 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D-CVF: Generating Joint Camera and LiDAR Features Using Cross-View Spatial Feature Fusion for 3D Object Detection
Apr 27, 2020



In this paper, we propose a new deep architecture for fusing camera and LiDAR sensors for 3D object detection. Because the camera and LiDAR sensor signals have different characteristics and distributions, fusing these two modalities is expected to improve both the accuracy and robustness of 3D object detection. One of the challenges presented by the fusion of cameras and LiDAR is that the spatial feature maps obtained from each modality are represented by significantly different views in the camera and world coordinates; hence, it is not an easy task to combine two heterogeneous feature maps without loss of information. To address this problem, we propose a method called 3D-CVF that combines the camera and LiDAR features using the cross-view spatial feature fusion strategy. First, the method employs {\it auto-calibrated projection}, to transform the 2D camera features to a smooth spatial feature map with the highest correspondence to the LiDAR features in the bird's eye view (BEV) domain. Then, a {\it gated feature fusion network} is applied to use the spatial attention maps to mix the camera and LiDAR features appropriately according to the region. Next, camera-LiDAR feature fusion is also achieved in the subsequent proposal refinement stage. The camera feature is used from the 2D camera-view domain via {\it 3D RoI grid pooling} and fused with the BEV feature for proposal refinement. Our evaluations, conducted on the KITTI and nuScenes 3D object detection datasets demonstrate that the camera-LiDAR fusion offers significant performance gain over single modality and that the proposed 3D-CVF achieves state-of-the-art performance in the KITTI benchmark.
ScarfNet: Multi-scale Features with Deeply Fused and Redistributed Semantics for Enhanced Object Detection
Aug 01, 2019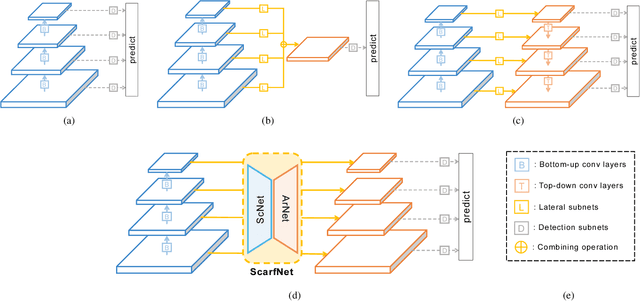
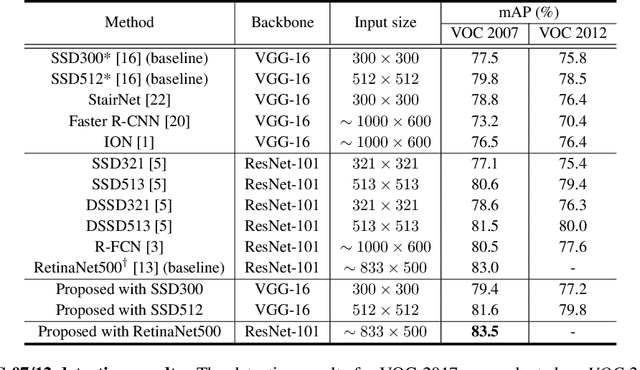
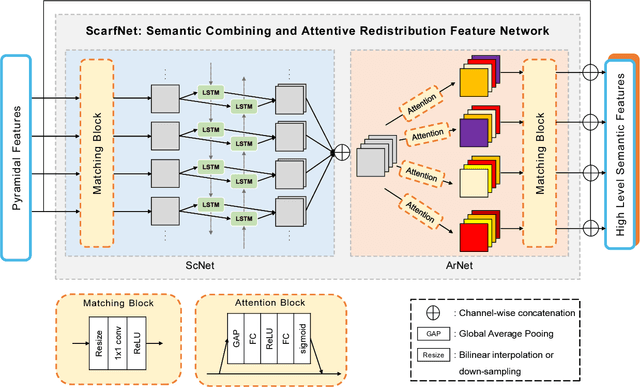
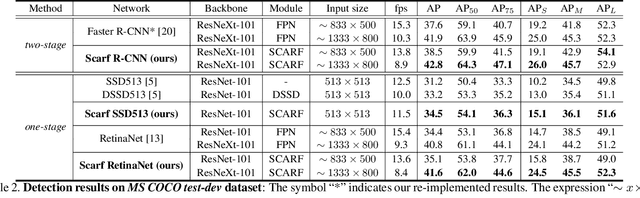
Convolutional neural network (CNN) has led to significant progress in object detection. In order to detect the objects in various sizes, the object detectors often exploit the hierarchy of the multi-scale feature maps called feature pyramid, which is readily obtained by the CNN architecture. However, the performance of these object detectors is limited since the bottom-level feature maps, which experience fewer convolutional layers, lack the semantic information needed to capture the characteristics of the small objects. In order to address such problem, various methods have been proposed to increase the depth for the bottom-level features used for object detection. While most approaches are based on the generation of additional features through the top-down pathway with lateral connections, our approach directly fuses multi-scale feature maps using bidirectional long short term memory (biLSTM) in effort to generate deeply fused semantics. Then, the resulting semantic information is redistributed to the individual pyramidal feature at each scale through the channel-wise attention model. We integrate our semantic combining and attentive redistribution feature network (ScarfNet) with baseline object detectors, i.e., Faster R-CNN, single-shot multibox detector (SSD) and RetinaNet. Our experiments show that our method outperforms the existing feature pyramid methods as well as the baseline detectors and achieve the state of the art performances in the PASCAL VOC and COCO detection benchmarks.