 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Multi-frame and Monocular Prior for Estimating Geometry in Dynamic Scenes
May 03, 2025



In monocular videos that capture dynamic scenes, estimating the 3D geometry of video contents has been a fundamental challenge in computer vision. Specifically, the task is significantly challenged by the object motion, where existing models are limited to predict only partial attributes of the dynamic scenes, such as depth or pointmaps spanning only over a pair of frames. Since these attributes are inherently noisy under multiple frames, test-time global optimizations are often employed to fully recover the geometry, which is liable to failure and incurs heavy inference costs. To address the challenge, we present a new model, coined MMP, to estimate the geometry in a feed-forward manner, which produces a dynamic pointmap representation that evolves over multiple frames. Specifically, based on the recent Siamese architecture, we introduce a new trajectory encoding module to project point-wise dynamics on the representation for each frame, which can provide significantly improved expressiveness for dynamic scenes. In our experiments, we find MMP can achieve state-of-the-art quality in feed-forward pointmap prediction, e.g., 15.1% enhancement in the regression error.
Tabular Transfer Learning via Prompting LLMs
Aug 09, 2024Learning with a limited number of labeled data is a central problem in real-world applications of machine learning, as it is often expensive to obtain annotations. To deal with the scarcity of labeled data, transfer learning is a conventional approach; it suggests to learn a transferable knowledge by training a neural network from multiple other sources. In this paper, we investigate transfer learning of tabular tasks, which has been less studied and successful in the literature, compared to other domains, e.g., vision and language. This is because tables are inherently heterogeneous, i.e., they contain different columns and feature spaces, making transfer learning difficult. On the other hand, recent advances in natural language processing suggest that the label scarcity issue can be mitigated by utilizing in-context learning capability of large language models (LLMs). Inspired by this and the fact that LLMs can also process tables within a unified language space, we ask whether LLMs can be effective for tabular transfer learning, in particular, under the scenarios where the source and target datasets are of different format. As a positive answer, we propose a novel tabular transfer learning framework, coined Prompt to Transfer (P2T), that utilizes unlabeled (or heterogeneous) source data with LLMs. Specifically, P2T identifies a column feature in a source dataset that is strongly correlated with a target task feature to create examples relevant to the target task, thus creating pseudo-demonstrations for prompts. Experimental results demonstrate that P2T outperforms previous methods on various tabular learning benchmarks, showing good promise for the important, yet underexplored tabular transfer learning problem. Code is available at https://github.com/jaehyun513/P2T.
IFSeg: Image-free Semantic Segmentation via Vision-Language Model
Mar 25, 2023

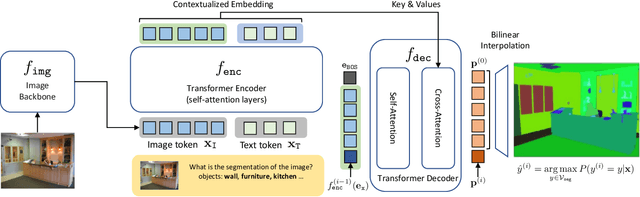

Vision-language (VL) pre-training has recently gained much attention for its transferability and flexibility in novel concepts (e.g., cross-modality transfer) across various visual tasks. However, VL-driven segmentation has been under-explored, and the existing approaches still have the burden of acquiring additional training images or even segmentation annotations to adapt a VL model to downstream segmentation tasks. In this paper, we introduce a novel image-free segmentation task where the goal is to perform semantic segmentation given only a set of the target semantic categories, but without any task-specific images and annotations. To tackle this challenging task, our proposed method, coined IFSeg, generates VL-driven artificial image-segmentation pairs and updates a pre-trained VL model to a segmentation task. We construct this artificial training data by creating a 2D map of random semantic categories and another map of their corresponding word tokens. Given that a pre-trained VL model projects visual and text tokens into a common space where tokens that share the semantics are located closely, this artificially generated word map can replace the real image inputs for such a VL model. Through an extensive set of experiments, our model not only establishes an effective baseline for this novel task but also demonstrates strong performances compared to existing methods that rely on stronger supervision, such as task-specific images and segmentation masks. Code is available at https://github.com/alinlab/ifseg.
