 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining-Free Graph Filtering via Multimodal Feature Refinement for Extremely Fast Multimodal Recommendation
Mar 06, 2025

Multimodal recommender systems improve the performance of canonical recommender systems with no item features by utilizing diverse content types such as text, images, and videos, while alleviating inherent sparsity of user-item interactions and accelerating user engagement. However, current neural network-based models often incur significant computational overhead due to the complex training process required to learn and integrate information from multiple modalities. To overcome this limitation, we propose MultiModal-Graph Filtering (MM-GF), a training-free method based on the notion of graph filtering (GF) for efficient and accurate multimodal recommendations. Specifically, MM-GF first constructs multiple similarity graphs through nontrivial multimodal feature refinement such as robust scaling and vector shifting by addressing the heterogeneous characteristics across modalities. Then, MM-GF optimally fuses multimodal information using linear low-pass filters across different modalities. Extensive experiments on real-world benchmark datasets demonstrate that MM-GF not only improves recommendation accuracy by up to 13.35% compared to the best competitor but also dramatically reduces computational costs by achieving the runtime of less than 10 seconds.
Leveraging Member-Group Relations via Multi-View Graph Filtering for Effective Group Recommendation
Feb 13, 2025Group recommendation aims at providing optimized recommendations tailored to diverse groups, enabling groups to enjoy appropriate items. On the other hand, most existing group recommendation methods are built upon deep neural network (DNN) architectures designed to capture the intricate relationships between member-level and group-level interactions. While these DNN-based approaches have proven their effectiveness, they require complex and expensive training procedures to incorporate group-level interactions in addition to member-level interactions. To overcome such limitations, we introduce Group-GF, a new approach for extremely fast recommendations of items to each group via multi-view graph filtering (GF) that offers a holistic view of complex member-group dynamics, without the need for costly model training. Specifically, in Group-GF, we first construct three item similarity graphs manifesting different viewpoints for GF. Then, we discover a distinct polynomial graph filter for each similarity graph and judiciously aggregate the three graph filters. Extensive experiments demonstrate the effectiveness of Group-GF in terms of significantly reducing runtime and achieving state-of-the-art recommendation accuracy.
Criteria-Aware Graph Filtering: Extremely Fast Yet Accurate Multi-Criteria Recommendation
Feb 13, 2025Multi-criteria (MC) recommender systems, which utilize MC rating information for recommendation, are increasingly widespread in various e-commerce domains. However, the MC recommendation using training-based collaborative filtering, requiring consideration of multiple ratings compared to single-criterion counterparts, often poses practical challenges in achieving state-of-the-art performance along with scalable model training. To solve this problem, we propose CA-GF, a training-free MC recommendation method, which is built upon criteria-aware graph filtering for efficient yet accurate MC recommendations. Specifically, first, we construct an item-item similarity graph using an MC user-expansion graph. Next, we design CA-GF composed of the following key components, including 1) criterion-specific graph filtering where the optimal filter for each criterion is found using various types of polynomial low-pass filters and 2) criteria preference-infused aggregation where the smoothed signals from each criterion are aggregated. We demonstrate that CA-GF is (a) efficient: providing the computational efficiency, offering the extremely fast runtime of less than 0.2 seconds even on the largest benchmark dataset, (b) accurate: outperforming benchmark MC recommendation methods, achieving substantial accuracy gains up to 24% compared to the best competitor, and (c) interpretable: providing interpretations for the contribution of each criterion to the model prediction based on visualizations.
