 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLong-Form Speech Generation with Spoken Language Models
Dec 24, 2024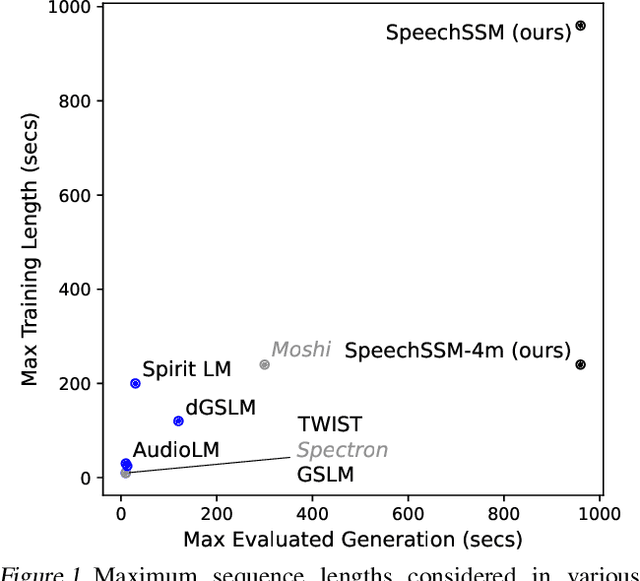
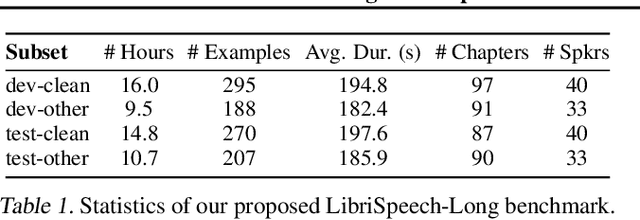

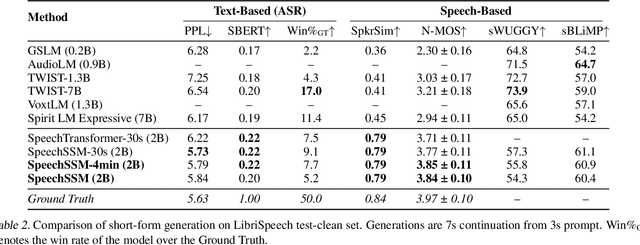
We consider the generative modeling of speech over multiple minutes, a requirement for long-form multimedia generation and audio-native voice assistants. However, current spoken language models struggle to generate plausible speech past tens of seconds, from high temporal resolution of speech tokens causing loss of coherence, to architectural issues with long-sequence training or extrapolation, to memory costs at inference time. With these considerations we propose SpeechSSM, the first speech language model to learn from and sample long-form spoken audio (e.g., 16 minutes of read or extemporaneous speech) in a single decoding session without text intermediates, based on recent advances in linear-time sequence modeling. Furthermore, to address growing challenges in spoken language evaluation, especially in this new long-form setting, we propose: new embedding-based and LLM-judged metrics; quality measurements over length and time; and a new benchmark for long-form speech processing and generation, LibriSpeech-Long. Speech samples and the dataset are released at https://google.github.io/tacotron/publications/speechssm/
Neural Target Speech Extraction: An Overview
Jan 31, 2023



Humans can listen to a target speaker even in challenging acoustic conditions that have noise, reverberation, and interfering speakers. This phenomenon is known as the cocktail-party effect. For decades, researchers have focused on approaching the listening ability of humans. One critical issue is handling interfering speakers because the target and non-target speech signals share similar characteristics, complicating their discrimination. Target speech/speaker extraction (TSE) isolates the speech signal of a target speaker from a mixture of several speakers with or without noises and reverberations using clues that identify the speaker in the mixture. Such clues might be a spatial clue indicating the direction of the target speaker, a video of the speaker's lips, or a pre-recorded enrollment utterance from which their voice characteristics can be derived. TSE is an emerging field of research that has received increased attention in recent years because it offers a practical approach to the cocktail-party problem and involves such aspects of signal processing as audio, visual, array processing, and deep learning. This paper focuses on recent neural-based approaches and presents an in-depth overview of TSE. We guide readers through the different major approaches, emphasizing the similarities among frameworks and discussing potential future directions.
