 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting speech intelligibility in older adults using the Gammachirp Envelope Similarity Index, GESI
Apr 20, 2025We propose an objective intelligibility measure (OIM), called the Gammachirp Envelope Similarity Index (GESI), that can predict speech intelligibility (SI) in older adults. GESI is a bottom-up model based on psychoacoustic knowledge from the peripheral to the central auditory system and requires no training data. It computes the single SI metric using the gammachirp filterbank (GCFB), the modulation filterbank, and the extended cosine similarity measure. It takes into account not only the hearing level represented in the audiogram, but also the temporal processing characteristics captured by the temporal modulation transfer function (TMTF). To evaluate performance, SI experiments were conducted with older adults of various hearing levels using speech-in-noise with ideal speech enhancement on familiarity-controlled words. The prediction performance was compared with HASPIw2, which was developed for keyword SI prediction. The results showed that GESI predicted the subjective SI scores more accurately than HASPIw2. The effect of introducing TMTF into the GESI algorithm was not significant, indicating that more research is needed to know how to introduce temporal response characteristics into the OIM.
GESI: Gammachirp Envelope Similarity Index for Predicting Intelligibility of Simulated Hearing Loss Sounds
Oct 23, 2023We proposed a new objective intelligibility measure (OIM), called the Gammachirp Envelope Similarity Index (GESI), which can predict the speech intelligibility (SI) of simulated hearing loss (HL) sounds for normal hearing (NH) listeners. GESI is an intrusive method that computes the SI metric using the gammachirp filterbank (GCFB), the modulation filterbank, and the extended cosine similarity measure. GESI can accept the level asymmetry of the reference and test sounds and reflect the HI listener's hearing level as it appears on the audiogram. A unique feature of GESI is its ability to incorporate an individual participant's listening condition into the SI prediction. We conducted four SI experiments on male and female speech sounds in both laboratory and crowdsourced remote environments. We then evaluated GESI and the conventional OIMs, STOI, ESTOI, MBSTOI, and HASPI, for their ability to predict mean and individual SI values with and without the use of simulated HL sounds. GESI outperformed the other OIMs in all evaluations. STOI, ESTOI, and MBSTOI did not predict SI at all, even when using the simulated HL sounds. HASPI did not predict the difference between the laboratory and remote experiments on male speech sounds and the individual SI values. GESI may provide a first step toward SI prediction for individual HI listeners whose HL is caused solely by peripheral dysfunction.