LAMP: Learnable Meta-Path Guided Adversarial Contrastive Learning for Heterogeneous Graphs
Sep 10, 2024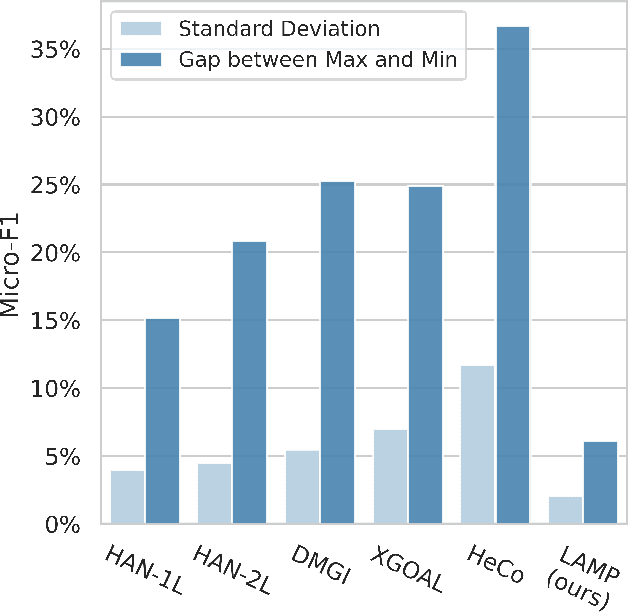
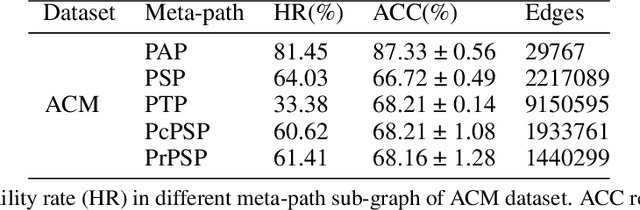
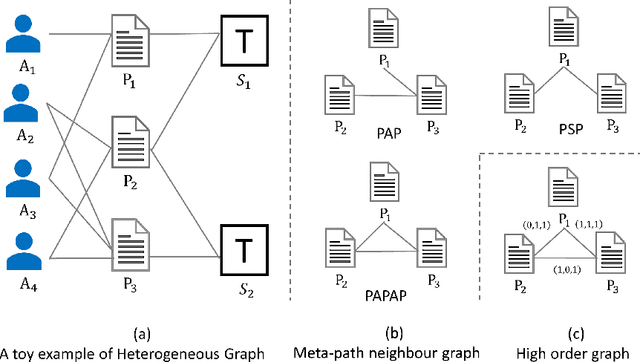
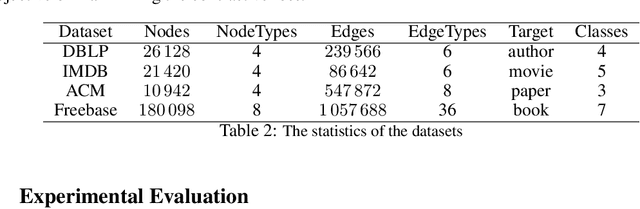
Heterogeneous graph neural networks (HGNNs) have significantly propelled the information retrieval (IR) field. Still, the effectiveness of HGNNs heavily relies on high-quality labels, which are often expensive to acquire. This challenge has shifted attention towards Heterogeneous Graph Contrastive Learning (HGCL), which usually requires pre-defined meta-paths. However, our findings reveal that meta-path combinations significantly affect performance in unsupervised settings, an aspect often overlooked in current literature. Existing HGCL methods have considerable variability in outcomes across different meta-path combinations, thereby challenging the optimization process to achieve consistent and high performance. In response, we introduce \textsf{LAMP} (\underline{\textbf{L}}earn\underline{\textbf{A}}ble \underline{\textbf{M}}eta-\underline{\textbf{P}}ath), a novel adversarial contrastive learning approach that integrates various meta-path sub-graphs into a unified and stable structure, leveraging the overlap among these sub-graphs. To address the denseness of this integrated sub-graph, we propose an adversarial training strategy for edge pruning, maintaining sparsity to enhance model performance and robustness. \textsf{LAMP} aims to maximize the difference between meta-path and network schema views for guiding contrastive learning to capture the most meaningful information. Our extensive experimental study conducted on four diverse datasets from the Heterogeneous Graph Benchmark (HGB) demonstrates that \textsf{LAMP} significantly outperforms existing state-of-the-art unsupervised models in terms of accuracy and robustness.
