 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePAtt: A Pattern Attention Network for ETA Prediction Using Historical Speed Profiles
Jan 20, 2026In this paper, we propose an ETA model (Estimated Time of Arrival) that leverages an attention mechanism over historical road speed patterns. As autonomous driving and intelligent transportation systems become increasingly prevalent, the need for accurate and reliable ETA estimation has grown, playing a vital role in navigation, mobility planning, and traffic management. However, predicting ETA remains a challenging task due to the dynamic and complex nature of traffic flow. Traditional methods often combine real-time and historical traffic data in simplistic ways, or rely on complex rule-based computations. While recent deep learning models have shown potential, they often require high computational costs and do not effectively capture the spatio-temporal patterns crucial for ETA prediction. ETA prediction inherently involves spatio-temporal causality, and our proposed model addresses this by leveraging attention mechanisms to extract and utilize temporal features accumulated at each spatio-temporal point along a route. This architecture enables efficient and accurate ETA estimation while keeping the model lightweight and scalable. We validate our approach using real-world driving datasets and demonstrate that our approach outperforms existing baselines by effectively integrating road characteristics, real-time traffic conditions, and historical speed patterns in a task-aware manner.
LaPred: Lane-Aware Prediction of Multi-Modal Future Trajectories of Dynamic Agents
Apr 01, 2021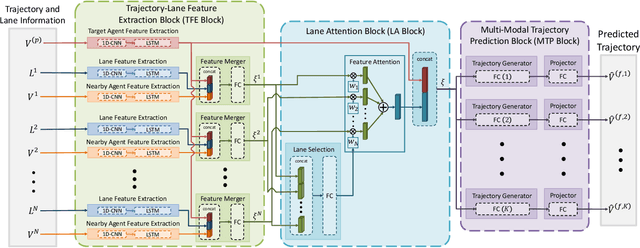
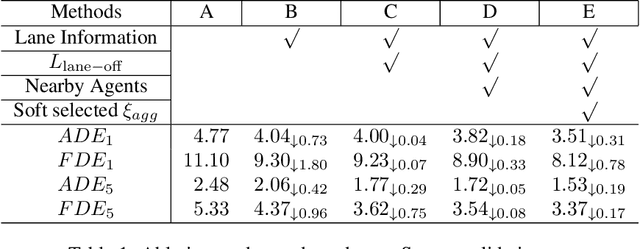
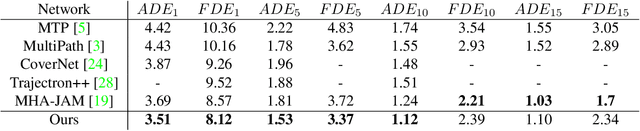
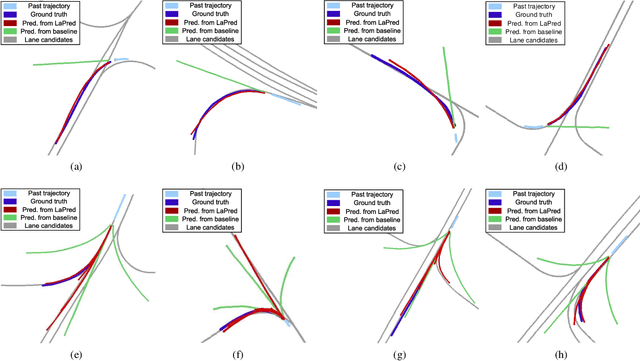
In this paper, we address the problem of predicting the future motion of a dynamic agent (called a target agent) given its current and past states as well as the information on its environment. It is paramount to develop a prediction model that can exploit the contextual information in both static and dynamic environments surrounding the target agent and generate diverse trajectory samples that are meaningful in a traffic context. We propose a novel prediction model, referred to as the lane-aware prediction (LaPred) network, which uses the instance-level lane entities extracted from a semantic map to predict the multi-modal future trajectories. For each lane candidate found in the neighborhood of the target agent, LaPred extracts the joint features relating the lane and the trajectories of the neighboring agents. Then, the features for all lane candidates are fused with the attention weights learned through a self-supervised learning task that identifies the lane candidate likely to be followed by the target agent. Using the instance-level lane information, LaPred can produce the trajectories compliant with the surroundings better than 2D raster image-based methods and generate the diverse future trajectories given multiple lane candidates. The experiments conducted on the public nuScenes dataset and Argoverse dataset demonstrate that the proposed LaPred method significantly outperforms the existing prediction models, achieving state-of-the-art performance in the benchmarks.
