 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScarfNet: Multi-scale Features with Deeply Fused and Redistributed Semantics for Enhanced Object Detection
Paper and Code
Aug 01, 2019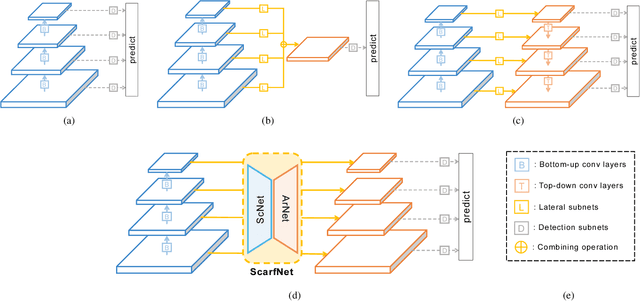
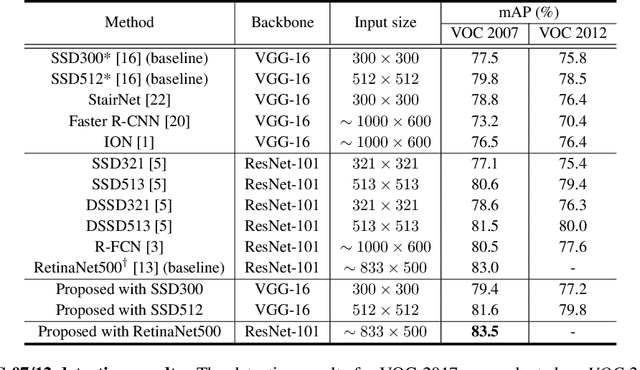
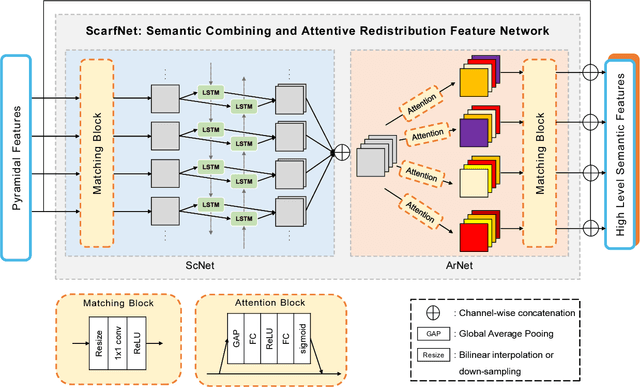
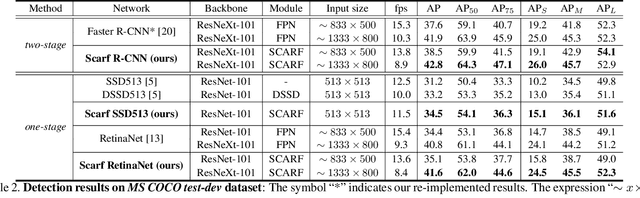
Convolutional neural network (CNN) has led to significant progress in object detection. In order to detect the objects in various sizes, the object detectors often exploit the hierarchy of the multi-scale feature maps called feature pyramid, which is readily obtained by the CNN architecture. However, the performance of these object detectors is limited since the bottom-level feature maps, which experience fewer convolutional layers, lack the semantic information needed to capture the characteristics of the small objects. In order to address such problem, various methods have been proposed to increase the depth for the bottom-level features used for object detection. While most approaches are based on the generation of additional features through the top-down pathway with lateral connections, our approach directly fuses multi-scale feature maps using bidirectional long short term memory (biLSTM) in effort to generate deeply fused semantics. Then, the resulting semantic information is redistributed to the individual pyramidal feature at each scale through the channel-wise attention model. We integrate our semantic combining and attentive redistribution feature network (ScarfNet) with baseline object detectors, i.e., Faster R-CNN, single-shot multibox detector (SSD) and RetinaNet. Our experiments show that our method outperforms the existing feature pyramid methods as well as the baseline detectors and achieve the state of the art performances in the PASCAL VOC and COCO detection benchmarks.