 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal-time prediction of breast cancer sites using deformation-aware graph neural network
Nov 17, 2025Early diagnosis of breast cancer is crucial, enabling the establishment of appropriate treatment plans and markedly enhancing patient prognosis. While direct magnetic resonance imaging-guided biopsy demonstrates promising performance in detecting cancer lesions, its practical application is limited by prolonged procedure times and high costs. To overcome these issues, an indirect MRI-guided biopsy that allows the procedure to be performed outside of the MRI room has been proposed, but it still faces challenges in creating an accurate real-time deformable breast model. In our study, we tackled this issue by developing a graph neural network (GNN)-based model capable of accurately predicting deformed breast cancer sites in real time during biopsy procedures. An individual-specific finite element (FE) model was developed by incorporating magnetic resonance (MR) image-derived structural information of the breast and tumor to simulate deformation behaviors. A GNN model was then employed, designed to process surface displacement and distance-based graph data, enabling accurate prediction of overall tissue displacement, including the deformation of the tumor region. The model was validated using phantom and real patient datasets, achieving an accuracy within 0.2 millimeters (mm) for cancer node displacement (RMSE) and a dice similarity coefficient (DSC) of 0.977 for spatial overlap with actual cancerous regions. Additionally, the model enabled real-time inference and achieved a speed-up of over 4,000 times in computational cost compared to conventional FE simulations. The proposed deformation-aware GNN model offers a promising solution for real-time tumor displacement prediction in breast biopsy, with high accuracy and real-time capability. Its integration with clinical procedures could significantly enhance the precision and efficiency of breast cancer diagnosis.
On the Feasibility of Fidelity$^-$ for Graph Pruning
Jun 17, 2024



As one of popular quantitative metrics to assess the quality of explanation of graph neural networks (GNNs), fidelity measures the output difference after removing unimportant parts of the input graph. Fidelity has been widely used due to its straightforward interpretation that the underlying model should produce similar predictions when features deemed unimportant from the explanation are removed. This raises a natural question: "Does fidelity induce a global (soft) mask for graph pruning?" To solve this, we aim to explore the potential of the fidelity measure to be used for graph pruning, eventually enhancing the GNN models for better efficiency. To this end, we propose Fidelity$^-$-inspired Pruning (FiP), an effective framework to construct global edge masks from local explanations. Our empirical observations using 7 edge attribution methods demonstrate that, surprisingly, general eXplainable AI methods outperform methods tailored to GNNs in terms of graph pruning performance.