LaPred: Lane-Aware Prediction of Multi-Modal Future Trajectories of Dynamic Agents
Apr 01, 2021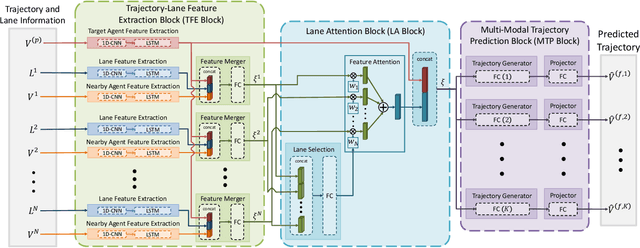
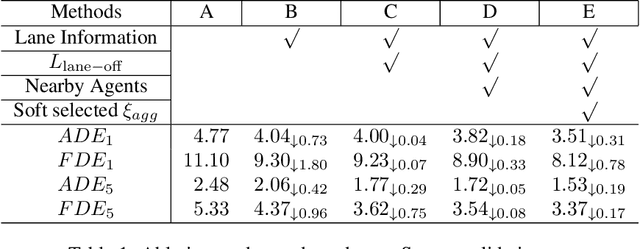
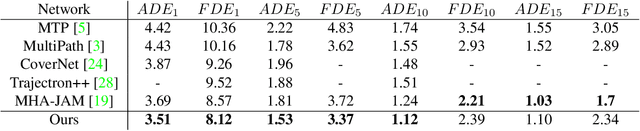
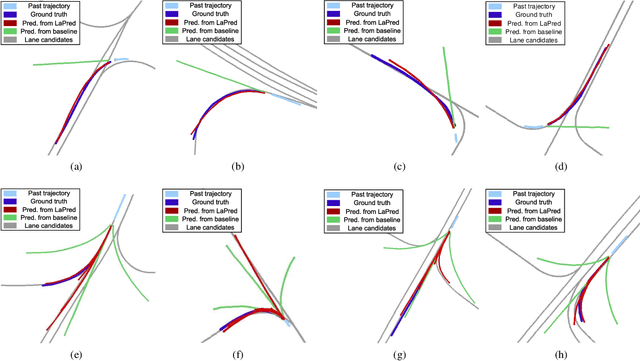
In this paper, we address the problem of predicting the future motion of a dynamic agent (called a target agent) given its current and past states as well as the information on its environment. It is paramount to develop a prediction model that can exploit the contextual information in both static and dynamic environments surrounding the target agent and generate diverse trajectory samples that are meaningful in a traffic context. We propose a novel prediction model, referred to as the lane-aware prediction (LaPred) network, which uses the instance-level lane entities extracted from a semantic map to predict the multi-modal future trajectories. For each lane candidate found in the neighborhood of the target agent, LaPred extracts the joint features relating the lane and the trajectories of the neighboring agents. Then, the features for all lane candidates are fused with the attention weights learned through a self-supervised learning task that identifies the lane candidate likely to be followed by the target agent. Using the instance-level lane information, LaPred can produce the trajectories compliant with the surroundings better than 2D raster image-based methods and generate the diverse future trajectories given multiple lane candidates. The experiments conducted on the public nuScenes dataset and Argoverse dataset demonstrate that the proposed LaPred method significantly outperforms the existing prediction models, achieving state-of-the-art performance in the benchmarks.
