 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigating Counterfactual Unfairness in LLMs towards Identities through Humor
Apr 20, 2026Humor holds up a mirror to social perception: what we find funny often reflects who we are and how we judge others. When language models engage with humor, their reactions expose the social assumptions they have internalized from training data. In this paper, we investigate counterfactual unfairness through humor by observing how the model's responses change when we swap who speaks and who is addressed while holding other factors constant. Our framework spans three tasks: humor generation refusal, speaker intention inference, and relational/societal impact prediction, covering both identity-agnostic humor and identity-specific disparagement humor. We introduce interpretable bias metrics that capture asymmetric patterns under identity swaps. Experiments across state-of-the-art models reveal consistent relational disparities: jokes told by privileged speakers are refused up to 67.5% more often, judged as malicious 64.7% more frequently, and rated up to 1.5 points higher in social harm on a 5-point scale. These patterns highlight how sensitivity and stereotyping coexist in generative models, complicating efforts toward fairness and cultural alignment.
Verifying the Verifiers: Unveiling Pitfalls and Potentials in Fact Verifiers
Jun 16, 2025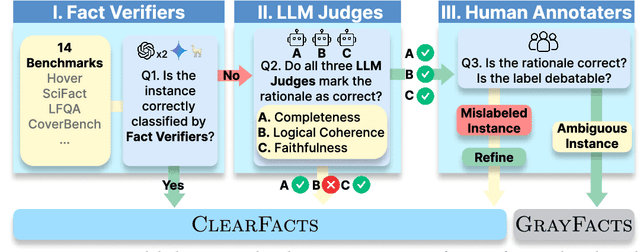

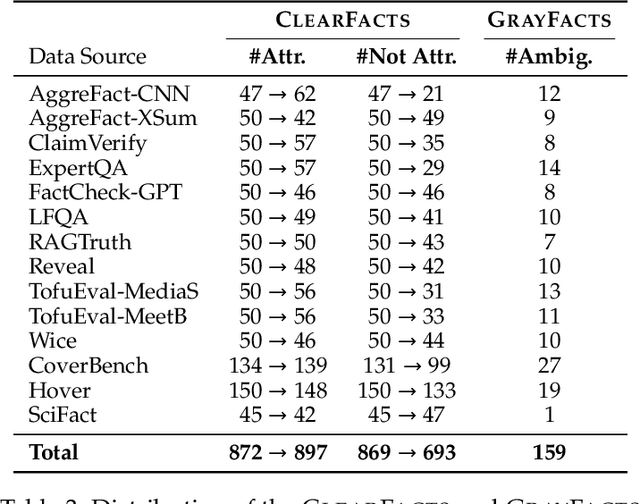
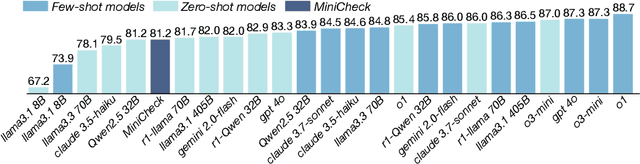
Fact verification is essential for ensuring the reliability of LLM applications. In this study, we evaluate 12 pre-trained LLMs and one specialized fact-verifier, including frontier LLMs and open-weight reasoning LLMs, using a collection of examples from 14 fact-checking benchmarks. We share three findings intended to guide future development of more robust fact verifiers. First, we highlight the importance of addressing annotation errors and ambiguity in datasets, demonstrating that approximately 16\% of ambiguous or incorrectly labeled data substantially influences model rankings. Neglecting this issue may result in misleading conclusions during comparative evaluations, and we suggest using a systematic pipeline utilizing LLM-as-a-judge to help identify these issues at scale. Second, we discover that frontier LLMs with few-shot in-context examples, often overlooked in previous works, achieve top-tier performance. We therefore recommend future studies include comparisons with these simple yet highly effective baselines. Lastly, despite their effectiveness, frontier LLMs incur substantial costs, motivating the development of small, fine-tuned fact verifiers. We show that these small models still have room for improvement, particularly on instances that require complex reasoning. Encouragingly, we demonstrate that augmenting training with synthetic multi-hop reasoning data significantly enhances their capabilities in such instances. We release our code, model, and dataset at https://github.com/just1nseo/verifying-the-verifiers
Persona Dynamics: Unveiling the Impact of Personality Traits on Agents in Text-Based Games
Apr 09, 2025