Revisiting Attention Weights as Interpretations of Message-Passing Neural Networks
Jun 07, 2024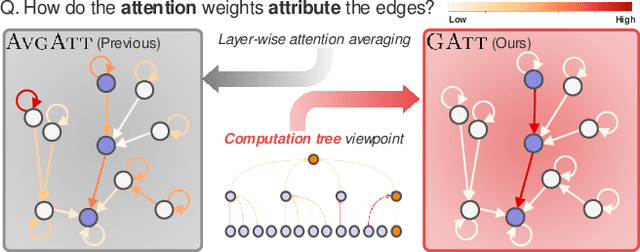

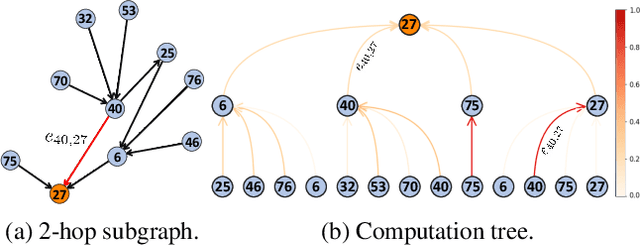
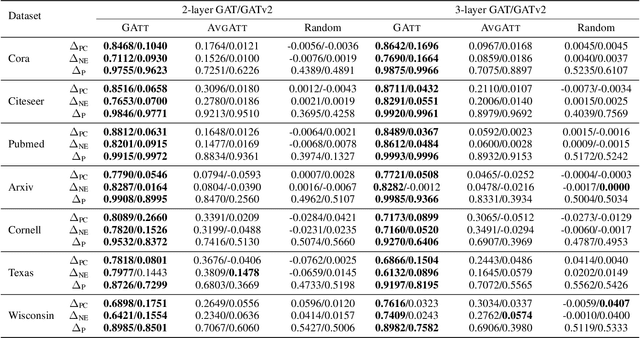
The self-attention mechanism has been adopted in several widely-used message-passing neural networks (MPNNs) (e.g., GATs), which adaptively controls the amount of information that flows along the edges of the underlying graph. This usage of attention has made such models a baseline for studies on explainable AI (XAI) since interpretations via attention have been popularized in various domains (e.g., natural language processing and computer vision). However, existing studies often use naive calculations to derive attribution scores from attention, and do not take the precise and careful calculation of edge attribution into consideration. In our study, we aim to fill the gap between the widespread usage of attention-enabled MPNNs and their potential in largely under-explored explainability, a topic that has been actively investigated in other areas. To this end, as the first attempt, we formalize the problem of edge attribution from attention weights in GNNs. Then, we propose GATT, an edge attribution calculation method built upon the computation tree. Through comprehensive experiments, we demonstrate the effectiveness of our proposed method when evaluating attributions from GATs. Conversely, we empirically validate that simply averaging attention weights over graph attention layers is insufficient to interpret the GAT model's behavior. Code is publicly available at https://github.com/jordan7186/GAtt/tree/main.
Turbo-CF: Matrix Decomposition-Free Graph Filtering for Fast Recommendation
Apr 22, 2024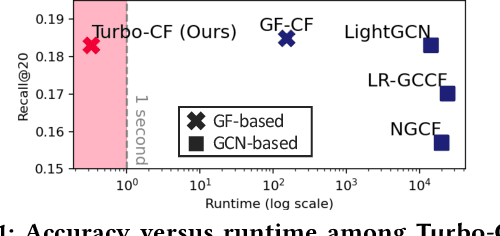
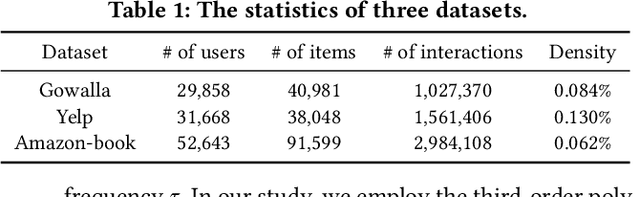
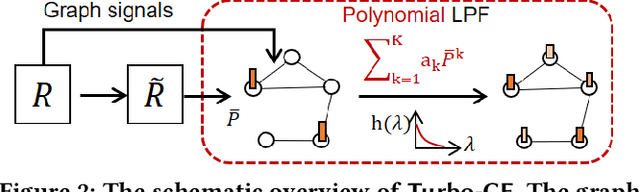

A series of graph filtering (GF)-based collaborative filtering (CF) showcases state-of-the-art performance on the recommendation accuracy by using a low-pass filter (LPF) without a training process. However, conventional GF-based CF approaches mostly perform matrix decomposition on the item-item similarity graph to realize the ideal LPF, which results in a non-trivial computational cost and thus makes them less practical in scenarios where rapid recommendations are essential. In this paper, we propose Turbo-CF, a GF-based CF method that is both training-free and matrix decomposition-free. Turbo-CF employs a polynomial graph filter to circumvent the issue of expensive matrix decompositions, enabling us to make full use of modern computer hardware components (i.e., GPU). Specifically, Turbo-CF first constructs an item-item similarity graph whose edge weights are effectively regulated. Then, our own polynomial LPFs are designed to retain only low-frequency signals without explicit matrix decompositions. We demonstrate that Turbo-CF is extremely fast yet accurate, achieving a runtime of less than 1 second on real-world benchmark datasets while achieving recommendation accuracies comparable to best competitors.
