 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConversational Speech Naturalness Predictor
Mar 02, 2026Evaluation of conversational naturalness is essential for developing human-like speech agents. However, existing speech naturalness predictors are often designed to assess utterances from a single speaker, failing to capture conversation-level naturalness qualities. In this paper, we present a framework for an automatic naturalness predictor for two-speaker, multi-turn conversations. We first show that existing naturalness estimators have low, or sometimes even negative, correlations with conversational naturalness, based on conversational recordings annotated with human ratings. We then propose a dual-channel naturalness estimator, in which we investigate multiple pre-trained encoders with data augmentation. Our proposed model achieves substantially higher correlation with human judgments compared to existing naturalness predictors for both in-domain and out-of-domain conditions.
Textless Streaming Speech-to-Speech Translation using Semantic Speech Tokens
Oct 04, 2024



Cascaded speech-to-speech translation systems often suffer from the error accumulation problem and high latency, which is a result of cascaded modules whose inference delays accumulate. In this paper, we propose a transducer-based speech translation model that outputs discrete speech tokens in a low-latency streaming fashion. This approach eliminates the need for generating text output first, followed by machine translation (MT) and text-to-speech (TTS) systems. The produced speech tokens can be directly used to generate a speech signal with low latency by utilizing an acoustic language model (LM) to obtain acoustic tokens and an audio codec model to retrieve the waveform. Experimental results show that the proposed method outperforms other existing approaches and achieves state-of-the-art results for streaming translation in terms of BLEU, average latency, and BLASER 2.0 scores for multiple language pairs using the CVSS-C dataset as a benchmark.
Neural Target Speech Extraction: An Overview
Jan 31, 2023



Humans can listen to a target speaker even in challenging acoustic conditions that have noise, reverberation, and interfering speakers. This phenomenon is known as the cocktail-party effect. For decades, researchers have focused on approaching the listening ability of humans. One critical issue is handling interfering speakers because the target and non-target speech signals share similar characteristics, complicating their discrimination. Target speech/speaker extraction (TSE) isolates the speech signal of a target speaker from a mixture of several speakers with or without noises and reverberations using clues that identify the speaker in the mixture. Such clues might be a spatial clue indicating the direction of the target speaker, a video of the speaker's lips, or a pre-recorded enrollment utterance from which their voice characteristics can be derived. TSE is an emerging field of research that has received increased attention in recent years because it offers a practical approach to the cocktail-party problem and involves such aspects of signal processing as audio, visual, array processing, and deep learning. This paper focuses on recent neural-based approaches and presents an in-depth overview of TSE. We guide readers through the different major approaches, emphasizing the similarities among frameworks and discussing potential future directions.
