 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTight integration of neural- and clustering-based diarization through deep unfolding of infinite Gaussian mixture model
Paper and Code
Feb 14, 2022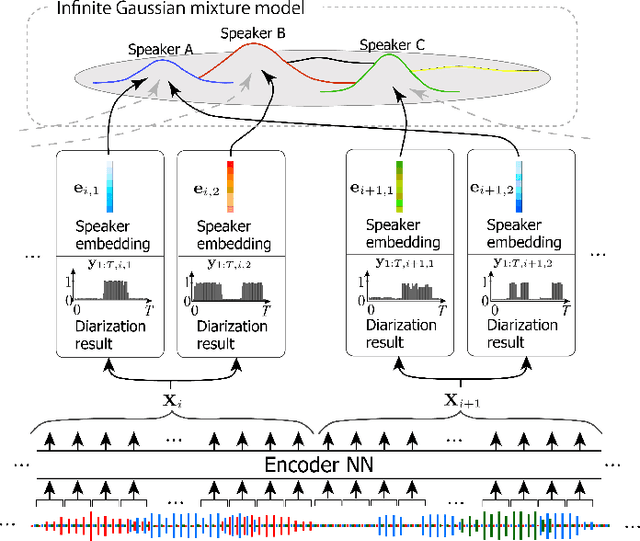

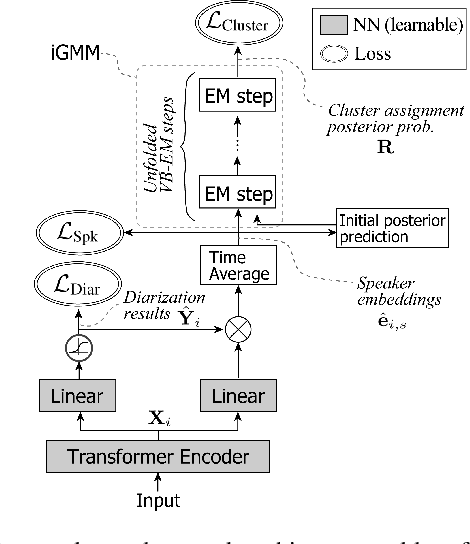
Speaker diarization has been investigated extensively as an important central task for meeting analysis. Recent trend shows that integration of end-to-end neural (EEND)-and clustering-based diarization is a promising approach to handle realistic conversational data containing overlapped speech with an arbitrarily large number of speakers, and achieved state-of-the-art results on various tasks. However, the approaches proposed so far have not realized {\it tight} integration yet, because the clustering employed therein was not optimal in any sense for clustering the speaker embeddings estimated by the EEND module. To address this problem, this paper introduces a {\it trainable} clustering algorithm into the integration framework, by deep-unfolding a non-parametric Bayesian model called the infinite Gaussian mixture model (iGMM). Specifically, the speaker embeddings are optimized during training such that it better fits iGMM clustering, based on a novel clustering loss based on Adjusted Rand Index (ARI). Experimental results based on CALLHOME data show that the proposed approach outperforms the conventional approach in terms of diarization error rate (DER), especially by substantially reducing speaker confusion errors, that indeed reflects the effectiveness of the proposed iGMM integration.