On Word Error Rate Definitions and their Efficient Computation for Multi-Speaker Speech Recognition Systems
Nov 29, 2022We present a general framework to compute the word error rate (WER) of ASR systems that process recordings containing multiple speakers at their input and that produce multiple output word sequences (MIMO). Such ASR systems are typically required, e.g., for meeting transcription. We provide an efficient implementation based on a dynamic programming search in a multi-dimensional Levenshtein distance tensor under the constraint that a reference utterance must be matched consistently with one hypothesis output. This also results in an efficient implementation of the ORC WER which previously suffered from exponential complexity. We give an overview of commonly used WER definitions for multi-speaker scenarios and show that they are specializations of the above MIMO WER tuned to particular application scenarios. We conclude with a discussion of the pros and cons of the various WER definitions and a recommendation when to use which.
Utterance-by-utterance overlap-aware neural diarization with Graph-PIT
Jul 28, 2022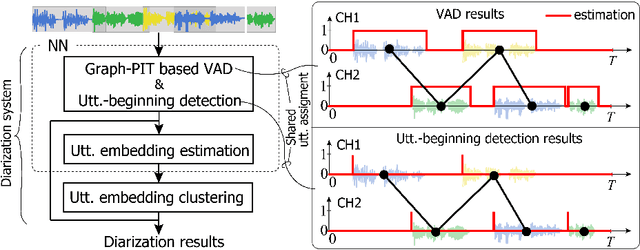
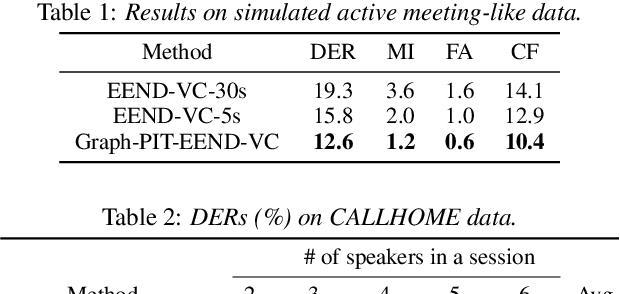
Recent speaker diarization studies showed that integration of end-to-end neural diarization (EEND) and clustering-based diarization is a promising approach for achieving state-of-the-art performance on various tasks. Such an approach first divides an observed signal into fixed-length segments, then performs {\it segment-level} local diarization based on an EEND module, and merges the segment-level results via clustering to form a final global diarization result. The segmentation is done to limit the number of speakers in each segment since the current EEND cannot handle a large number of speakers. In this paper, we argue that such an approach involving the segmentation has several issues; for example, it inevitably faces a dilemma that larger segment sizes increase both the context available for enhancing the performance and the number of speakers for the local EEND module to handle. To resolve such a problem, this paper proposes a novel framework that performs diarization without segmentation. However, it can still handle challenging data containing many speakers and a significant amount of overlapping speech. The proposed method can take an entire meeting for inference and perform {\it utterance-by-utterance} diarization that clusters utterance activities in terms of speakers. To this end, we leverage a neural network training scheme called Graph-PIT proposed recently for neural source separation. Experiments with simulated active-meeting-like data and CALLHOME data show the superiority of the proposed approach over the conventional methods.
