 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Enhance or Not: Neural Network-Based Switching of Enhanced and Observed Signals for Overlapping Speech Recognition
Paper and Code
Jan 11, 2022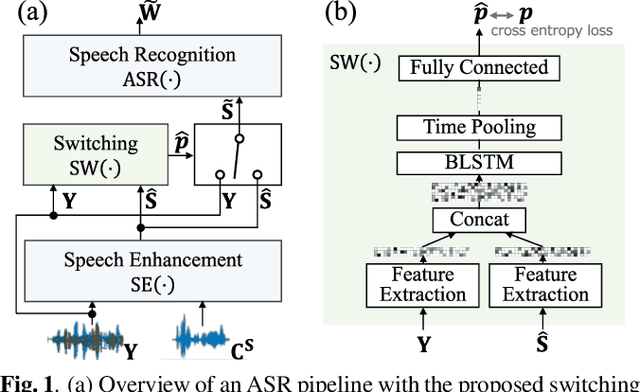
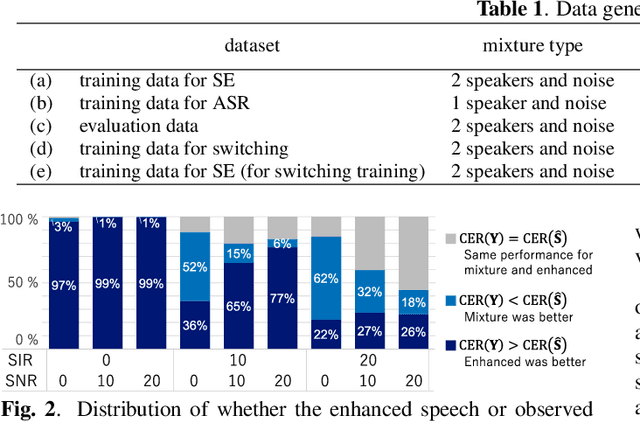
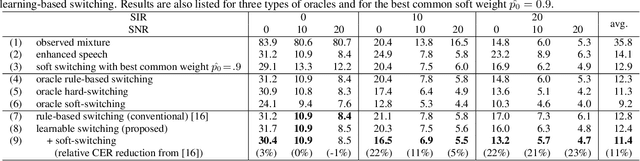
The combination of a deep neural network (DNN) -based speech enhancement (SE) front-end and an automatic speech recognition (ASR) back-end is a widely used approach to implement overlapping speech recognition. However, the SE front-end generates processing artifacts that can degrade the ASR performance. We previously found that such performance degradation can occur even under fully overlapping conditions, depending on the signal-to-interference ratio (SIR) and signal-to-noise ratio (SNR). To mitigate the degradation, we introduced a rule-based method to switch the ASR input between the enhanced and observed signals, which showed promising results. However, the rule's optimality was unclear because it was heuristically designed and based only on SIR and SNR values. In this work, we propose a DNN-based switching method that directly estimates whether ASR will perform better on the enhanced or observed signals. We also introduce soft-switching that computes a weighted sum of the enhanced and observed signals for ASR input, with weights given by the switching model's output posteriors. The proposed learning-based switching showed performance comparable to that of rule-based oracle switching. The soft-switching further improved the ASR performance and achieved a relative character error rate reduction of up to 23 % as compared with the conventional method.