 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOaken: Fast and Efficient LLM Serving with Online-Offline Hybrid KV Cache Quantization
Mar 24, 2025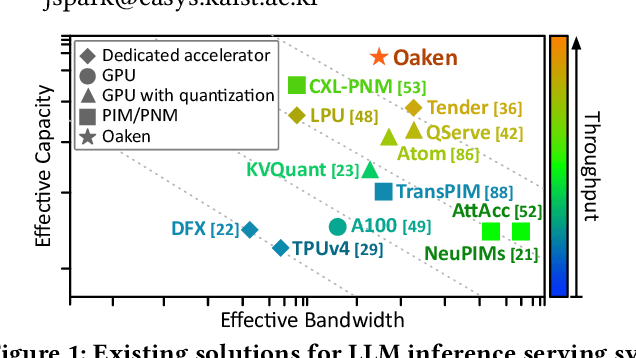

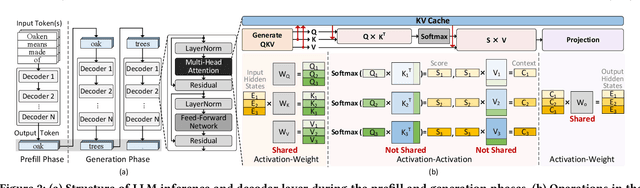
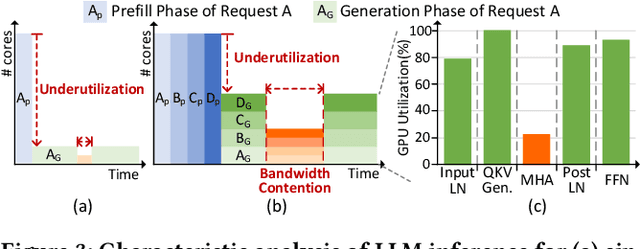
Modern Large Language Model serving system batches multiple requests to achieve high throughput, while batching attention operations is challenging, rendering memory bandwidth a critical bottleneck. The community relies on high-end GPUs with multiple high-bandwidth memory channels. Unfortunately, HBM's high bandwidth often comes at the expense of limited memory capacity, which reduces core utilization and increases costs. Recent advancements enabling longer contexts for LLMs have substantially increased the key-value cache size, further intensifying the pressures on memory capacity. The literature has explored KV cache quantization techniques, which commonly use low bitwidth for most values, selectively using higher bitwidth for outlier values. While this approach helps achieve high accuracy and low bitwidth simultaneously, it comes with the limitation that cost for online outlier detection is excessively high, negating the advantages. We propose Oaken, an acceleration solution that achieves high accuracy and high performance simultaneously through co-designing algorithm and hardware. To effectively find a sweet spot in the accuracy-performance trade-off space of KV cache quantization, Oaken employs an online-offline hybrid approach, setting outlier thresholds offline, which are then used to determine the quantization scale online. To translate the proposed algorithmic technique into tangible performance gains, Oaken also comes with custom quantization engines and memory management units that can be integrated with any LLM accelerators. We built an Oaken accelerator on top of an LLM accelerator, LPU, and conducted a comprehensive evaluation. Our experiments show that for a batch size of 256, Oaken achieves up to 1.58x throughput improvement over NVIDIA A100 GPU, incurring a minimal accuracy loss of only 0.54\% on average, compared to state-of-the-art KV cache quantization techniques.