Listen only to me! How well can target speech extraction handle false alarms?
Apr 11, 2022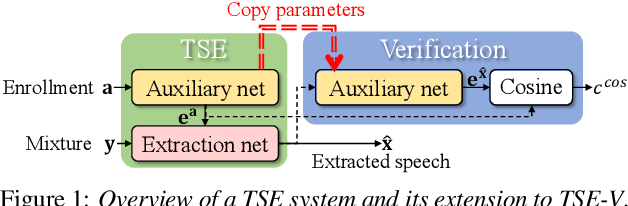
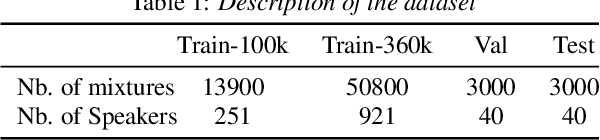
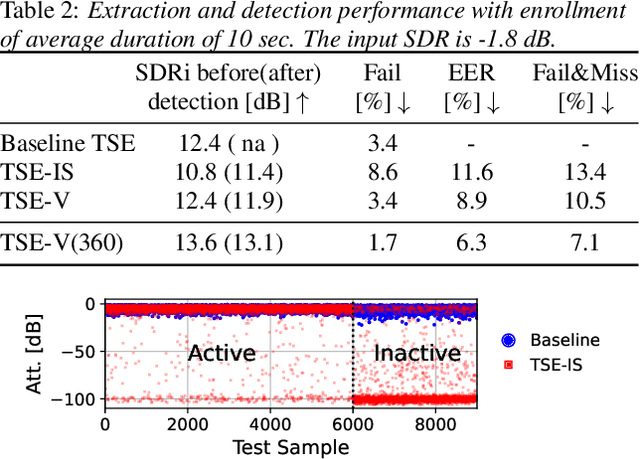
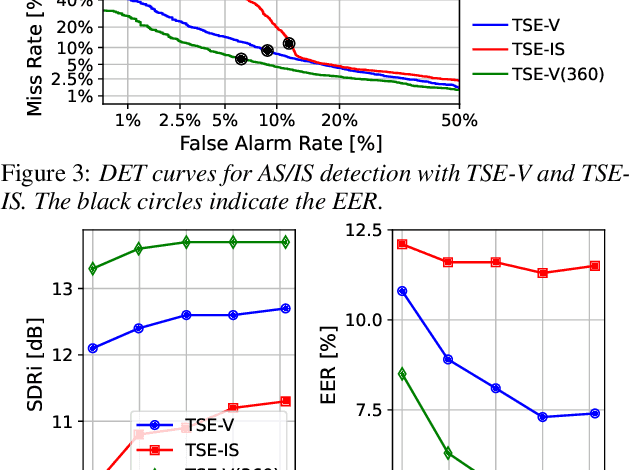
Target speech extraction (TSE) extracts the speech of a target speaker in a mixture given auxiliary clues characterizing the speaker, such as an enrollment utterance. TSE addresses thus the challenging problem of simultaneously performing separation and speaker identification. There has been much progress in extraction performance following the recent development of neural networks for speech enhancement and separation. Most studies have focused on processing mixtures where the target speaker is actively speaking. However, the target speaker is sometimes silent in practice, i.e., inactive speaker (IS). A typical TSE system will tend to output a signal in IS cases, causing false alarms. This is a severe problem for the practical deployment of TSE systems. This paper aims at understanding better how well TSE systems can handle IS cases. We consider two approaches to deal with IS, (1) training a system to directly output zero signals or (2) detecting IS with an extra speaker verification module. We perform an extensive experimental comparison of these schemes in terms of extraction performance and IS detection using the LibriMix dataset and reveal their pros and cons.
Speaker activity driven neural speech extraction
Feb 09, 2021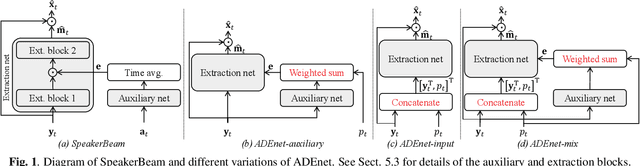


Target speech extraction, which extracts the speech of a target speaker in a mixture given auxiliary speaker clues, has recently received increased interest. Various clues have been investigated such as pre-recorded enrollment utterances, direction information, or video of the target speaker. In this paper, we explore the use of speaker activity information as an auxiliary clue for single-channel neural network-based speech extraction. We propose a speaker activity driven speech extraction neural network (ADEnet) and show that it can achieve performance levels competitive with enrollment-based approaches, without the need for pre-recordings. We further demonstrate the potential of the proposed approach for processing meeting-like recordings, where the speaker activity is obtained from a diarization system. We show that this simple yet practical approach can successfully extract speakers after diarization, which results in improved ASR performance, especially in high overlapping conditions, with a relative word error rate reduction of up to 25%.
Jointly Trained Transformers models for Spoken Language Translation
Apr 25, 2020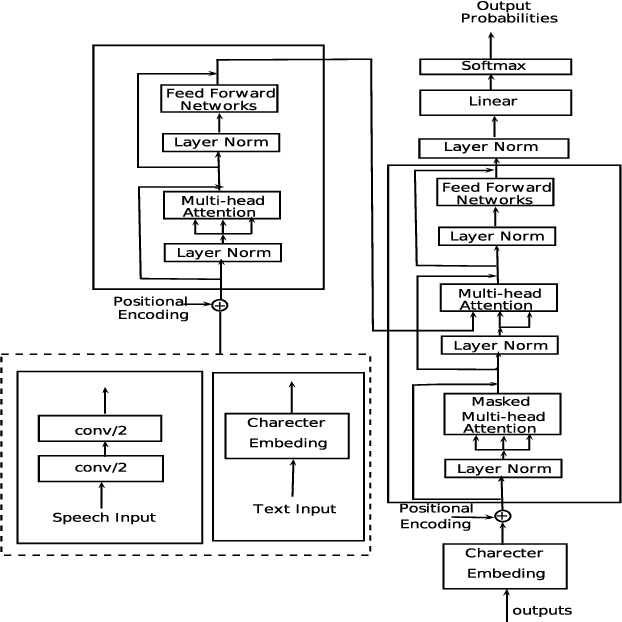
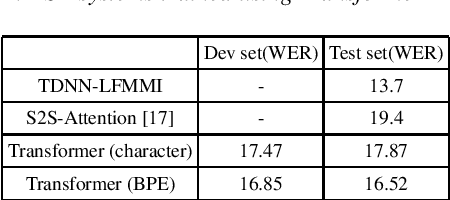
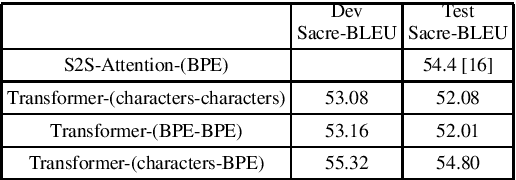
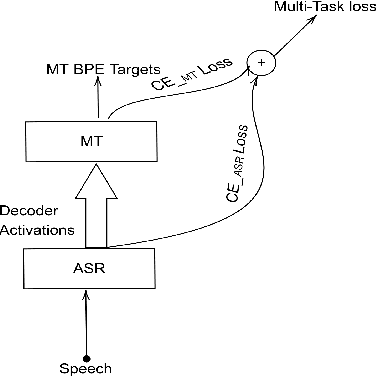