Propagate & Distill: Towards Effective Graph Learners Using Propagation-Embracing MLPs
Nov 29, 2023



Recent studies attempted to utilize multilayer perceptrons (MLPs) to solve semisupervised node classification on graphs, by training a student MLP by knowledge distillation from a teacher graph neural network (GNN). While previous studies have focused mostly on training the student MLP by matching the output probability distributions between the teacher and student models during distillation, it has not been systematically studied how to inject the structural information in an explicit and interpretable manner. Inspired by GNNs that separate feature transformation $T$ and propagation $\Pi$, we re-frame the distillation process as making the student MLP learn both $T$ and $\Pi$. Although this can be achieved by applying the inverse propagation $\Pi^{-1}$ before distillation from the teacher, it still comes with a high computational cost from large matrix multiplications during training. To solve this problem, we propose Propagate & Distill (P&D), which propagates the output of the teacher before distillation, which can be interpreted as an approximate process of the inverse propagation. We demonstrate that P&D can readily improve the performance of the student MLP.
Unveiling the Unseen Potential of Graph Learning through MLPs: Effective Graph Learners Using Propagation-Embracing MLPs
Nov 20, 2023Recent studies attempted to utilize multilayer perceptrons (MLPs) to solve semi-supervised node classification on graphs, by training a student MLP by knowledge distillation (KD) from a teacher graph neural network (GNN). While previous studies have focused mostly on training the student MLP by matching the output probability distributions between the teacher and student models during KD, it has not been systematically studied how to inject the structural information in an explicit and interpretable manner. Inspired by GNNs that separate feature transformation $T$ and propagation $\Pi$, we re-frame the KD process as enabling the student MLP to explicitly learn both $T$ and $\Pi$. Although this can be achieved by applying the inverse propagation $\Pi^{-1}$ before distillation from the teacher GNN, it still comes with a high computational cost from large matrix multiplications during training. To solve this problem, we propose Propagate & Distill (P&D), which propagates the output of the teacher GNN before KD and can be interpreted as an approximate process of the inverse propagation $\Pi^{-1}$. Through comprehensive evaluations using real-world benchmark datasets, we demonstrate the effectiveness of P&D by showing further performance boost of the student MLP.
PAGE: Prototype-Based Model-Level Explanations for Graph Neural Networks
Oct 31, 2022

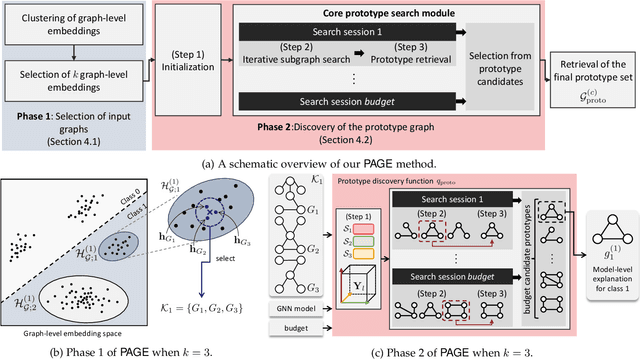

Aside from graph neural networks (GNNs) catching significant attention as a powerful framework revolutionizing graph representation learning, there has been an increasing demand for explaining GNN models. Although various explanation methods for GNNs have been developed, most studies have focused on instance-level explanations, which produce explanations tailored to a given graph instance. In our study, we propose Prototype-bAsed GNN-Explainer (PAGE), a novel model-level GNN explanation method that explains what the underlying GNN model has learned for graph classification by discovering human-interpretable prototype graphs. Our method produces explanations for a given class, thus being capable of offering more concise and comprehensive explanations than those of instance-level explanations. First, PAGE selects embeddings of class-discriminative input graphs on the graph-level embedding space after clustering them. Then, PAGE discovers a common subgraph pattern by iteratively searching for high matching node tuples using node-level embeddings via a prototype scoring function, thereby yielding a prototype graph as our explanation. Using five graph classification datasets, we demonstrate that PAGE qualitatively and quantitatively outperforms the state-of-the-art model-level explanation method. We also carry out experimental studies systematically by showing the relationship between PAGE and instance-level explanation methods, the robustness of PAGE to input data scarce environments, and the computational efficiency of the proposed prototype scoring function in PAGE.
