mixture-of-experts models (MoEs), and vision-language models (VLMs), demonstrate that POP consistently delivers higher accuracy than existing pruning approaches while incurring smaller computational overhead and minimizing inference latency.
V-Rex: Real-Time Streaming Video LLM Acceleration via Dynamic KV Cache Retrieval
Dec 24, 2025


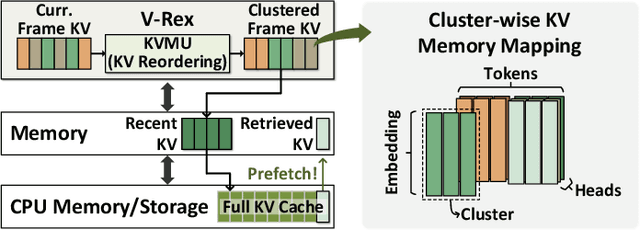
Streaming video large language models (LLMs) are increasingly used for real-time multimodal tasks such as video captioning, question answering, conversational agents, and augmented reality. However, these models face fundamental memory and computational challenges because their key-value (KV) caches grow substantially with continuous streaming video input. This process requires an iterative prefill stage, which is a unique feature of streaming video LLMs. Due to its iterative prefill stage, it suffers from significant limitations, including extensive computation, substantial data transfer, and degradation in accuracy. Crucially, this issue is exacerbated for edge deployment, which is the primary target for these models. In this work, we propose V-Rex, the first software-hardware co-designed accelerator that comprehensively addresses both algorithmic and hardware bottlenecks in streaming video LLM inference. At its core, V-Rex introduces ReSV, a training-free dynamic KV cache retrieval algorithm. ReSV exploits temporal and spatial similarity-based token clustering to reduce excessive KV cache memory across video frames. To fully realize these algorithmic benefits, V-Rex offers a compact, low-latency hardware accelerator with a dynamic KV cache retrieval engine (DRE), featuring bit-level and early-exit based computing units. V-Rex achieves unprecedented real-time of 3.9-8.3 FPS and energy-efficient streaming video LLM inference on edge deployment with negligible accuracy loss. While DRE only accounts for 2.2% power and 2.0% area, the system delivers 1.9-19.7x speedup and 3.1-18.5x energy efficiency improvements over AGX Orin GPU. This work is the first to comprehensively tackle KV cache retrieval across algorithms and hardware, enabling real-time streaming video LLM inference on resource-constrained edge devices.
AoP-SAM: Automation of Prompts for Efficient Segmentation
May 17, 2025
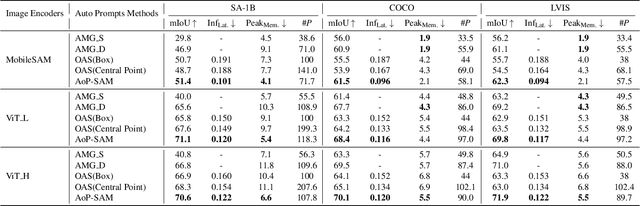
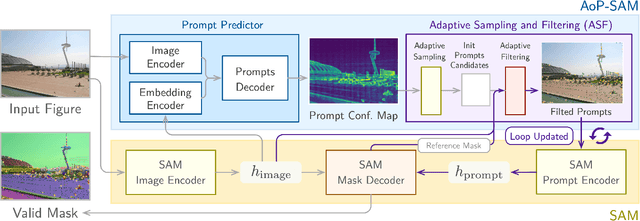

The Segment Anything Model (SAM) is a powerful foundation model for image segmentation, showing robust zero-shot generalization through prompt engineering. However, relying on manual prompts is impractical for real-world applications, particularly in scenarios where rapid prompt provision and resource efficiency are crucial. In this paper, we propose the Automation of Prompts for SAM (AoP-SAM), a novel approach that learns to generate essential prompts in optimal locations automatically. AoP-SAM enhances SAM's efficiency and usability by eliminating manual input, making it better suited for real-world tasks. Our approach employs a lightweight yet efficient Prompt Predictor model that detects key entities across images and identifies the optimal regions for placing prompt candidates. This method leverages SAM's image embeddings, preserving its zero-shot generalization capabilities without requiring fine-tuning. Additionally, we introduce a test-time instance-level Adaptive Sampling and Filtering mechanism that generates prompts in a coarse-to-fine manner. This notably enhances both prompt and mask generation efficiency by reducing computational overhead and minimizing redundant mask refinements. Evaluations of three datasets demonstrate that AoP-SAM substantially improves both prompt generation efficiency and mask generation accuracy, making SAM more effective for automated segmentation tasks.
LightNobel: Improving Sequence Length Limitation in Protein Structure Prediction Model via Adaptive Activation Quantization
May 09, 2025


