 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeb-Shepherd: Advancing PRMs for Reinforcing Web Agents
May 21, 2025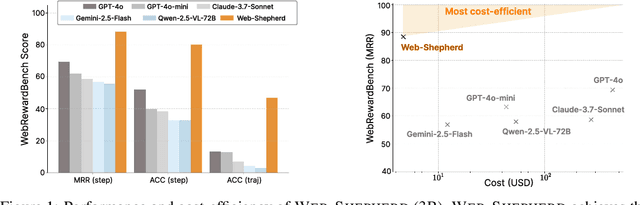


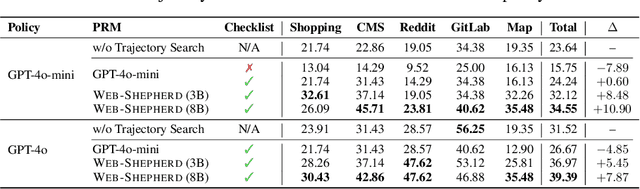
Web navigation is a unique domain that can automate many repetitive real-life tasks and is challenging as it requires long-horizon sequential decision making beyond typical multimodal large language model (MLLM) tasks. Yet, specialized reward models for web navigation that can be utilized during both training and test-time have been absent until now. Despite the importance of speed and cost-effectiveness, prior works have utilized MLLMs as reward models, which poses significant constraints for real-world deployment. To address this, in this work, we propose the first process reward model (PRM) called Web-Shepherd which could assess web navigation trajectories in a step-level. To achieve this, we first construct the WebPRM Collection, a large-scale dataset with 40K step-level preference pairs and annotated checklists spanning diverse domains and difficulty levels. Next, we also introduce the WebRewardBench, the first meta-evaluation benchmark for evaluating PRMs. In our experiments, we observe that our Web-Shepherd achieves about 30 points better accuracy compared to using GPT-4o on WebRewardBench. Furthermore, when testing on WebArena-lite by using GPT-4o-mini as the policy and Web-Shepherd as the verifier, we achieve 10.9 points better performance, in 10 less cost compared to using GPT-4o-mini as the verifier. Our model, dataset, and code are publicly available at LINK.
GenCLIP: Generalizing CLIP Prompts for Zero-shot Anomaly Detection
Apr 21, 2025Zero-shot anomaly detection (ZSAD) aims to identify anomalies in unseen categories by leveraging CLIP's zero-shot capabilities to match text prompts with visual features. A key challenge in ZSAD is learning general prompts stably and utilizing them effectively, while maintaining both generalizability and category specificity. Although general prompts have been explored in prior works, achieving their stable optimization and effective deployment remains a significant challenge. In this work, we propose GenCLIP, a novel framework that learns and leverages general prompts more effectively through multi-layer prompting and dual-branch inference. Multi-layer prompting integrates category-specific visual cues from different CLIP layers, enriching general prompts with more comprehensive and robust feature representations. By combining general prompts with multi-layer visual features, our method further enhances its generalization capability. To balance specificity and generalization, we introduce a dual-branch inference strategy, where a vision-enhanced branch captures fine-grained category-specific features, while a query-only branch prioritizes generalization. The complementary outputs from both branches improve the stability and reliability of anomaly detection across unseen categories. Additionally, we propose an adaptive text prompt filtering mechanism, which removes irrelevant or atypical class names not encountered during CLIP's training, ensuring that only meaningful textual inputs contribute to the final vision-language alignment.
Cactus: Towards Psychological Counseling Conversations using Cognitive Behavioral Theory
Jul 03, 2024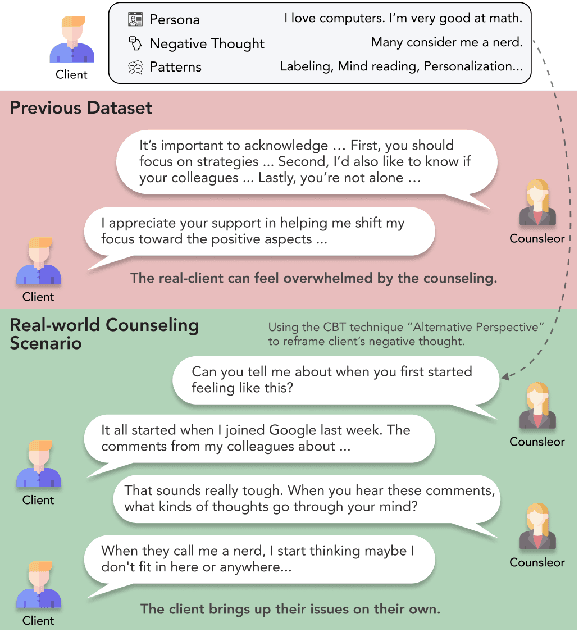