Strategies to Improve Robustness of Target Speech Extraction to Enrollment Variations
Jun 16, 2022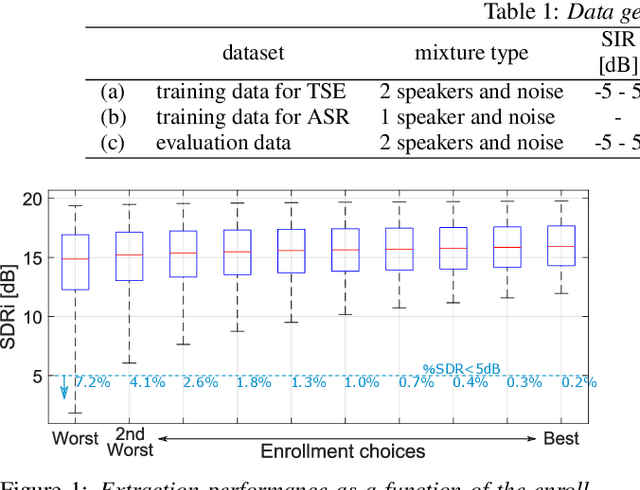
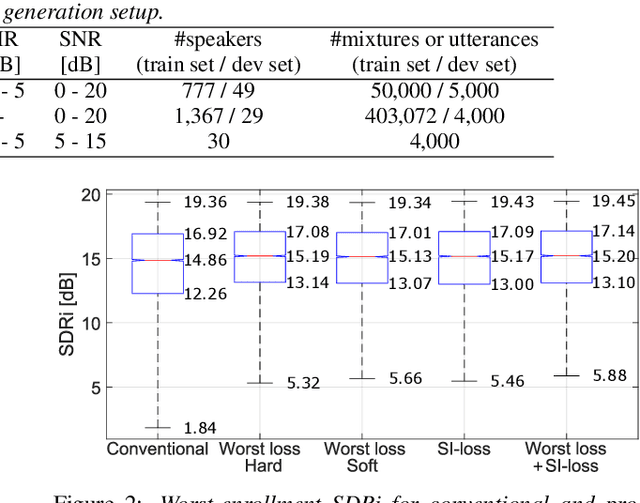
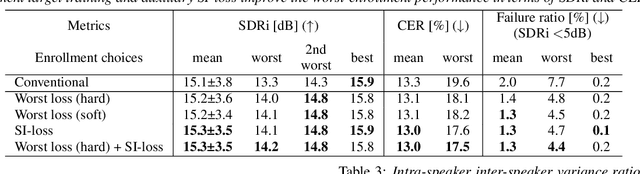
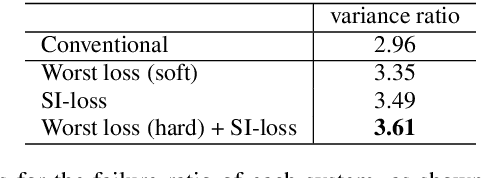
Target speech extraction is a technique to extract the target speaker's voice from mixture signals using a pre-recorded enrollment utterance that characterize the voice characteristics of the target speaker. One major difficulty of target speech extraction lies in handling variability in ``intra-speaker'' characteristics, i.e., characteristics mismatch between target speech and an enrollment utterance. While most conventional approaches focus on improving {\it average performance} given a set of enrollment utterances, here we propose to guarantee the {\it worst performance}, which we believe is of great practical importance. In this work, we propose an evaluation metric called worst-enrollment source-to-distortion ratio (SDR) to quantitatively measure the robustness towards enrollment variations. We also introduce a novel training scheme that aims at directly optimizing the worst-case performance by focusing on training with difficult enrollment cases where extraction does not perform well. In addition, we investigate the effectiveness of auxiliary speaker identification loss (SI-loss) as another way to improve robustness over enrollments. Experimental validation reveals the effectiveness of both worst-enrollment target training and SI-loss training to improve robustness against enrollment variations, by increasing speaker discriminability.
Listen only to me! How well can target speech extraction handle false alarms?