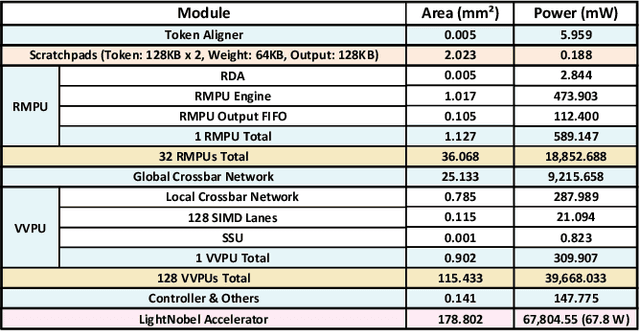
Recent advances in Protein Structure Prediction Models (PPMs), such as AlphaFold2 and ESMFold, have revolutionized computational biology by achieving unprecedented accuracy in predicting three-dimensional protein folding structures. However, these models face significant scalability challenges, particularly when processing proteins with long amino acid sequences (e.g., sequence length > 1,000). The primary bottleneck that arises from the exponential growth in activation sizes is driven by the unique data structure in PPM, which introduces an additional dimension that leads to substantial memory and computational demands. These limitations have hindered the effective scaling of PPM for real-world applications, such as analyzing large proteins or complex multimers with critical biological and pharmaceutical relevance. In this paper, we present LightNobel, the first hardware-software co-designed accelerator developed to overcome scalability limitations on the sequence length in PPM. At the software level, we propose Token-wise Adaptive Activation Quantization (AAQ), which leverages unique token-wise characteristics, such as distogram patterns in PPM activations, to enable fine-grained quantization techniques without compromising accuracy. At the hardware level, LightNobel integrates the multi-precision reconfigurable matrix processing unit (RMPU) and versatile vector processing unit (VVPU) to enable the efficient execution of AAQ. Through these innovations, LightNobel achieves up to 8.44x, 8.41x speedup and 37.29x, 43.35x higher power efficiency over the latest NVIDIA A100 and H100 GPUs, respectively, while maintaining negligible accuracy loss. It also reduces the peak memory requirement up to 120.05x in PPM, enabling scalable processing for proteins with long sequences.
SCRec: A Scalable Computational Storage System with Statistical Sharding and Tensor-train Decomposition for Recommendation Models
Apr 01, 2025



Deep Learning Recommendation Models (DLRMs) play a crucial role in delivering personalized content across web applications such as social networking and video streaming. However, with improvements in performance, the parameter size of DLRMs has grown to terabyte (TB) scales, accompanied by memory bandwidth demands exceeding TB/s levels. Furthermore, the workload intensity within the model varies based on the target mechanism, making it difficult to build an optimized recommendation system. In this paper, we propose SCRec, a scalable computational storage recommendation system that can handle TB-scale industrial DLRMs while guaranteeing high bandwidth requirements. SCRec utilizes a software framework that features a mixed-integer programming (MIP)-based cost model, efficiently fetching data based on data access patterns and adaptively configuring memory-centric and compute-centric cores. Additionally, SCRec integrates hardware acceleration cores to enhance DLRM computations, particularly allowing for the high-performance reconstruction of approximated embedding vectors from extremely compressed tensor-train (TT) format. By combining its software framework and hardware accelerators, while eliminating data communication overhead by being implemented on a single server, SCRec achieves substantial improvements in DLRM inference performance. It delivers up to 55.77$\times$ speedup compared to a CPU-DRAM system with no loss in accuracy and up to 13.35$\times$ energy efficiency gains over a multi-GPU system.
Oaken: Fast and Efficient LLM Serving with Online-Offline Hybrid KV Cache Quantization
Mar 24, 2025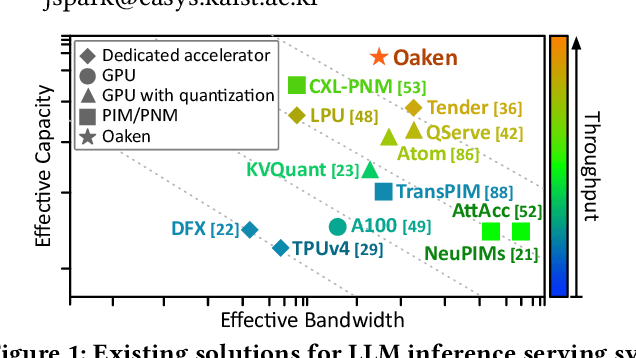

