 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFIXAR: A Fixed-Point Deep Reinforcement Learning Platform with Quantization-Aware Training and Adaptive Parallelism
Paper and Code
Feb 24, 2021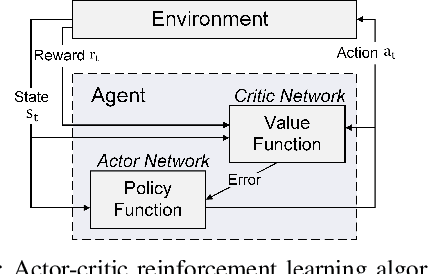
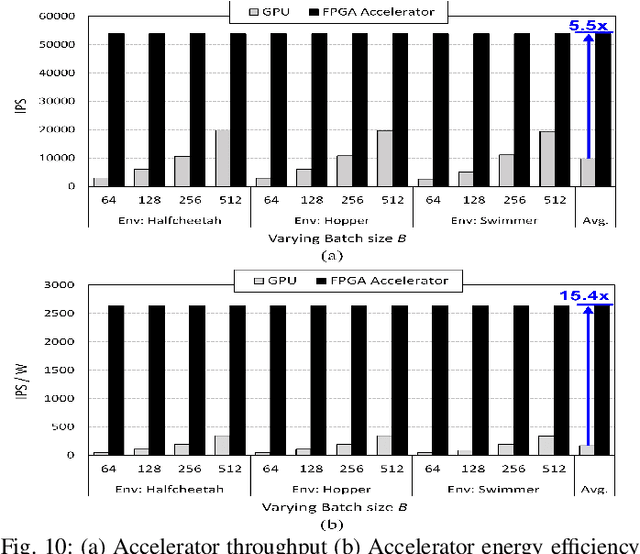
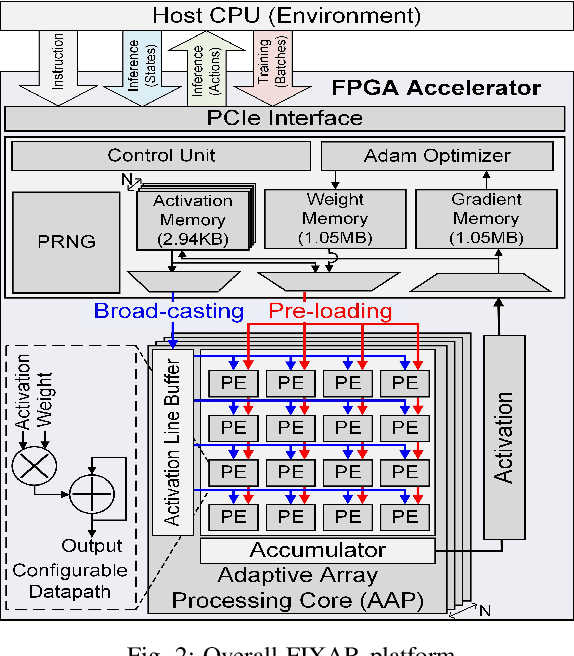
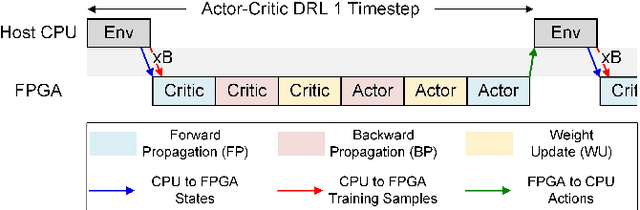
In this paper, we present a deep reinforcement learning platform named FIXAR which employs fixed-point data types and arithmetic units for the first time using a SW/HW co-design approach. Starting from 32-bit fixed-point data, Quantization-Aware Training (QAT) reduces its data precision based on the range of activations and performs retraining to minimize the reward degradation. FIXAR proposes the adaptive array processing core composed of configurable processing elements to support both intra-layer parallelism and intra-batch parallelism for high-throughput inference and training. Finally, FIXAR was implemented on Xilinx U50 and achieves 25293.3 inferences per second (IPS) training throughput and 2638.0 IPS/W accelerator efficiency, which is 2.7 times faster and 15.4 times more energy efficient than those of the CPU-GPU platform without any accuracy degradation.