Diverse and Admissible Trajectory Forecasting through Multimodal Context Understanding
Apr 03, 2020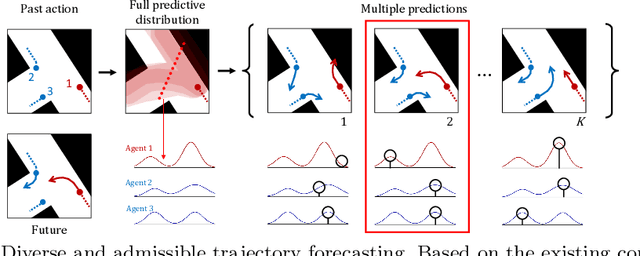

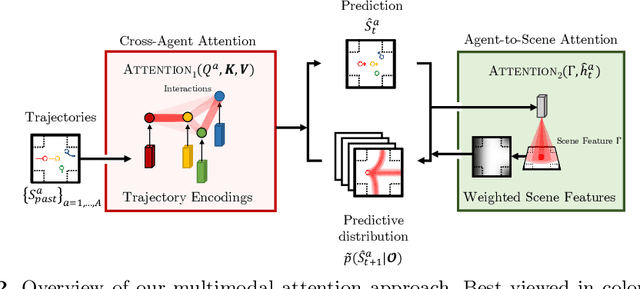
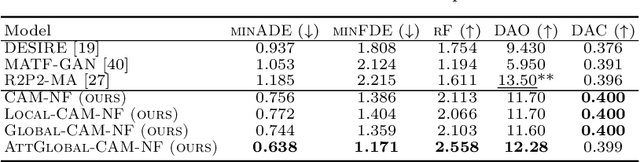
Multi-agent trajectory forecasting in autonomous driving requires an agent to accurately anticipate the behaviors of the surrounding vehicles and pedestrians, for safe and reliable decision-making. Due to partial observability over the goals, contexts, and interactions of agents in these dynamical scenes, directly obtaining the posterior distribution over future agent trajectories remains a challenging problem. In realistic embodied environments, each agent's future trajectories should be diverse since multiple plausible sequences of actions can be used to reach its intended goals, and they should be admissible since they must obey physical constraints and stay in drivable areas. In this paper, we propose a model that fully synthesizes multiple input signals from the multimodal world|the environment's scene context and interactions between multiple surrounding agents|to best model all diverse and admissible trajectories. We offer new metrics to evaluate the diversity of trajectory predictions, while ensuring admissibility of each trajectory. Based on our new metrics as well as those used in prior work, we compare our model with strong baselines and ablations across two datasets and show a 35% performance-improvement over the state-of-the-art.
ScarfNet: Multi-scale Features with Deeply Fused and Redistributed Semantics for Enhanced Object Detection
Aug 01, 2019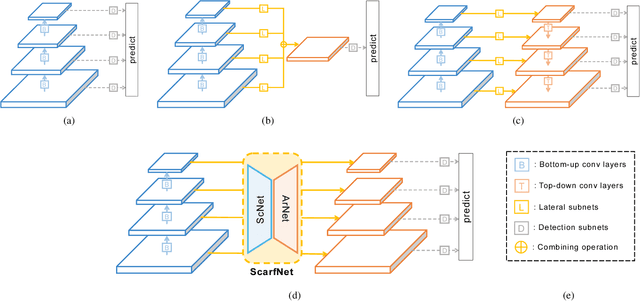
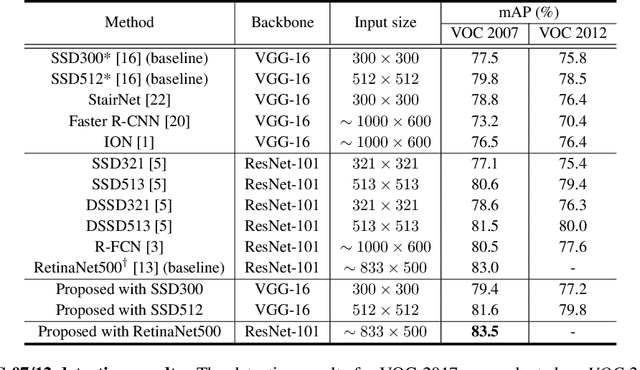
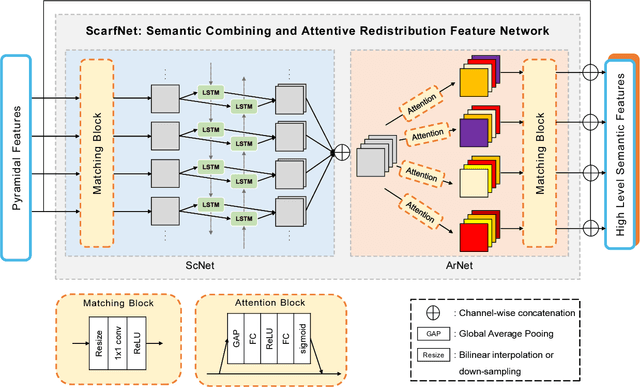
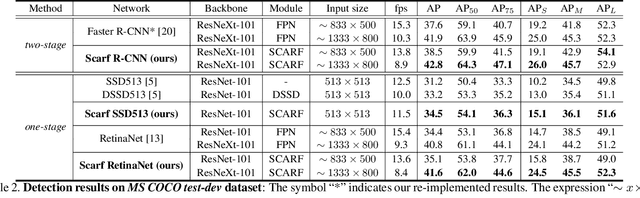
Convolutional neural network (CNN) has led to significant progress in object detection. In order to detect the objects in various sizes, the object detectors often exploit the hierarchy of the multi-scale feature maps called feature pyramid, which is readily obtained by the CNN architecture. However, the performance of these object detectors