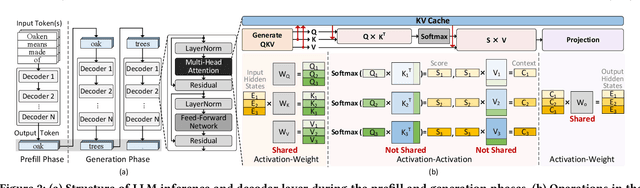
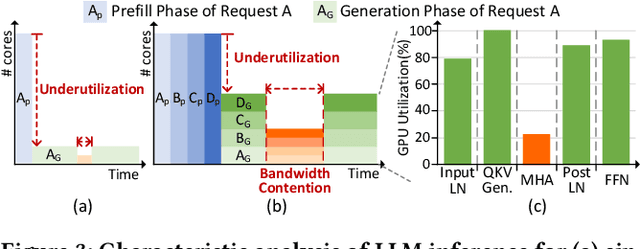
Modern Large Language Model serving system batches multiple requests to achieve high throughput, while batching attention operations is challenging, rendering memory bandwidth a critical bottleneck. The community relies on high-end GPUs with multiple high-bandwidth memory channels. Unfortunately, HBM's high bandwidth often comes at the expense of limited memory capacity, which reduces core utilization and increases costs. Recent advancements enabling longer contexts for LLMs have substantially increased the key-value cache size, further intensifying the pressures on memory capacity. The literature has explored KV cache quantization techniques, which commonly use low bitwidth for most values, selectively using higher bitwidth for outlier values. While this approach helps achieve high accuracy and low bitwidth simultaneously, it comes with the limitation that cost for online outlier detection is excessively high, negating the advantages. We propose Oaken, an acceleration solution that achieves high accuracy and high performance simultaneously through co-designing algorithm and hardware. To effectively find a sweet spot in the accuracy-performance trade-off space of KV cache quantization, Oaken employs an online-offline hybrid approach, setting outlier thresholds offline, which are then used to determine the quantization scale online. To translate the proposed algorithmic technique into tangible performance gains, Oaken also comes with custom quantization engines and memory management units that can be integrated with any LLM accelerators. We built an Oaken accelerator on top of an LLM accelerator, LPU, and conducted a comprehensive evaluation. Our experiments show that for a batch size of 256, Oaken achieves up to 1.58x throughput improvement over NVIDIA A100 GPU, incurring a minimal accuracy loss of only 0.54\% on average, compared to state-of-the-art KV cache quantization techniques.
Training-Free Graph Filtering via Multimodal Feature Refinement for Extremely Fast Multimodal Recommendation
Mar 06, 2025

Multimodal recommender systems improve the performance of canonical recommender systems with no item features by utilizing diverse content types such as text, images, and videos, while alleviating inherent sparsity of user-item interactions and accelerating user engagement. However, current neural network-based models often incur significant computational overhead due to the complex training process required to learn and integrate information from multiple modalities. To overcome this limitation, we propose MultiModal-Graph Filtering (MM-GF), a training-free method based on the notion of graph filtering (GF) for efficient and accurate multimodal recommendations. Specifically, MM-GF first constructs multiple similarity graphs through nontrivial multimodal feature refinement such as robust scaling and vector shifting by addressing the heterogeneous characteristics across modalities. Then, MM-GF optimally fuses multimodal information using linear low-pass filters across different modalities. Extensive experiments on real-world benchmark datasets demonstrate that MM-GF not only improves recommendation accuracy by up to 13.35% compared to the best competitor but also dramatically reduces computational costs by achieving the runtime of less than 10 seconds.
EXION: Exploiting Inter- and Intra-Iteration Output Sparsity for Diffusion Models
Jan 10, 2025



Over the past few years, diffusion models have emerged as novel AI solutions, generating diverse multi-modal outputs from text prompts. Despite their capabilities, they face challenges in computing, such as excessive latency and energy consumption due to their iterative architecture. Although prior works specialized in transformer acceleration can be applied, the iterative nature of diffusion models remains unresolved. In this paper, we present EXION, the first SW-HW co-designed diffusion accelerator that solves the computation challenges by exploiting the unique inter- and intra-iteration output sparsity in diffusion models. To this end, we propose two SW-level optimizations. First, we introduce the FFN-Reuse algorithm that identifies and skips redundant computations in FFN layers across different iterations (inter-iteration sparsity). Second, we use a modified eager prediction method that employs two-step leading-one detection to accurately predict the attention score, skipping unnecessary computations within an iteration (intra-iteration sparsity). We also introduce a novel data compaction mechanism named ConMerge, which can enhance HW utilization by condensing and merging sparse matrices into compact forms. Finally, it has a dedicated HW architecture that supports the above sparsity-inducing algorithms, translating high output sparsity into improved energy efficiency and performance. To verify the feasibility of the EXION, we first demonstrate that it has no impact on accuracy in various types of multi-modal diffusion models. We then instantiate EXION in both server- and edge-level settings and compare its performance against GPUs with similar specifications. Our evaluation shows that EXION achieves dramatic improvements in performance and energy efficiency by 3.2-379.3x and 45.1-3067.6x compared to a server GPU and by 42.6-1090.9x and 196.9-4668.2x compared to an edge GPU.