Turbo-CF: Matrix Decomposition-Free Graph Filtering for Fast Recommendation
Apr 22, 2024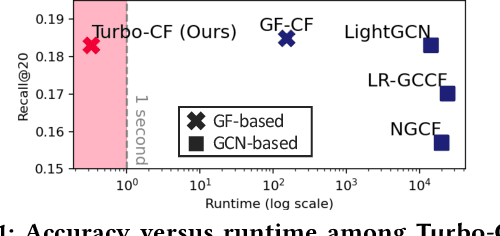
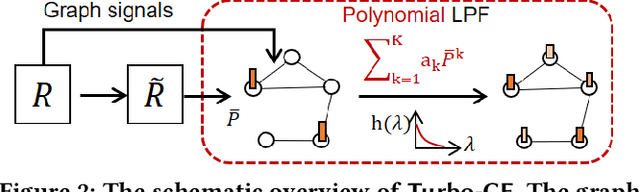

A series of graph filtering (GF)-based collaborative filtering (CF) showcases state-of-the-art performance on the recommendation accuracy by using a low-pass filter (LPF) without a training process. However, conventional GF-based CF approaches mostly perform matrix decomposition on the item-item similarity graph to realize the ideal LPF, which results in a non-trivial computational cost and thus makes them less practical in scenarios where rapid recommendations are essential. In this paper, we propose Turbo-CF, a GF-based CF method that is both training-free and matrix decomposition-free. Turbo-CF employs a polynomial graph filter to circumvent the issue of expensive matrix decompositions, enabling us to make full use of modern computer hardware components (i.e., GPU). Specifically, Turbo-CF first constructs an item-item similarity graph whose edge weights are effectively regulated. Then, our own polynomial LPFs are designed to retain only low-frequency signals without explicit matrix decompositions. We demonstrate that Turbo-CF is extremely fast yet accurate, achieving a runtime of less than 1 second on real-world benchmark datasets while achieving recommendation accuracies comparable to best competitors.
Collaborative Filtering Based on Diffusion Models: Unveiling the Potential of High-Order Connectivity
Apr 22, 2024



A recent study has shown that diffusion models are well-suited for modeling the generative process of user-item interactions in recommender systems due to their denoising nature. However, existing diffusion model-based recommender systems do not explicitly leverage high-order connectivities that contain crucial collaborative signals for accurate recommendations. Addressing this gap, we propose CF-Diff, a new diffusion model-based collaborative filtering (CF) method, which is capable of making full use of collaborative signals along with multi-hop neighbors. Specifically, the forward-diffusion process adds random noise to user-item interactions, while the reverse-denoising process accommodates our own learning model, named cross-attention-guided multi-hop autoencoder (CAM-AE), to gradually recover the original user-item interactions. CAM-AE consists of two core modules: 1) the attention-aided AE module, responsible for precisely learning latent representations of user-item interactions while preserving the model's complexity at manageable levels, and 2) the multi-hop cross-attention module, which judiciously harnesses high-order connectivity information to capture enhanced collaborative signals. Through comprehensive experiments on three real-world datasets, we demonstrate that CF-Diff is (a) Superior: outperforming benchmark recommendation methods, achieving remarkable gains up to 7.29% compared to the best competitor, (b) Theoretically-validated: reducing computations while ensuring that the embeddings generated by our model closely approximate those from the original cross-attention, and (c) Scalable: proving the computational efficiency that scales linearly with the number of users or items.
Criteria Tell You More than Ratings: Criteria Preference-Aware Light Graph Convolution for Effective Multi-Criteria Recommendation
Jun 06, 2023



The multi-criteria (MC) recommender system, which leverages MC rating information in a wide range of e-commerce areas, is ubiquitous nowadays. Surprisingly, although graph neural networks (GNNs) have been widely applied to develop various recommender systems due to GNN's high expressive capability in learning graph representations, it has been still unexplored how to design MC recommender systems with GNNs. In light of this, we make the first attempt towards designing a GNN-aided MC recommender system. Specifically, rather than straightforwardly adopting existing GNN-based recommendation methods, we devise a novel criteria preference-aware light graph convolution CPA-LGC method, which is capable of precisely capturing the criteria preference of users as well as the collaborative signal in complex high-order connectivities. To this end, we first construct an MC expansion graph that transforms user--item MC ratings into an expanded bipartite graph to potentially learn from the collaborative signal in MC ratings. Next, to strengthen the capability of criteria preference awareness, CPA-LGC incorporates newly characterized embeddings, including user-specific criteria-preference embeddings and item-specific criterion embeddings, into our graph convolution model. Through comprehensive evaluations using four real-world datasets, we demonstrate (a) the superiority over benchmark MC recommendation methods and benchmark recommendation methods using GNNs with tremendous gains, (b) the effectiveness of core components in CPA-LGC, and (c) the computational efficiency.