Apr 11, 2022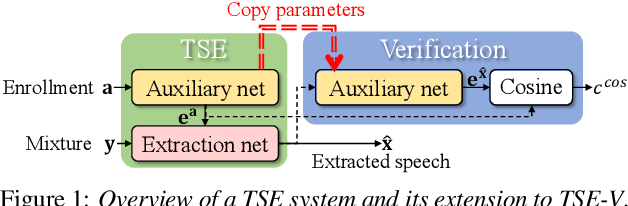
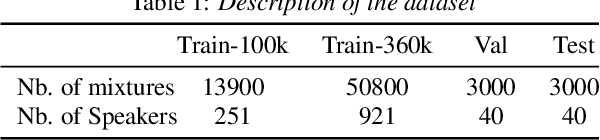
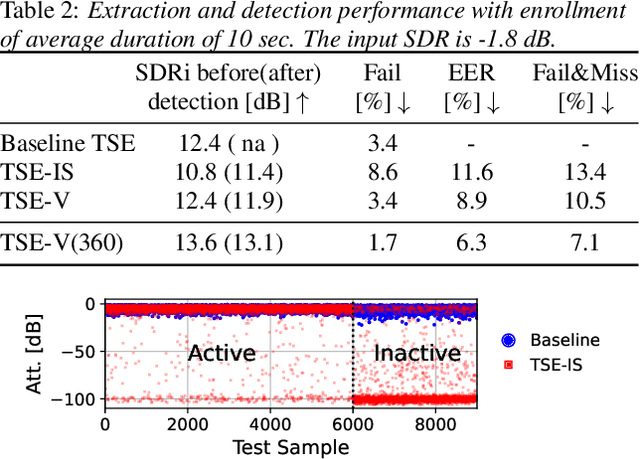
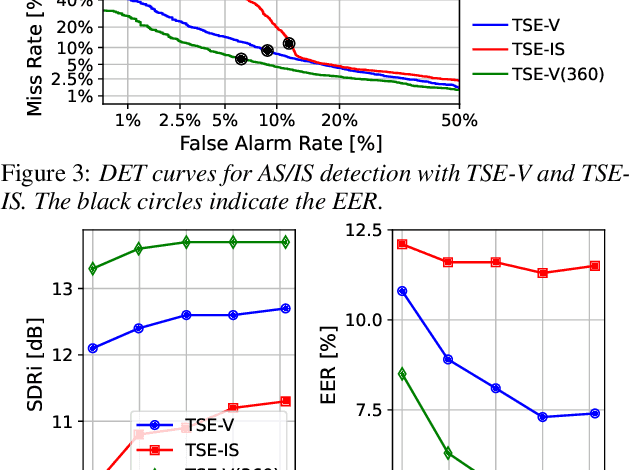
Target speech extraction (TSE) extracts the speech of a target speaker in a mixture given auxiliary clues characterizing the speaker, such as an enrollment utterance. TSE addresses thus the challenging problem of simultaneously performing separation and speaker identification. There has been much progress in extraction performance following the recent development of neural networks for speech enhancement and separation. Most studies have focused on processing mixtures where the target speaker is actively speaking. However, the target speaker is sometimes silent in practice, i.e., inactive speaker (IS). A typical TSE system will tend to output a signal in IS cases, causing false alarms. This is a severe problem for the practical deployment of TSE systems. This paper aims at understanding better how well TSE systems can handle IS cases. We consider two approaches to deal with IS, (1) training a system to directly output zero signals or (2) detecting IS with an extra speaker verification module. We perform an extensive experimental comparison of these schemes in terms of extraction performance and IS detection using the LibriMix dataset and reveal their pros and cons.