Speech intelligibility of simulated hearing loss sounds and its prediction using the Gammachirp Envelope Similarity Index (GESI)
Jun 14, 2022
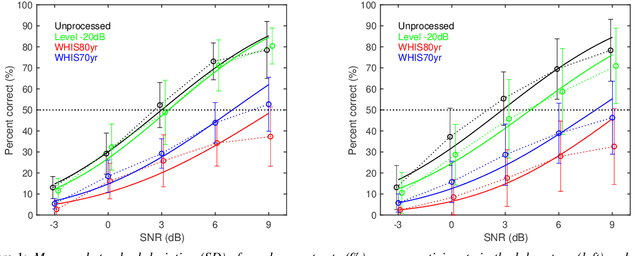
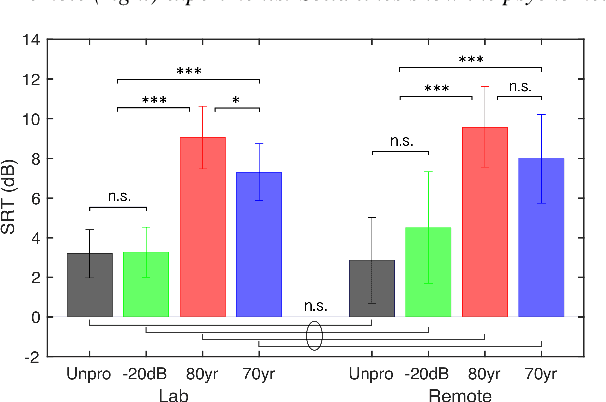
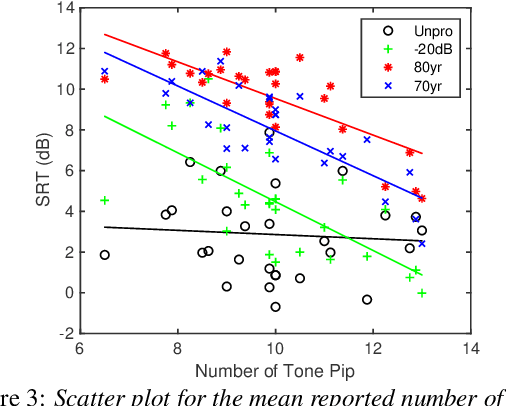
In the present study, speech intelligibility (SI) experiments were performed using simulated hearing loss (HL) sounds in laboratory and remote environments to clarify the effects of peripheral dysfunction. Noisy speech sounds were processed to simulate the average HL of 70- and 80-year-olds using Wadai Hearing Impairment Simulator (WHIS). These sounds were presented to normal hearing (NH) listeners whose cognitive function could be assumed to be normal. The results showed that the divergence was larger in the remote experiments than in the laboratory ones. However, the remote results could be equalized to the laboratory ones, mostly through data screening using the results of tone pip tests prepared on the experimental web page. In addition, a newly proposed objective intelligibility measure (OIM) called the Gammachirp Envelope Similarity Index (GESI) explained the psychometric functions in the laboratory and remote experiments fairly well. GESI has the potential to explain the SI of HI listeners by properly setting HL parameters.
Subjective intelligibility of speech sounds enhanced by ideal ratio mask via crowdsourced remote experiments with effective data screening
Mar 31, 2022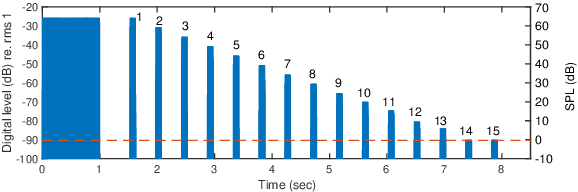
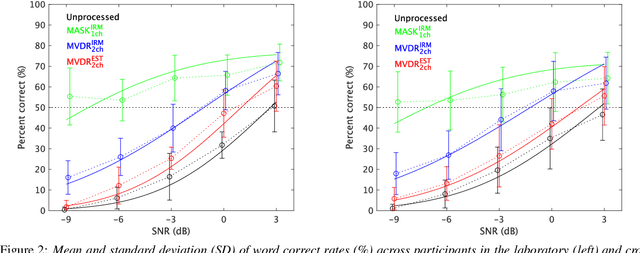
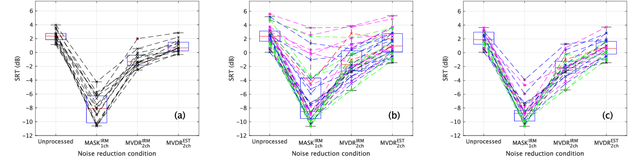
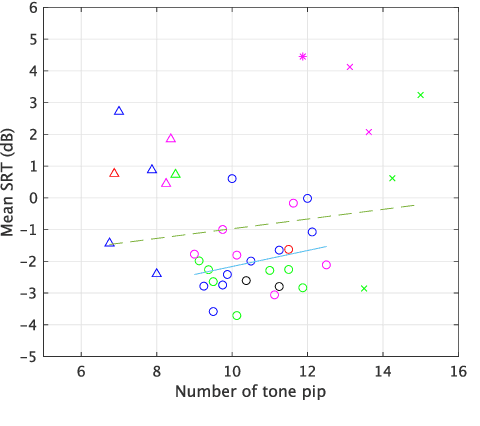
It is essential to perform speech intelligibility (SI) experiments with human listeners to evaluate the effectiveness of objective intelligibility measures. Recently crowdsourced remote testing has become popular to collect a massive amount and variety of data with relatively small cost and in short time. However, careful data screening is essential for attaining reliable SI data. We compared the results of laboratory and crowdsourced remote experiments to establish an effective data screening technique. We evaluated the SI of noisy speech sounds enhanced by a single-channel ideal ratio mask (IRM) and multi-channel mask-based beamformers. The results demonstrated that the SI scores were improved by these enhancement methods. In particular, the IRM-enhanced sounds were much better than the unprocessed and other enhanced sounds, indicating IRM enhancement may give the upper limit of speech enhancement performance. Moreover, tone pip tests, for which participants were asked to report the number of audible tone pips, reduced the variability of crowdsourced remote results so that the laboratory results became similar. Tone pip tests could be useful for future crowdsourced experiments because of their simplicity and effectiveness for data screening.