Probabilistic Vehicle Trajectory Prediction over Occupancy Grid Map via Recurrent Neural Network
Sep 01, 2017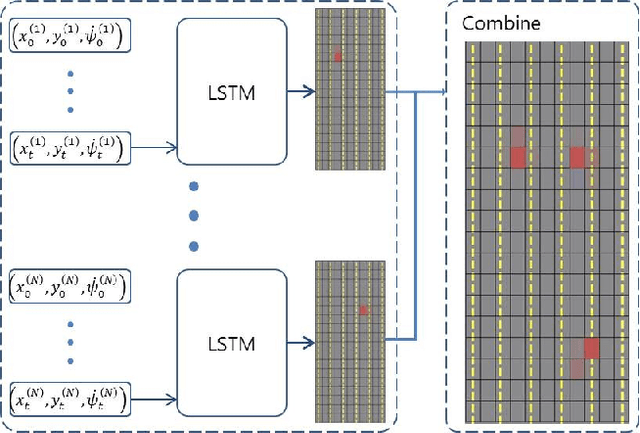


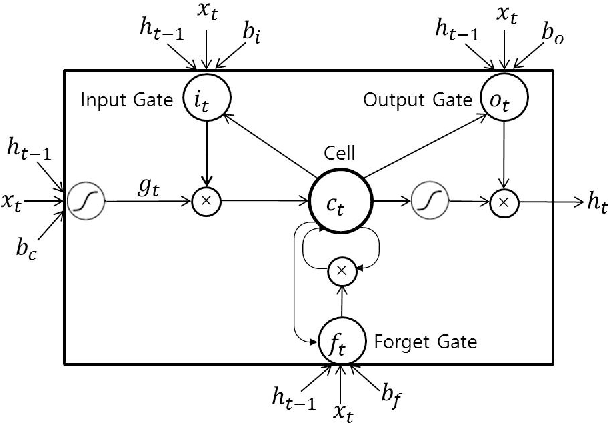
In this paper, we propose an efficient vehicle trajectory prediction framework based on recurrent neural network. Basically, the characteristic of the vehicle's trajectory is different from that of regular moving objects since it is affected by various latent factors including road structure, traffic rules, and driver's intention. Previous state of the art approaches use sophisticated vehicle behavior model describing these factors and derive the complex trajectory prediction algorithm, which requires a system designer to conduct intensive model optimization for practical use. Our approach is data-driven and simple to use in that it learns complex behavior of the vehicles from the massive amount of trajectory data through deep neural network model. The proposed trajectory prediction method employs the recurrent neural network called long short-term memory (LSTM) to analyze the temporal behavior and predict the future coordinate of the surrounding vehicles. The proposed scheme feeds the sequence of vehicles' coordinates obtained from sensor measurements to the LSTM and produces the probabilistic information on the future location of the vehicles over occupancy grid map. The experiments conducted using the data collected from highway driving show that the proposed method can produce reasonably good estimate of future trajectory.
Autonomous Braking System via Deep Reinforcement Learning
Apr 24, 2017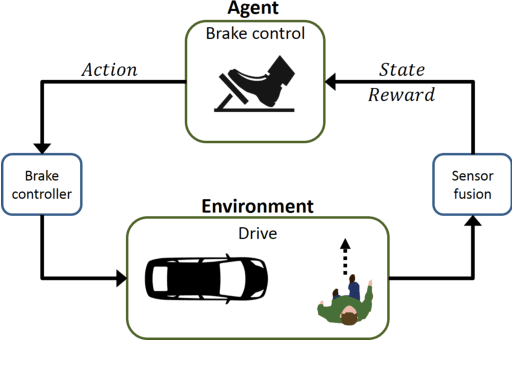
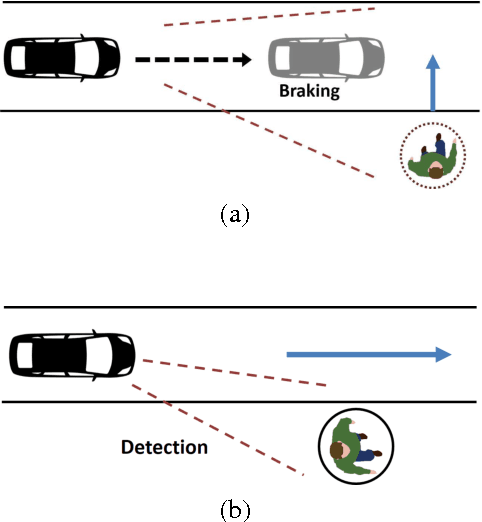
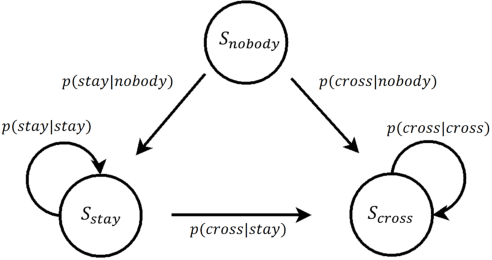
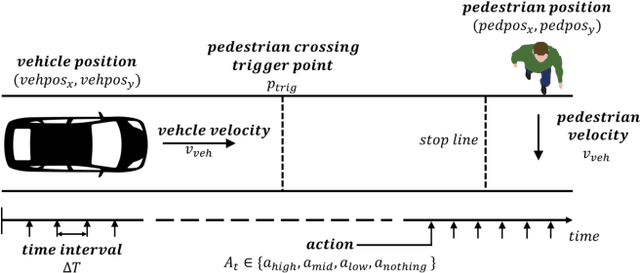
In this paper, we propose a new autonomous braking system based on deep reinforcement learning. The proposed autonomous braking system automatically decides whether to apply the brake at each time step when confronting the risk of collision using the information on the obstacle obtained by the sensors. The problem of designing brake control is formulated as searching for the optimal policy in Markov decision process (MDP) model where the state is given by the relative position of the obstacle and the vehicle's speed, and the action space is defined as whether brake is stepped or not. The policy used for brake control is learned through computer simulations using the deep reinforcement learning method called deep Q-network (DQN). In order to derive desirable braking policy, we propose the reward function which balances the damage imposed to the obstacle in case of accident and the reward achieved when the vehicle runs out of risk as soon as possible. DQN is trained for the scenario where a vehicle is encountered with a pedestrian crossing the urban road. Experiments show that the control agent exhibits desirable control behavior and avoids collision without any mistake in various uncertain environments.