Conventional spoken language translation (SLT) systems are pipeline based systems, where we have an Automatic Speech Recognition (ASR) system to convert the modality of source from speech to text and a Machine Translation (MT) systems to translate source text to text in target language. Recent progress in the sequence-sequence architectures have reduced the performance gap between the pipeline based SLT systems (cascaded ASR-MT) and End-to-End approaches. Though End-to-End and cascaded ASR-MT systems are reaching to the comparable levels of performances, we can see a large performance gap using the ASR hypothesis and oracle text w.r.t MT models. This performance gap indicates that the MT systems are prone to large performance degradation due to noisy ASR hypothesis as opposed to oracle text transcript. In this work this degradation in the performance is reduced by creating an end to-end differentiable pipeline between the ASR and MT systems. In this work, we train SLT systems with ASR objective as an auxiliary loss and both the networks are connected through the neural hidden representations. This train ing would have an End-to-End differentiable path w.r.t to the final objective function as well as utilize the ASR objective for better performance of the SLT systems. This architecture has improved from BLEU from 36.8 to 44.5. Due to the Multi-task training the model also generates the ASR hypothesis which are used by a pre-trained MT model. Combining the proposed systems with the MT model has increased the BLEU score by 1. All the experiments are reported on English-Portuguese speech translation task using How2 corpus. The final BLEU score is on-par with the best speech translation system on How2 dataset with no additional training data and language model and much less parameters.
Improving speaker discrimination of target speech extraction with time-domain SpeakerBeam
Jan 23, 2020
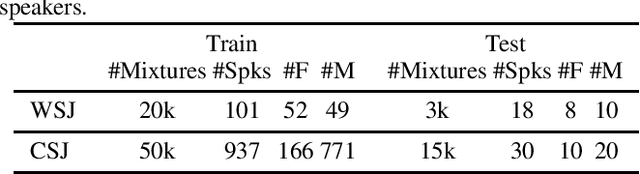
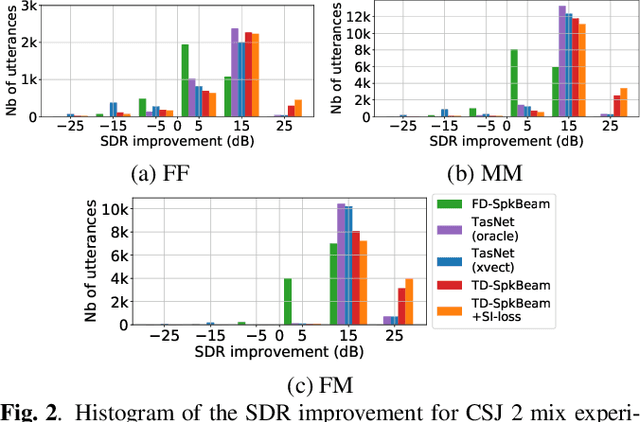

Target speech extraction, which extracts a single target source in a mixture given clues about the target speaker, has attracted increasing attention. We have recently proposed SpeakerBeam, which exploits an adaptation utterance of the target speaker to extract his/her voice characteristics that are then used to guide a neural network towards extracting speech of that speaker. SpeakerBeam presents a practical alternative to speech separation as it enables tracking speech of a target speaker across utterances, and achieves promising speech extraction performance. However, it sometimes fails when speakers have similar voice characteristics, such as in same-gender mixtures, because it is difficult to discriminate the target speaker from the interfering speakers. In this paper, we investigate strategies for improving the speaker discrimination capability of SpeakerBeam. First, we propose a time-domain implementation of SpeakerBeam similar to that proposed for a time-domain audio separation network (TasNet), which has achieved state-of-the-art performance for speech separation. Besides, we investigate (1) the use of spatial features to better discriminate speakers when microphone array recordings are available, (2) adding an auxiliary speaker identification loss for helping to learn more discriminative voice characteristics. We show experimentally that these strategies greatly improve speech extraction performance, especially for same-gender mixtures, and outperform TasNet in terms of target speech extraction.