Time-Series Anomaly Detection with Implicit Neural Representation
Jan 28, 2022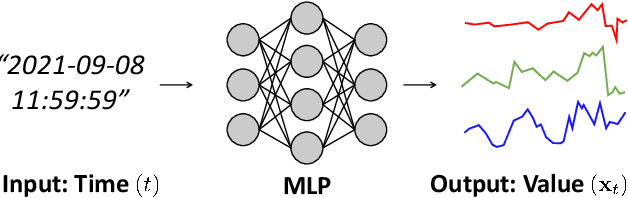
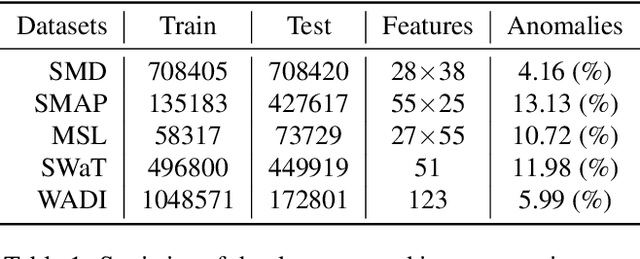
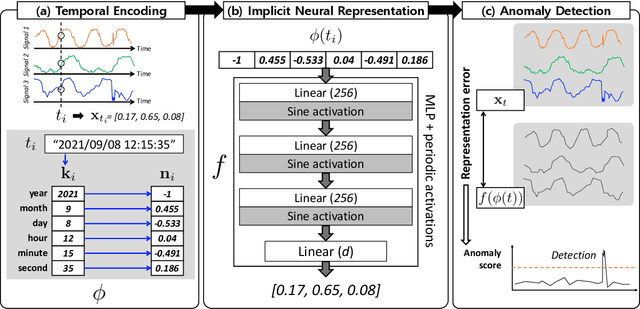
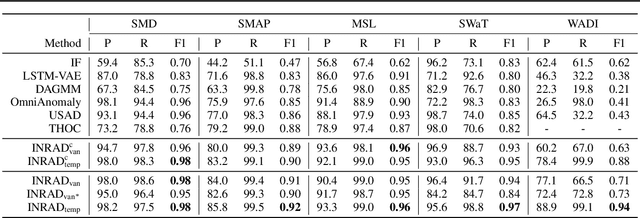
Detecting anomalies in multivariate time-series data is essential in many real-world applications. Recently, various deep learning-based approaches have shown considerable improvements in time-series anomaly detection. However, existing methods still have several limitations, such as long training time due to their complex model designs or costly tuning procedures to find optimal hyperparameters (e.g., sliding window length) for a given dataset. In our paper, we propose a novel method called Implicit Neural Representation-based Anomaly Detection (INRAD). Specifically, we train a simple multi-layer perceptron that takes time as input and outputs corresponding values at that time. Then we utilize the representation error as an anomaly score for detecting anomalies. Experiments on five real-world datasets demonstrate that our proposed method outperforms other state-of-the-art methods in performance, training speed, and robustness.