SoundBeam: Target sound extraction conditioned on sound-class labels and enrollment clues for increased performance and continuous learning
Apr 08, 2022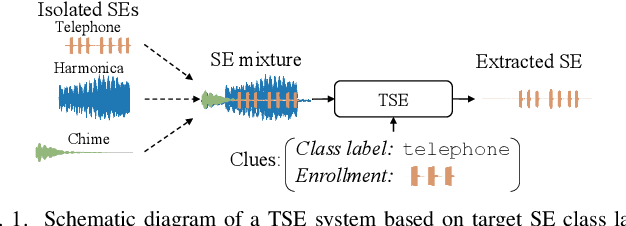
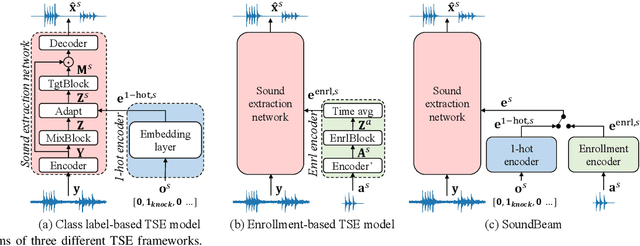
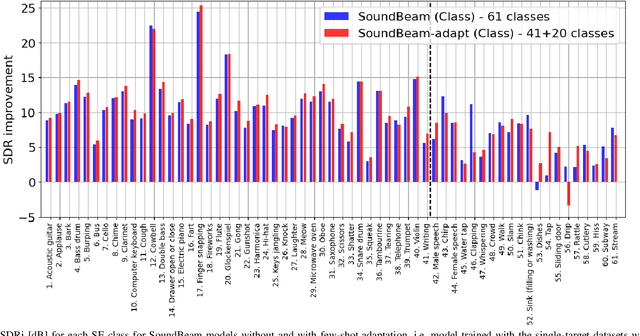
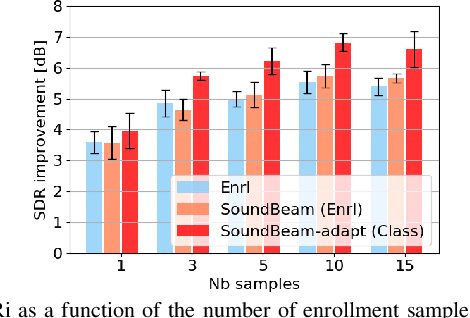
In many situations, we would like to hear desired sound events (SEs) while being able to ignore interference. Target sound extraction (TSE) aims at tackling this problem by estimating the sound of target SE classes in a mixture while suppressing all other sounds. We can achieve this with a neural network that extracts the target SEs by conditioning it on clues representing the target SE classes. Two types of clues have been proposed, i.e., target SE class labels and enrollment sound samples similar to the target sound. Systems based on SE class labels can directly optimize embedding vectors representing the SE classes, resulting in high extraction performance. However, extending these systems to the extraction of new SE classes not encountered during training is not easy. Enrollment-based approaches extract SEs by finding sounds in the mixtures that share similar characteristics to the enrollment. These approaches do not explicitly rely on SE class definitions and can thus handle new SE classes. In this paper, we introduce a TSE framework, SoundBeam, that combines the advantages of both approaches. We also perform an extensive evaluation of the different TSE schemes using synthesized and real mixtures, which shows the potential of SoundBeam.
Subjective intelligibility of speech sounds enhanced by ideal ratio mask via crowdsourced remote experiments with effective data screening
Mar 31, 2022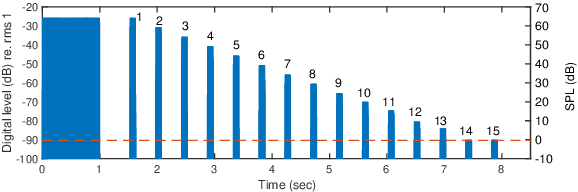
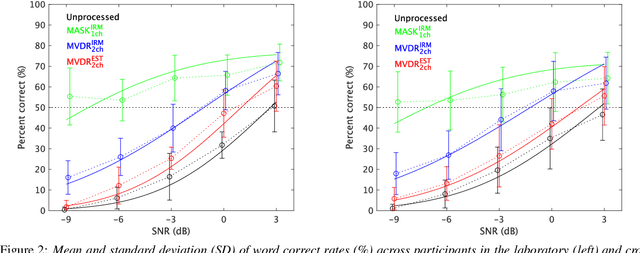
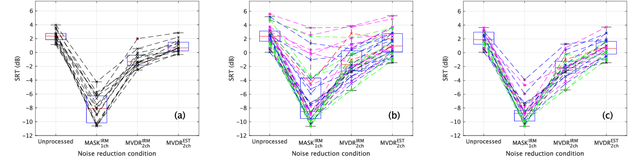
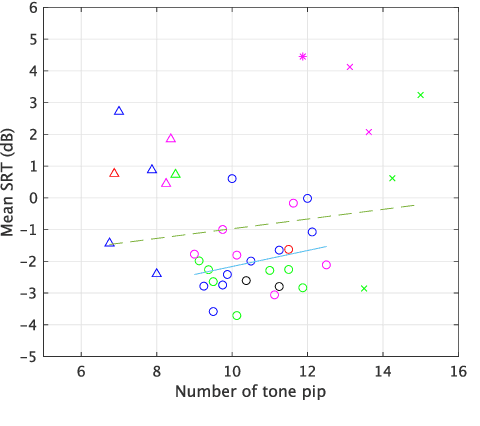
It is essential to perform speech intelligibility (SI) experiments with human listeners to evaluate the effectiveness of objective intelligibility measures. Recently crowdsourced remote testing has become popular to collect a massive amount and variety of data with relatively small cost and in short time. However, careful data screening is essential for attaining reliable SI data. We compared the results of laboratory and crowdsourced remote