 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeListen only to me! How well can target speech extraction handle false alarms?
Paper and Code
Apr 11, 2022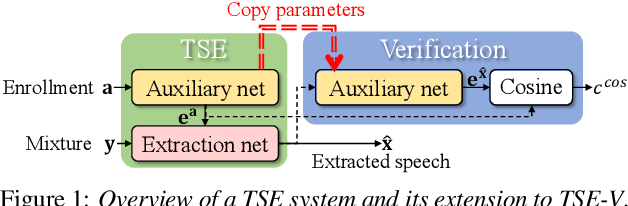
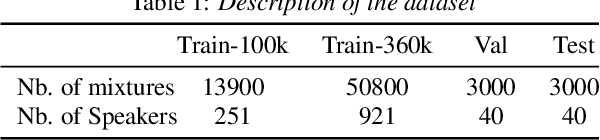
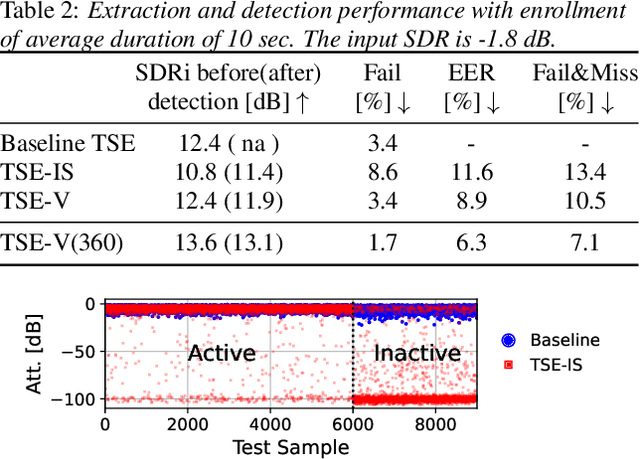
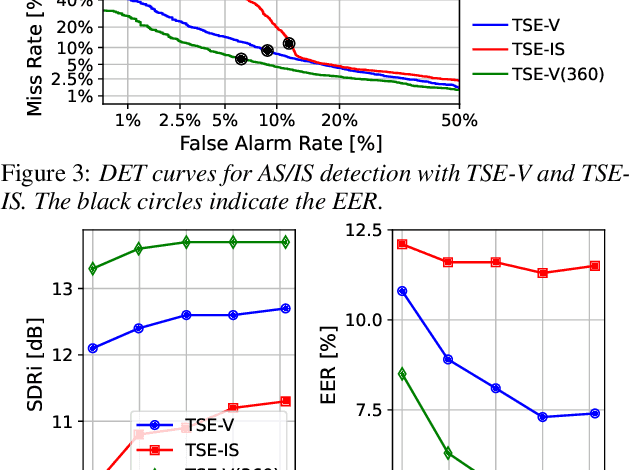
Target speech extraction (TSE) extracts the speech of a target speaker in a mixture given auxiliary clues characterizing the speaker, such as an enrollment utterance. TSE addresses thus the challenging problem of simultaneously performing separation and speaker identification. There has been much progress in extraction performance following the recent development of neural networks for speech enhancement and separation. Most studies have focused on processing mixtures where the target speaker is actively speaking. However, the target speaker is sometimes silent in practice, i.e., inactive speaker (IS). A typical TSE system will tend to output a signal in IS cases, causing false alarms. This is a severe problem for the practical deployment of TSE systems. This paper aims at understanding better how well TSE systems can handle IS cases. We consider two approaches to deal with IS, (1) training a system to directly output zero signals or (2) detecting IS with an extra speaker verification module. We perform an extensive experimental comparison of these schemes in terms of extraction performance and IS detection using the LibriMix dataset and reveal their pros and cons.