 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoundBeam: Target sound extraction conditioned on sound-class labels and enrollment clues for increased performance and continuous learning
Apr 08, 2022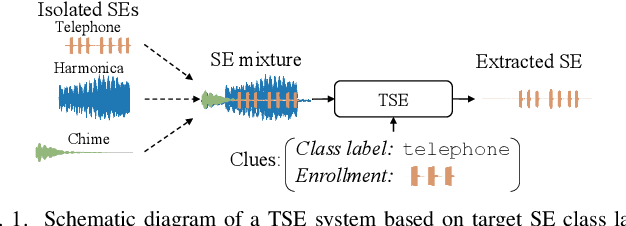
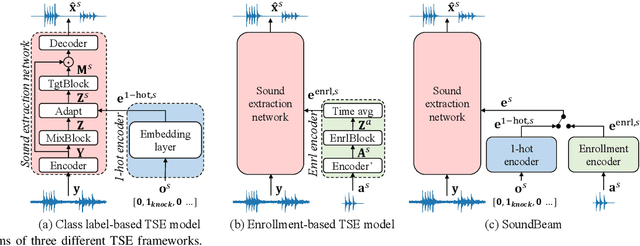
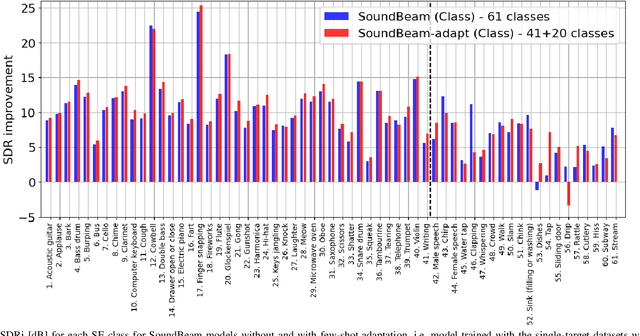
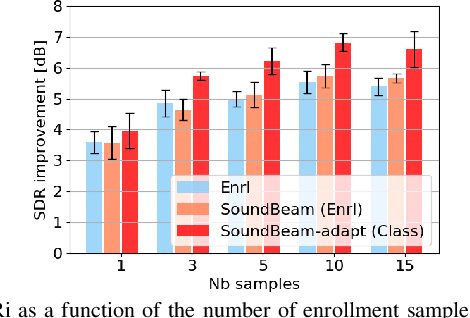
In many situations, we would like to hear desired sound events (SEs) while being able to ignore interference. Target sound extraction (TSE) aims at tackling this problem by estimating the sound of target SE classes in a mixture while suppressing all other sounds. We can achieve this with a neural network that extracts the target SEs by conditioning it on clues representing the target SE classes. Two types of clues have been proposed, i.e., target SE class labels and enrollment sound samples similar to the target sound. Systems based on SE class labels can directly optimize embedding vectors representing the SE classes, resulting in high extraction performance. However, extending these systems to the extraction of new SE classes not encountered during training is not easy. Enrollment-based approaches extract SEs by finding sounds in the mixtures that share similar characteristics to the enrollment. These approaches do not explicitly rely on SE class definitions and can thus handle new SE classes. In this paper, we introduce a TSE framework, SoundBeam, that combines the advantages of both approaches. We also perform an extensive evaluation of the different TSE schemes using synthesized and real mixtures, which shows the potential of SoundBeam.
Few-shot learning of new sound classes for target sound extraction
Jun 14, 2021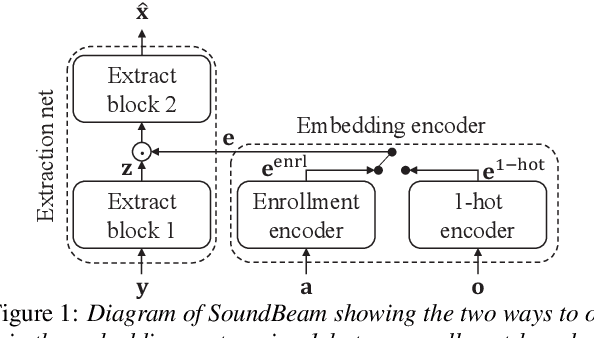

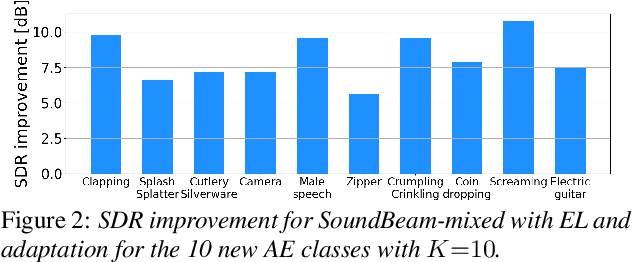
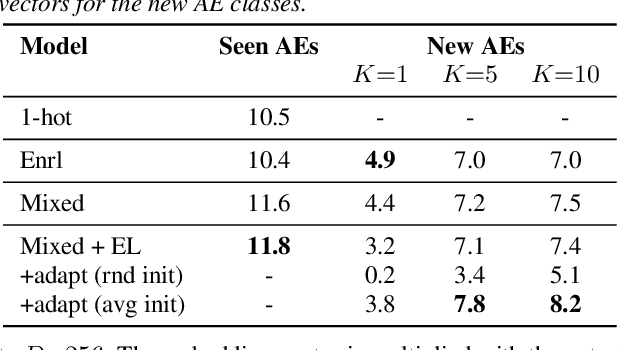
Target sound extraction consists of extracting the sound of a target acoustic event (AE) class from a mixture of AE sounds. It can be realized using a neural network that extracts the target sound conditioned on a 1-hot vector that represents the desired AE class. With this approach, embedding vectors associated with the AE classes are directly optimized for the extraction of sound classes seen during training. However, it is not easy to extend this framework to new AE classes, i.e. unseen during training. Recently, speech, music, or AE sound extraction based on enrollment audio of the desired sound offers the potential of extracting any target sound in a mixture given only a short audio signal of a similar sound. In this work, we propose combining 1-hot- and enrollment-based target sound extraction, allowing optimal performance for seen AE classes and simple extension to new classes. In experiments with synthesized sound mixtures generated with the Freesound Dataset (FSD) datasets, we demonstrate the benefit of the combined framework for both seen and new AE classes. Besides, we also propose adapting the embedding vectors obtained from a few enrollment audio samples (few-shot) to further improve performance on new classes.