experiments to establish an effective data screening technique. We evaluated the SI of noisy speech sounds enhanced by a single-channel ideal ratio mask (IRM) and multi-channel mask-based beamformers. The results demonstrated that the SI scores were improved by these enhancement methods. In particular, the IRM-enhanced sounds were much better than the unprocessed and other enhanced sounds, indicating IRM enhancement may give the upper limit of speech enhancement performance. Moreover, tone pip tests, for which participants were asked to report the number of audible tone pips, reduced the variability of crowdsourced remote results so that the laboratory results became similar. Tone pip tests could be useful for future crowdsourced experiments because of their simplicity and effectiveness for data screening.
Tight integration of neural- and clustering-based diarization through deep unfolding of infinite Gaussian mixture model
Feb 14, 2022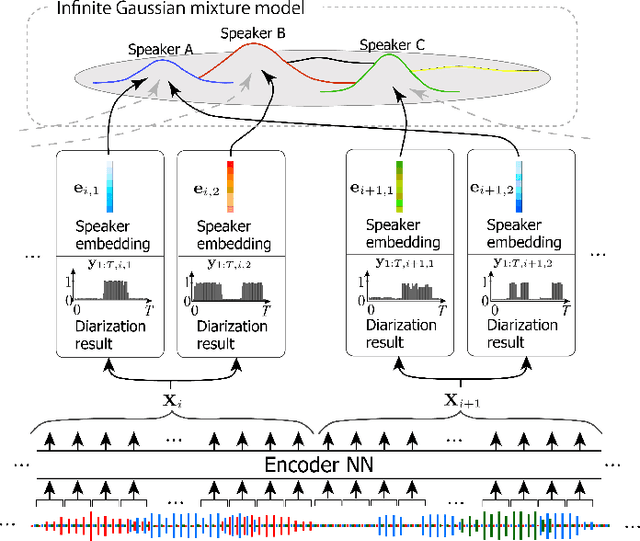

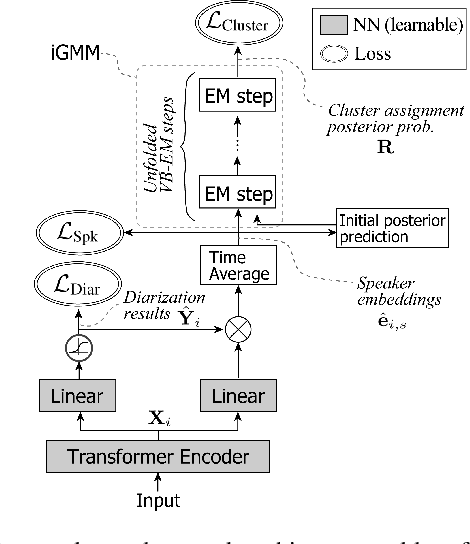
Speaker diarization has been investigated extensively as an important central task for meeting analysis. Recent trend shows that integration of end-to-end neural (EEND)-and clustering-based diarization is a promising approach to handle realistic conversational data containing overlapped speech with an arbitrarily large number of speakers, and achieved state-of-the-art results on various tasks. However, the approaches proposed so far have not realized {\it tight} integration yet, because the clustering employed therein was not optimal in any sense for clustering the speaker embeddings estimated by the EEND module. To address this problem, this paper introduces a {\it trainable} clustering algorithm into the integration framework, by deep-unfolding a non-parametric Bayesian model called the infinite Gaussian mixture model (iGMM). Specifically, the speaker embeddings are optimized during training such that it better fits iGMM clustering, based on a novel clustering loss based on Adjusted Rand Index (ARI). Experimental results based on CALLHOME data show that the proposed approach outperforms the conventional approach in terms of diarization error rate (DER), especially by substantially reducing speaker confusion errors, that indeed reflects the effectiveness of the proposed iGMM integration.