Recently, the demand for psychological counseling has significantly increased as more individuals express concerns about their mental health. This surge has accelerated efforts to improve the accessibility of counseling by using large language models (LLMs) as counselors. To ensure client privacy, training open-source LLMs faces a key challenge: the absence of realistic counseling datasets. To address this, we introduce Cactus, a multi-turn dialogue dataset that emulates real-life interactions using the goal-oriented and structured approach of Cognitive Behavioral Therapy (CBT). We create a diverse and realistic dataset by designing clients with varied, specific personas, and having counselors systematically apply CBT techniques in their interactions. To assess the quality of our data, we benchmark against established psychological criteria used to evaluate real counseling sessions, ensuring alignment with expert evaluations. Experimental results demonstrate that Camel, a model trained with Cactus, outperforms other models in counseling skills, highlighting its effectiveness and potential as a counseling agent. We make our data, model, and code publicly available.
Diverse and Admissible Trajectory Forecasting through Multimodal Context Understanding
Apr 03, 2020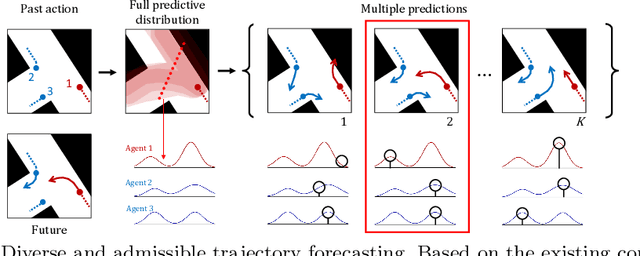

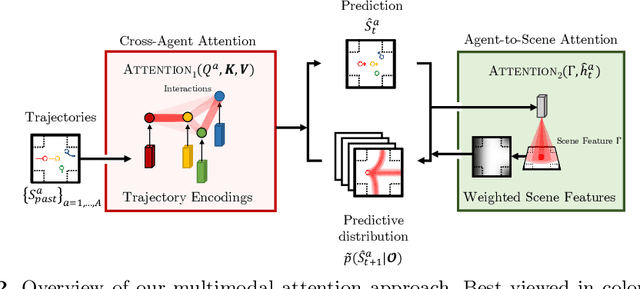
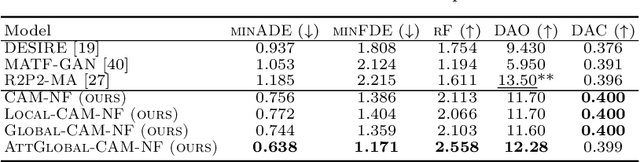
Multi-agent trajectory forecasting in autonomous driving requires an agent to accurately anticipate the behaviors of the surrounding vehicles and pedestrians, for safe and reliable decision-making. Due to partial observability over the goals, contexts, and interactions of agents in these dynamical scenes, directly obtaining the posterior distribution over future agent trajectories remains a challenging problem. In realistic embodied environments, each agent's future trajectories should be diverse since multiple plausible sequences of actions can be used to reach its intended goals, and they should be admissible since they must obey physical constraints and stay in drivable areas. In this paper, we propose a model that fully synthesizes multiple input signals from the multimodal world|the environment's scene context and interactions between multiple surrounding agents|to best model all diverse and admissible trajectories. We offer new metrics to evaluate the diversity of trajectory predictions, while ensuring admissibility of each trajectory. Based on our new metrics as well as those used in prior work, we compare our model with strong baselines and ablations across two datasets and show a 35% performance-improvement over the state-of-the-art.