is limited since the bottom-level feature maps, which experience fewer convolutional layers, lack the semantic information needed to capture the characteristics of the small objects. In order to address such problem, various methods have been proposed to increase the depth for the bottom-level features used for object detection. While most approaches are based on the generation of additional features through the top-down pathway with lateral connections, our approach directly fuses multi-scale feature maps using bidirectional long short term memory (biLSTM) in effort to generate deeply fused semantics. Then, the resulting semantic information is redistributed to the individual pyramidal feature at each scale through the channel-wise attention model. We integrate our semantic combining and attentive redistribution feature network (ScarfNet) with baseline object detectors, i.e., Faster R-CNN, single-shot multibox detector (SSD) and RetinaNet. Our experiments show that our method outperforms the existing feature pyramid methods as well as the baseline detectors and achieve the state of the art performances in the PASCAL VOC and COCO detection benchmarks.
Sequence-to-Sequence Prediction of Vehicle Trajectory via LSTM Encoder-Decoder Architecture
Oct 22, 2018

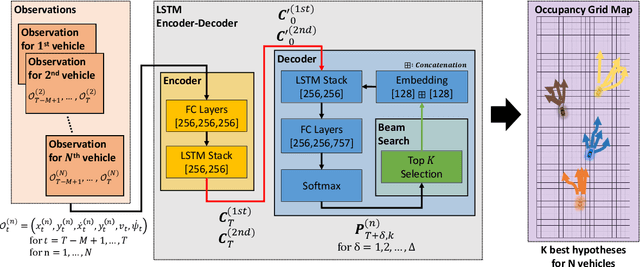

In this paper, we propose a deep learning based vehicle trajectory prediction technique which can generate the future trajectory sequence of surrounding vehicles in real time. We employ the encoder-decoder architecture which analyzes the pattern underlying in the past trajectory using the long short-term memory (LSTM) based encoder and generates the future trajectory sequence using the LSTM based decoder. This structure produces the $K$ most likely trajectory candidates over occupancy grid map by employing the beam search technique which keeps the $K$ locally best candidates from the decoder output. The experiments conducted on highway traffic scenarios show that the prediction accuracy of the proposed method is significantly higher than the conventional trajectory prediction techniques.