Node Feature Augmentation Vitaminizes Network Alignment
Apr 25, 2023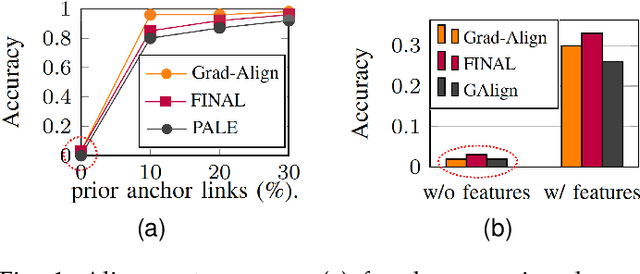
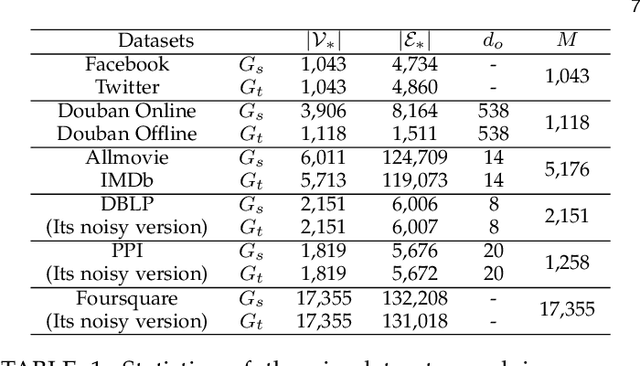
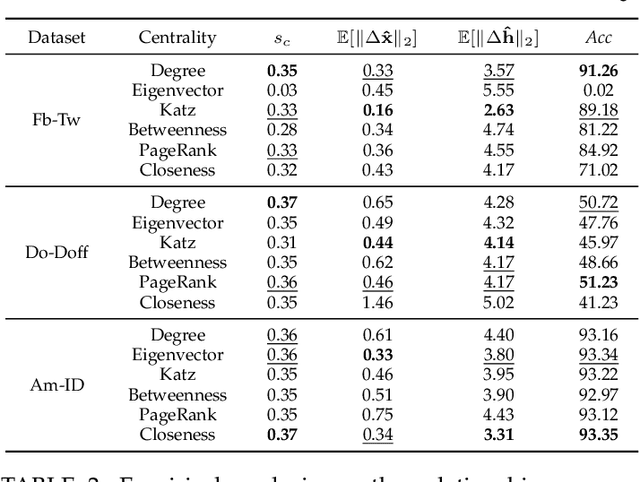
Network alignment (NA) is the task of discovering node correspondences across multiple networks using topological and/or feature information of given networks. Although NA methods have achieved remarkable success in a myriad of scenarios, their effectiveness is not without additional information such as prior anchor links and/or node features, which may not always be available due to privacy concerns or access restrictions. To tackle this practical challenge, we propose Grad-Align+, a novel NA method built upon a recent state-of-the-art NA method, the so-called Grad-Align, that gradually discovers only a part of node pairs until all node pairs are found. In designing Grad-Align+, we account for how to augment node features in the sense of performing the NA task and how to design our NA method by maximally exploiting the augmented node features. To achieve this goal, we develop Grad-Align+ consisting of three key components: 1) centrality-based node feature augmentation (CNFA), 2) graph neural network (GNN)-aided embedding similarity calculation alongside the augmented node features, and 3) gradual NA with similarity calculation using the information of aligned cross-network neighbor-pairs (ACNs). Through comprehensive experiments, we demonstrate that Grad-Align+ exhibits (a) the superiority over benchmark NA methods by a large margin, (b) empirical validations as well as our theoretical findings to see the effectiveness of CNFA, (c) the influence of each component, (d) the robustness to network noises, and (e) the computational efficiency.