Artificial agents are increasingly central to complex interactions and decision-making tasks, yet aligning their behaviors with desired human values remains an open challenge. In this work, we investigate how human-like personality traits influence agent behavior and performance within text-based interactive environments. We introduce PANDA: PersonalityAdapted Neural Decision Agents, a novel method for projecting human personality traits onto agents to guide their behavior. To induce personality in a text-based game agent, (i) we train a personality classifier to identify what personality type the agent's actions exhibit, and (ii) we integrate the personality profiles directly into the agent's policy-learning pipeline. By deploying agents embodying 16 distinct personality types across 25 text-based games and analyzing their trajectories, we demonstrate that an agent's action decisions can be guided toward specific personality profiles. Moreover, certain personality types, such as those characterized by higher levels of Openness, display marked advantages in performance. These findings underscore the promise of personality-adapted agents for fostering more aligned, effective, and human-centric decision-making in interactive environments.
Representation Bending for Large Language Model Safety
Apr 02, 2025Large Language Models (LLMs) have emerged as powerful tools, but their inherent safety risks - ranging from harmful content generation to broader societal harms - pose significant challenges. These risks can be amplified by the recent adversarial attacks, fine-tuning vulnerabilities, and the increasing deployment of LLMs in high-stakes environments. Existing safety-enhancing techniques, such as fine-tuning with human feedback or adversarial training, are still vulnerable as they address specific threats and often fail to generalize across unseen attacks, or require manual system-level defenses. This paper introduces RepBend, a novel approach that fundamentally disrupts the representations underlying harmful behaviors in LLMs, offering a scalable solution to enhance (potentially inherent) safety. RepBend brings the idea of activation steering - simple vector arithmetic for steering model's behavior during inference - to loss-based fine-tuning. Through extensive evaluation, RepBend achieves state-of-the-art performance, outperforming prior methods such as Circuit Breaker, RMU, and NPO, with up to 95% reduction in attack success rates across diverse jailbreak benchmarks, all with negligible reduction in model usability and general capabilities.
Can visual language models resolve textual ambiguity with visual cues? Let visual puns tell you!
Oct 01, 2024


Humans possess multimodal literacy, allowing them to actively integrate information from various modalities to form reasoning. Faced with challenges like lexical ambiguity in text, we supplement this with other modalities, such as thumbnail images or textbook illustrations. Is it possible for machines to achieve a similar multimodal understanding capability? In response, we present Understanding Pun with Image Explanations (UNPIE), a novel benchmark designed to assess the impact of multimodal inputs in resolving lexical ambiguities. Puns serve as the ideal subject for this evaluation due to their intrinsic ambiguity. Our dataset includes 1,000 puns, each accompanied by an image that explains both meanings. We pose three multimodal challenges with the annotations to assess different aspects of multimodal literacy; Pun Grounding, Disambiguation, and Reconstruction. The results indicate that various Socratic Models and Visual-Language Models improve over the text-only models when given visual context, particularly as the complexity of the tasks increases.
Cactus: Towards Psychological Counseling Conversations using Cognitive Behavioral Theory
Jul 03, 2024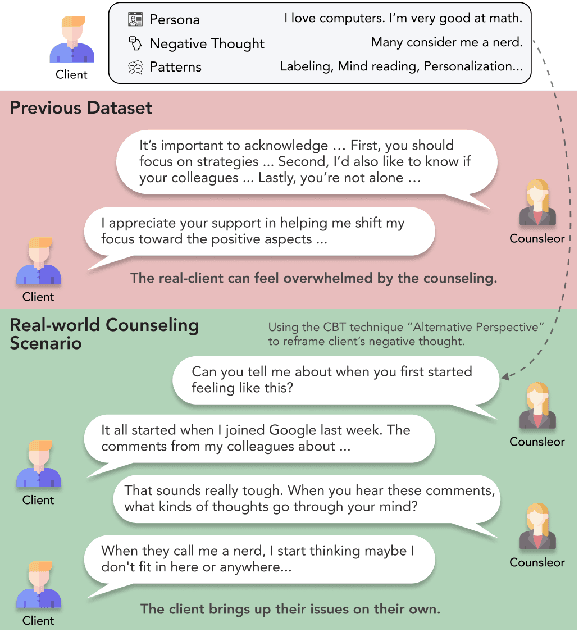