Learning to Enhance or Not: Neural Network-Based Switching of Enhanced and Observed Signals for Overlapping Speech Recognition
Jan 11, 2022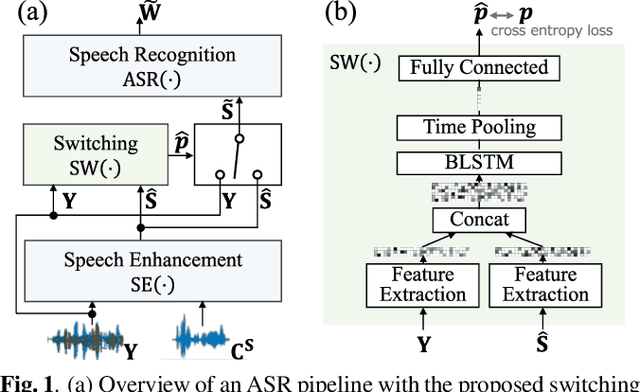
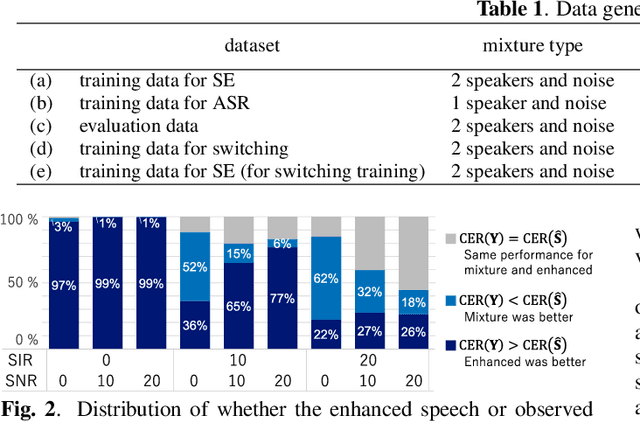
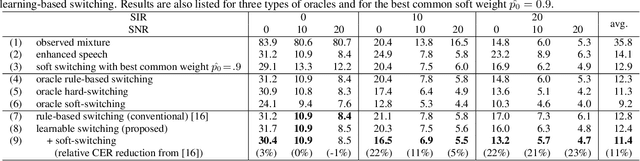
The combination of a deep neural network (DNN) -based speech enhancement (SE) front-end and an automatic speech recognition (ASR) back-end is a widely used approach to implement overlapping speech recognition. However, the SE front-end generates processing artifacts that can degrade the ASR performance. We previously found that such performance degradation can occur even under fully overlapping conditions, depending on the signal-to-interference ratio (SIR) and signal-to-noise ratio (SNR). To mitigate the degradation, we introduced a rule-based method to switch the ASR input between the enhanced and observed signals, which showed promising results. However, the rule's optimality was unclear because it was heuristically designed and based only on SIR and SNR values. In this work, we propose a DNN-based switching method that directly estimates whether ASR will perform better on the enhanced or observed signals. We also introduce soft-switching that computes a weighted sum of the enhanced and observed signals for ASR input, with weights given by the switching model's output posteriors. The proposed learning-based switching showed performance comparable to that of rule-based oracle switching. The soft-switching further improved the ASR performance and achieved a relative character error rate reduction of up to 23 % as compared with the conventional method.