DFX: A Low-latency Multi-FPGA Appliance for Accelerating Transformer-based Text Generation
Sep 22, 2022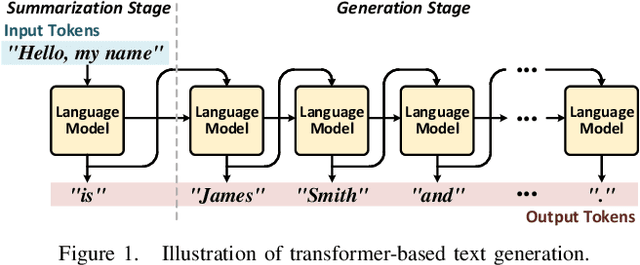
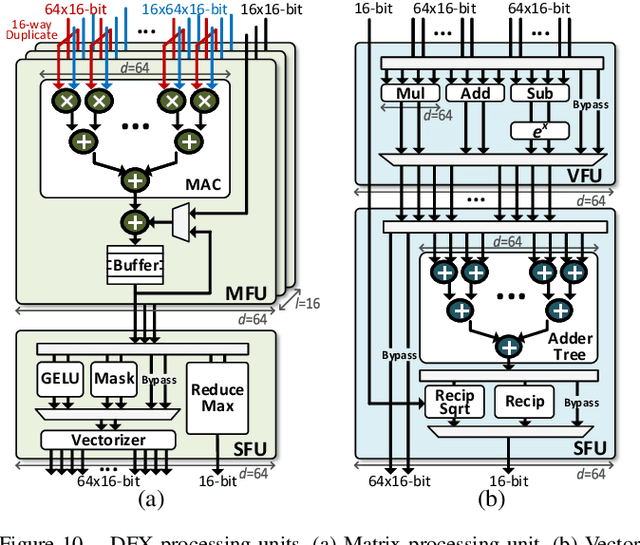
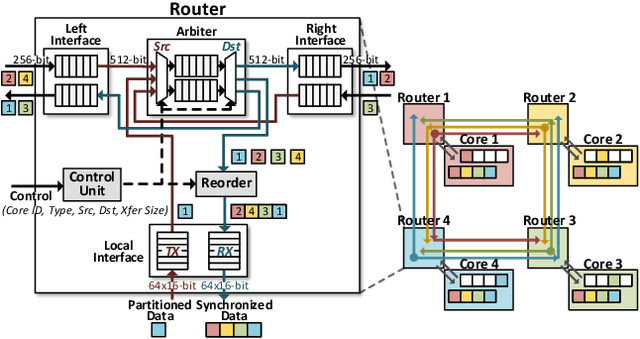
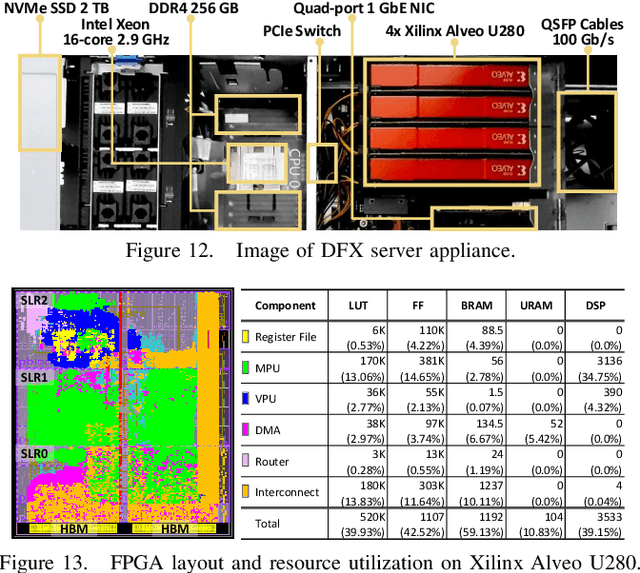
Transformer is a deep learning language model widely used for natural language processing (NLP) services in datacenters. Among transformer models, Generative Pre-trained Transformer (GPT) has achieved remarkable performance in text generation, or natural language generation (NLG), which needs the processing of a large input context in the summarization stage, followed by the generation stage that produces a single word at a time. The conventional platforms such as GPU are specialized for the parallel processing of large inputs in the summarization stage, but their performance significantly degrades in the generation stage due to its sequential characteristic. Therefore, an efficient hardware platform is required to address the high latency caused by the sequential characteristic of text generation. In this paper, we present DFX, a multi-FPGA acceleration appliance that executes GPT-2 model inference end-to-end with low latency and high throughput in both summarization and generation stages. DFX uses model parallelism and optimized dataflow that is model-and-hardware-aware for fast simultaneous workload execution among devices. Its compute cores operate on custom instructions and provide GPT-2 operations end-to-end. We implement the proposed hardware architecture on four Xilinx Alveo U280 FPGAs and utilize all of the channels of the high bandwidth memory (HBM) and the maximum number of compute resources for high hardware efficiency. DFX achieves 5.58x speedup and 3.99x energy efficiency over four NVIDIA V100 GPUs on the modern GPT-2 model. DFX is also 8.21x more cost-effective than the GPU appliance, suggesting that it is a promising solution for text generation workloads in cloud datacenters.