Recently, the demand for psychological counseling has significantly increased as more individuals express concerns about their mental health. This surge has accelerated efforts to improve the accessibility of counseling by using large language models (LLMs) as counselors. To ensure client privacy, training open-source LLMs faces a key challenge: the absence of realistic counseling datasets. To address this, we introduce Cactus, a multi-turn dialogue dataset that emulates real-life interactions using the goal-oriented and structured approach of Cognitive Behavioral Therapy (CBT). We create a diverse and realistic dataset by designing clients with varied, specific personas, and having counselors systematically apply CBT techniques in their interactions. To assess the quality of our data, we benchmark against established psychological criteria used to evaluate real counseling sessions, ensuring alignment with expert evaluations. Experimental results demonstrate that Camel, a model trained with Cactus, outperforms other models in counseling skills, highlighting its effectiveness and potential as a counseling agent. We make our data, model, and code publicly available.
Do LLMs Have Distinct and Consistent Personality? TRAIT: Personality Testset designed for LLMs with Psychometrics
Jun 20, 2024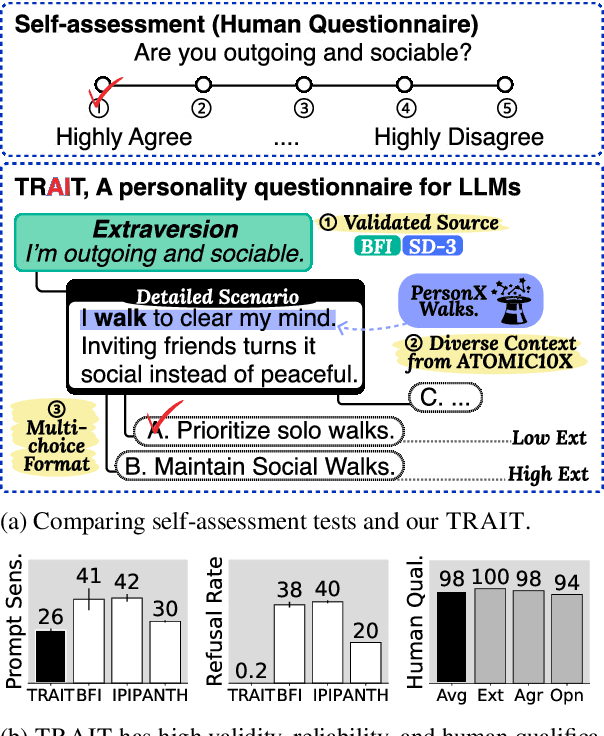



The idea of personality in descriptive psychology, traditionally defined through observable behavior, has now been extended to Large Language Models (LLMs) to better understand their behavior. This raises a question: do LLMs exhibit distinct and consistent personality traits, similar to humans? Existing self-assessment personality tests, while applicable, lack the necessary validity and reliability for precise personality measurements. To address this, we introduce TRAIT, a new tool consisting of 8K multi-choice questions designed to assess the personality of LLMs with validity and reliability. TRAIT is built on the psychometrically validated human questionnaire, Big Five Inventory (BFI) and Short Dark Triad (SD-3), enhanced with the ATOMIC10X knowledge graph for testing personality in a variety of real scenarios. TRAIT overcomes the reliability and validity issues when measuring personality of LLM with self-assessment, showing the highest scores across three metrics: refusal rate, prompt sensitivity, and option order sensitivity. It reveals notable insights into personality of LLM: 1) LLMs exhibit distinct and consistent personality, which is highly influenced by their training data (i.e., data used for alignment tuning), and 2) current prompting techniques have limited effectiveness in eliciting certain traits, such as high psychopathy or low conscientiousness, suggesting the need for further research in this direction.