Comparison of remote experiments using crowdsourcing and laboratory experiments on speech intelligibility
Apr 17, 2021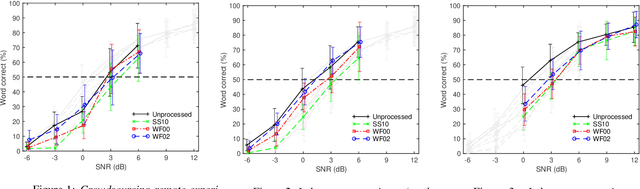
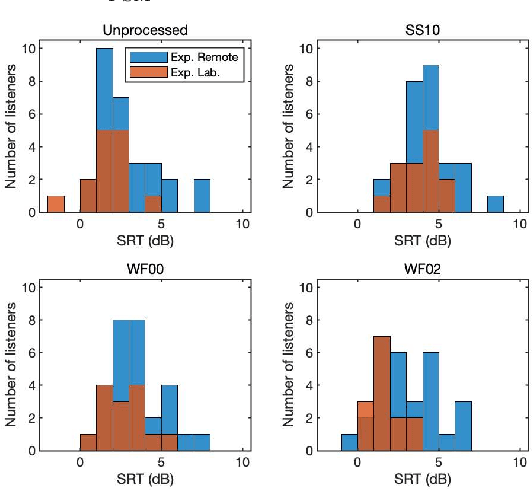
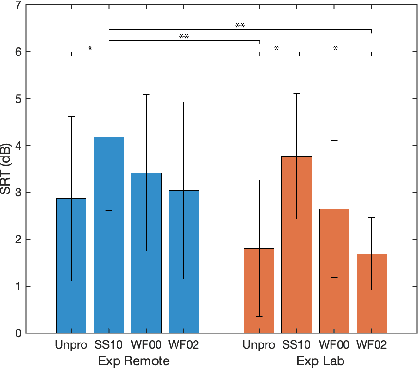
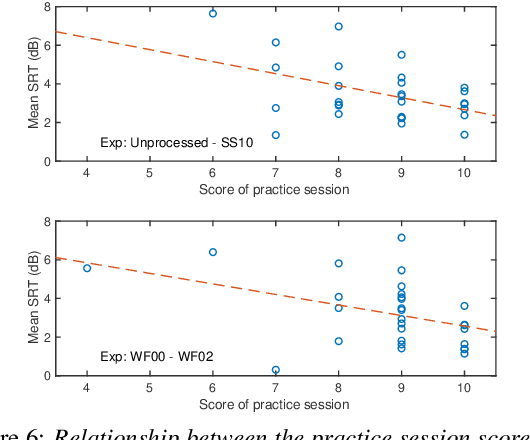
Many subjective experiments have been performed to develop objective speech intelligibility measures, but the novel coronavirus outbreak has made it very difficult to conduct experiments in a laboratory. One solution is to perform remote testing using crowdsourcing; however, because we cannot control the listening conditions, it is unclear whether the results are entirely reliable. In this study, we compared speech intelligibility scores obtained in remote and laboratory experiments. The results showed that the mean and standard deviation (SD) of the remote experiments' speech reception threshold (SRT) were higher than those of the laboratory experiments. However, the variance in the SRTs across the speech-enhancement conditions revealed similarities, implying that remote testing results may be as useful as laboratory experiments to develop an objective measure. We also show that the practice session scores correlate with the SRT values. This is a priori information before performing the main tests and would be useful for data screening to reduce the variability of the SRT distribution.