 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOaken: Fast and Efficient LLM Serving with Online-Offline Hybrid KV Cache Quantization
Paper and Code
Mar 24, 2025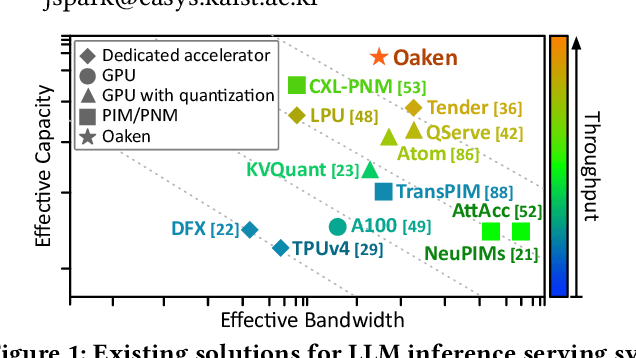

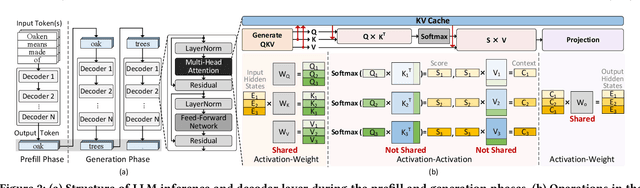
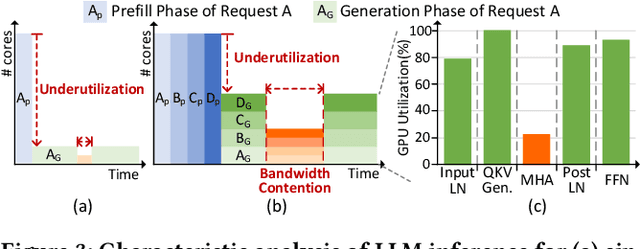
Modern Large Language Model serving system batches multiple requests to achieve high throughput, while batching attention operations is challenging, rendering memory bandwidth a critical bottleneck. The community relies on high-end GPUs with multiple high-bandwidth memory channels. Unfortunately, HBM's high bandwidth often comes at the expense of limited memory capacity, which reduces core utilization and increases costs. Recent advancements enabling longer contexts for LLMs have substantially increased the key-value cache size, further intensifying the pressures on memory capacity. The literature has explored KV cache quantization techniques, which commonly use low bitwidth for most values, selectively using higher bitwidth for outlier values. While this approach helps achieve high accuracy and low bitwidth simultaneously, it comes with the limitation that cost for online outlier detection is excessively high, negating the advantages. We propose Oaken, an acceleration solution that achieves high accuracy and high performance simultaneously through co-designing algorithm and hardware. To effectively find a sweet spot in the accuracy-performance trade-off space of KV cache quantization, Oaken employs an online-offline hybrid approach, setting outlier thresholds offline, which are then used to determine the quantization scale online. To translate the proposed algorithmic technique into tangible performance gains, Oaken also comes with custom quantization engines and memory management units that can be integrated with any LLM accelerators. We built an Oaken accelerator on top of an LLM accelerator, LPU, and conducted a comprehensive evaluation. Our experiments show that for a batch size of 256, Oaken achieves up to 1.58x throughput improvement over NVIDIA A100 GPU, incurring a minimal accuracy loss of only 0.54\% on average, compared to state-of-the-art KV cache quantization techniques.