Edgeless-GNN: Unsupervised Inductive Edgeless Network Embedding
Apr 12, 2021
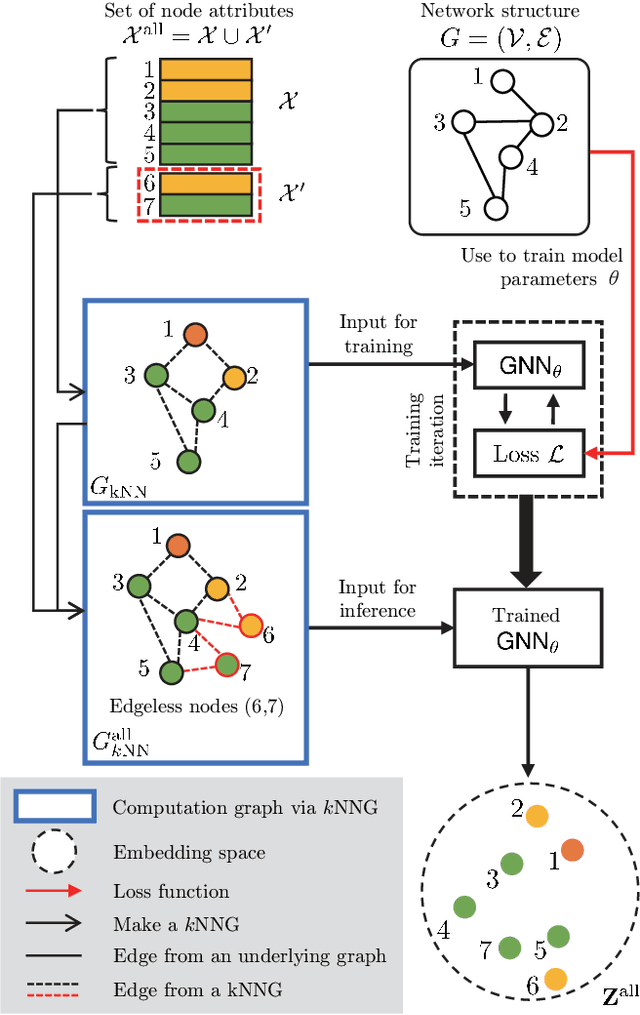
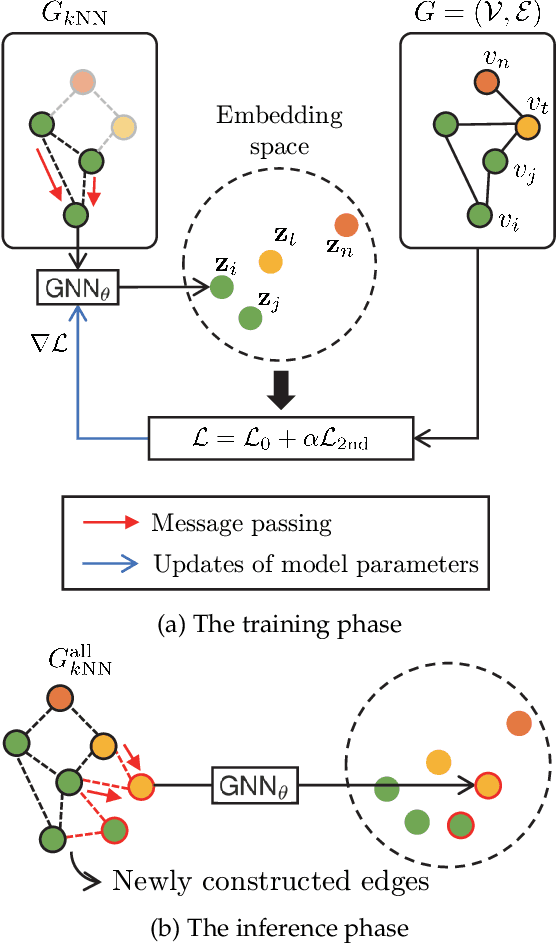
We study the problem of embedding edgeless nodes such as users who newly enter the underlying network, while using graph neural networks (GNNs) widely studied for effective representation learning of graphs thanks to its highly expressive capability via message passing. Our study is motivated by the fact that GNNs cannot be adopted for our problem since message passing to such edgeless nodes having no connections is impossible. To tackle this challenge, we propose Edgeless-GNN, a new framework that enables GNNs to generate node embeddings even for edgeless nodes through unsupervised inductive learning. Specifically, we utilize a $k$-nearest neighbor graph ($k$NNG) based on the similarity of node attributes to replace the GNN's computation graph defined by the neighborhood-based aggregation of each node. The known network structure is used to train model parameters, whereas a loss function is established in such a way that our model learns the network structure. For the edgeless nodes, we inductively infer embeddings by using edges via $k$NNG construction as a computation graph. By evaluating the performance of various downstream machine learning (ML) tasks, we empirically demonstrate that Edgeless-GNN consistently outperforms state-of-the-art methods of inductive network embedding. Our framework is GNN-model-agnostic; thus, GNN models can be appropriately chosen according to ones' needs and ML tasks.