Grad-Align+: Empowering Gradual Network Alignment Using Attribute Augmentation
Aug 24, 2022
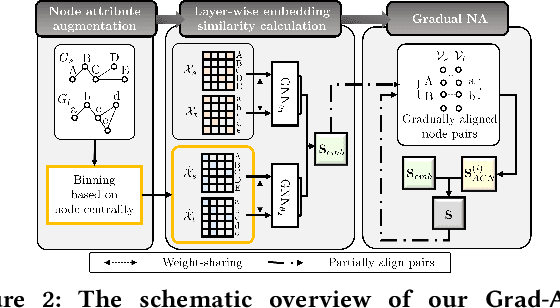
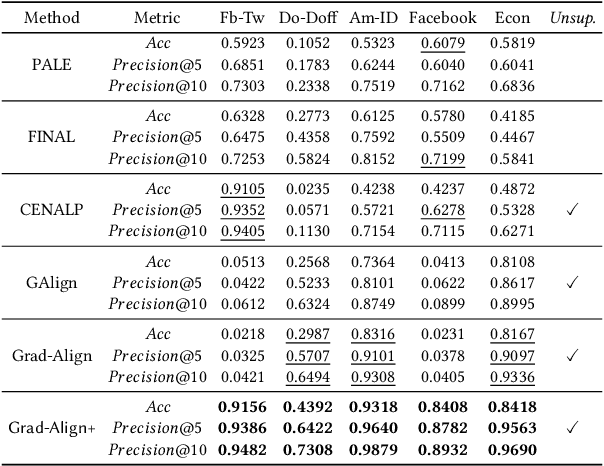
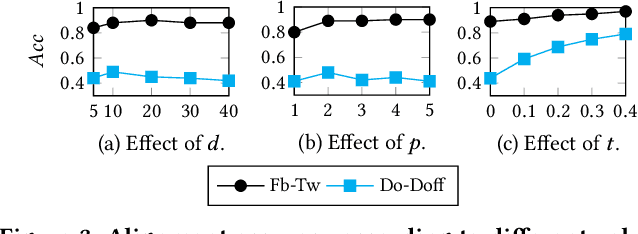
Network alignment (NA) is the task of discovering node correspondences across different networks. Although NA methods have achieved remarkable success in a myriad of scenarios, their satisfactory performance is not without prior anchor link information and/or node attributes, which may not always be available. In this paper, we propose Grad-Align+, a novel NA method using node attribute augmentation that is quite robust to the absence of such additional information. Grad-Align+ is built upon a recent state-of-the-art NA method, the so-called Grad-Align, that gradually discovers only a part of node pairs until all node pairs are found. Specifically, Grad-Align+ is composed of the following key components: 1) augmenting node attributes based on nodes' centrality measures, 2) calculating an embedding similarity matrix extracted from a graph neural network into which the augmented node attributes are fed, and 3) gradually discovering node pairs by calculating similarities between cross-network nodes with respect to the aligned cross-network neighbor-pair. Experimental results demonstrate that Grad-Align+ exhibits (a) superiority over benchmark NA methods, (b) empirical validation of our theoretical findings, and (c) the effectiveness of our attribute augmentation module.
Two-Stage Deep Anomaly Detection with Heterogeneous Time Series Data
Feb 10, 2022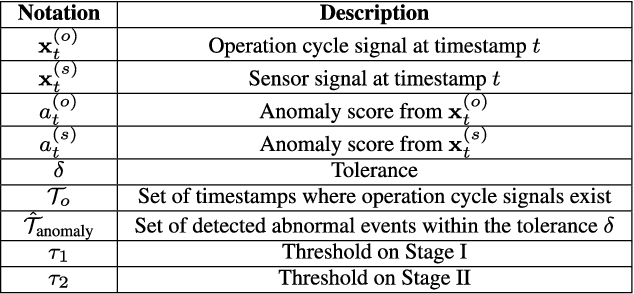



We introduce a data-driven anomaly detection framework using a manufacturing dataset collected from a factory assembly line. Given heterogeneous time series data consisting of operation cycle signals and sensor signals, we aim at discovering abnormal events. Motivated by our empirical findings that conventional single-stage benchmark approaches may not exhibit satisfactory performance under our challenging circumstances, we propose a two-stage deep anomaly detection (TDAD) framework in which two different unsupervised learning models are adopted depending on types of signals. In Stage I, we select anomaly candidates by using a model trained by operation cycle signals; in Stage II, we finally detect abnormal events out of the candidates by using another model, which is suitable for taking advantage of temporal continuity, trained by sensor signals. A distinguishable feature of our framework is that operation cycle signals are exploited first to find likely anomalous points, whereas sensor signals are leveraged to filter out unlikely anomalous points afterward. Our experiments comprehensively demonstrate the superiority over single-stage benchmark approaches, the model-agnostic property, and the robustness to difficult situations.