LaPred: Lane-Aware Prediction of Multi-Modal Future Trajectories of Dynamic Agents
Apr 01, 2021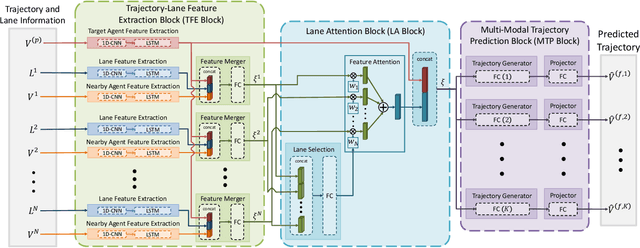
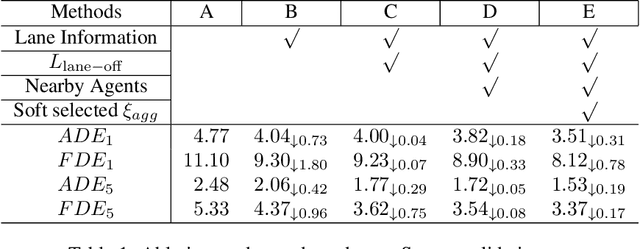
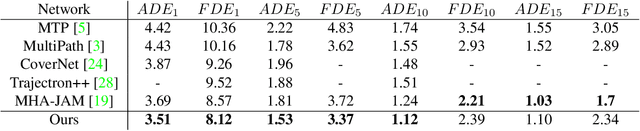
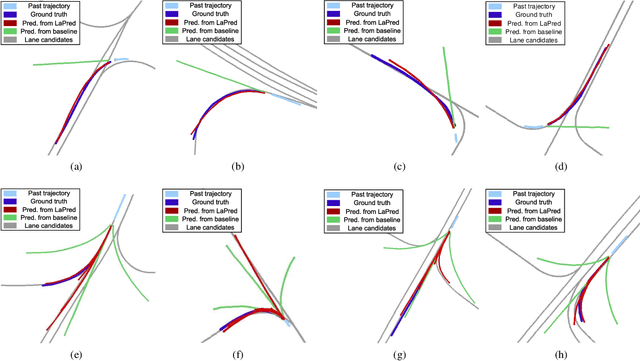
In this paper, we address the problem of predicting the future motion of a dynamic agent (called a target agent) given its current and past states as well as the information on its environment. It is paramount to develop a prediction model that can exploit the contextual information in both static and dynamic environments surrounding the target agent and generate diverse trajectory samples that are meaningful in a traffic context. We propose a novel prediction model, referred to as the lane-aware prediction (LaPred) network, which uses the instance-level lane entities extracted from a semantic map to predict the multi-modal future trajectories. For each lane candidate found in the neighborhood of the target agent, LaPred extracts the joint features relating the lane and the trajectories of the neighboring agents. Then, the features for all lane candidates are fused with the attention weights learned through a self-supervised learning task that identifies the lane candidate likely to be followed by the target agent. Using the instance-level lane information, LaPred can produce the trajectories compliant with the surroundings better than 2D raster image-based methods and generate the diverse future trajectories given multiple lane candidates. The experiments conducted on the public nuScenes dataset and Argoverse dataset demonstrate that the proposed LaPred method significantly outperforms the existing prediction models, achieving state-of-the-art performance in the benchmarks.