 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDFX: A Low-latency Multi-FPGA Appliance for Accelerating Transformer-based Text Generation
Paper and Code
Sep 22, 2022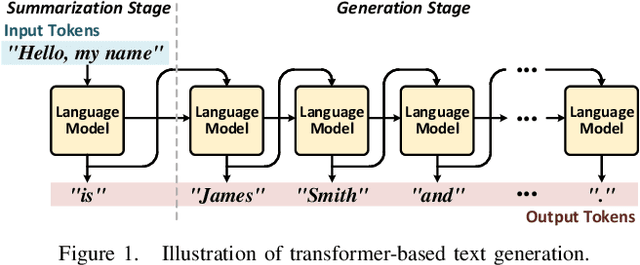
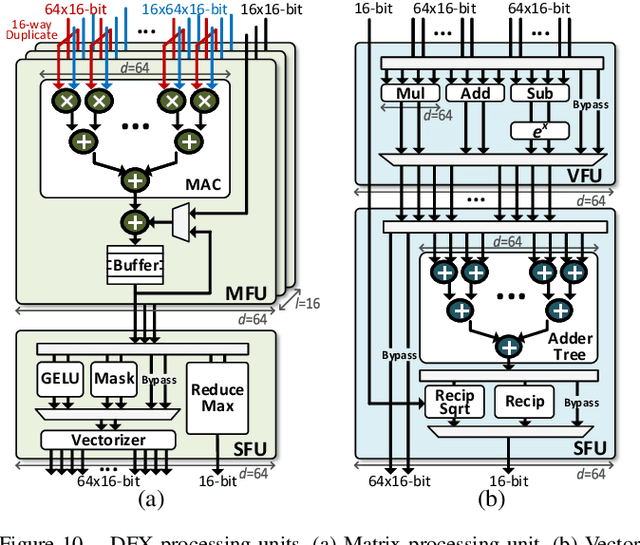
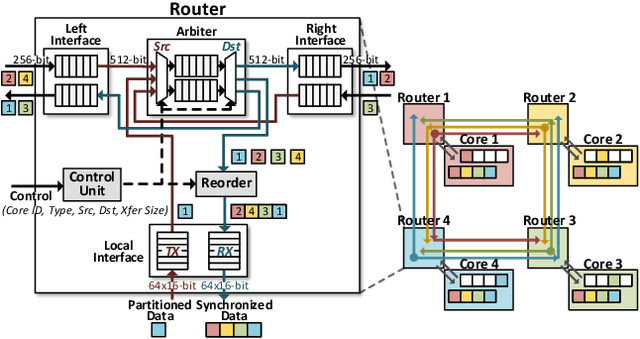
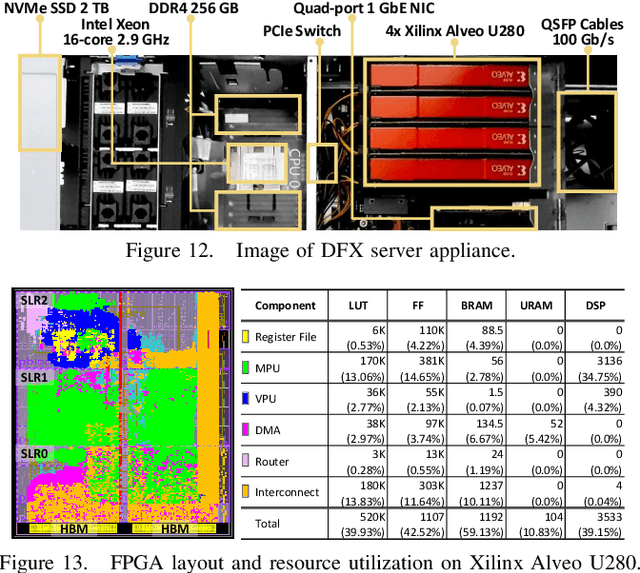
Transformer is a deep learning language model widely used for natural language processing (NLP) services in datacenters. Among transformer models, Generative Pre-trained Transformer (GPT) has achieved remarkable performance in text generation, or natural language generation (NLG), which needs the processing of a large input context in the summarization stage, followed by the generation stage that produces a single word at a time. The conventional platforms such as GPU are specialized for the parallel processing of large inputs in the summarization stage, but their performance significantly degrades in the generation stage due to its sequential characteristic. Therefore, an efficient hardware platform is required to address the high latency caused by the sequential characteristic of text generation. In this paper, we present DFX, a multi-FPGA acceleration appliance that executes GPT-2 model inference end-to-end with low latency and high throughput in both summarization and generation stages. DFX uses model parallelism and optimized dataflow that is model-and-hardware-aware for fast simultaneous workload execution among devices. Its compute cores operate on custom instructions and provide GPT-2 operations end-to-end. We implement the proposed hardware architecture on four Xilinx Alveo U280 FPGAs and utilize all of the channels of the high bandwidth memory (HBM) and the maximum number of compute resources for high hardware efficiency. DFX achieves 5.58x speedup and 3.99x energy efficiency over four NVIDIA V100 GPUs on the modern GPT-2 model. DFX is also 8.21x more cost-effective than the GPU appliance, suggesting that it is a promising solution for text generation workloads in cloud datacenters.