 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifference Vector Equalization for Robust Fine-tuning of Vision-Language Models
Nov 13, 2025



Contrastive pre-trained vision-language models, such as CLIP, demonstrate strong generalization abilities in zero-shot classification by leveraging embeddings extracted from image and text encoders. This paper aims to robustly fine-tune these vision-language models on in-distribution (ID) data without compromising their generalization abilities in out-of-distribution (OOD) and zero-shot settings. Current robust fine-tuning methods tackle this challenge by reusing contrastive learning, which was used in pre-training, for fine-tuning. However, we found that these methods distort the geometric structure of the embeddings, which plays a crucial role in the generalization of vision-language models, resulting in limited OOD and zero-shot performance. To address this, we propose Difference Vector Equalization (DiVE), which preserves the geometric structure during fine-tuning. The idea behind DiVE is to constrain difference vectors, each of which is obtained by subtracting the embeddings extracted from the pre-trained and fine-tuning models for the same data sample. By constraining the difference vectors to be equal across various data samples, we effectively preserve the geometric structure. Therefore, we introduce two losses: average vector loss (AVL) and pairwise vector loss (PVL). AVL preserves the geometric structure globally by constraining difference vectors to be equal to their weighted average. PVL preserves the geometric structure locally by ensuring a consistent multimodal alignment. Our experiments demonstrate that DiVE effectively preserves the geometric structure, achieving strong results across ID, OOD, and zero-shot metrics.
Joint Modeling of Big Five and HEXACO for Multimodal Apparent Personality-trait Recognition
Oct 16, 2025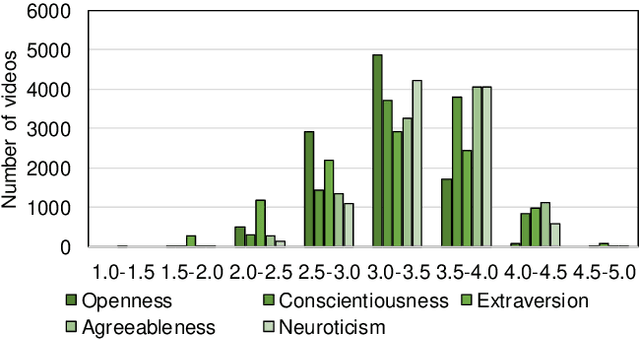



This paper proposes a joint modeling method of the Big Five, which has long been studied, and HEXACO, which has recently attracted attention in psychology, for automatically recognizing apparent personality traits from multimodal human behavior. Most previous studies have used the Big Five for multimodal apparent personality-trait recognition. However, no study has focused on apparent HEXACO which can evaluate an Honesty-Humility trait related to displaced aggression and vengefulness, social-dominance orientation, etc. In addition, the relationships between the Big Five and HEXACO when modeled by machine learning have not been clarified. We expect awareness of multimodal human behavior to improve by considering these relationships. The key advance of our proposed method is to optimize jointly recognizing the Big Five and HEXACO. Experiments using a self-introduction video dataset demonstrate that the proposed method can effectively recognize the Big Five and HEXACO.
Few-shot Personalization via In-Context Learning for Speech Emotion Recognition based on Speech-Language Model
Sep 10, 2025


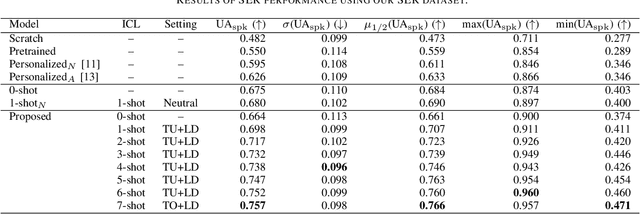
This paper proposes a personalization method for speech emotion recognition (SER) through in-context learning (ICL). Since the expression of emotions varies from person to person, speaker-specific adaptation is crucial for improving the SER performance. Conventional SER methods have been personalized using emotional utterances of a target speaker, but it is often difficult to prepare utterances corresponding to all emotion labels in advance. Our idea to overcome this difficulty is to obtain speaker characteristics by conditioning a few emotional utterances of the target speaker in ICL-based inference. ICL is a method to perform unseen tasks by conditioning a few input-output examples through inference in large language models (LLMs). We meta-train a speech-language model extended from the LLM to learn how to perform personalized SER via ICL. Experimental results using our newly collected SER dataset demonstrate that the proposed method outperforms conventional methods.
Adversarial Finetuning with Latent Representation Constraint to Mitigate Accuracy-Robustness Tradeoff
Aug 31, 2023



This paper addresses the tradeoff between standard accuracy on clean examples and robustness against adversarial examples in deep neural networks (DNNs). Although adversarial training (AT) improves robustness, it degrades the standard accuracy, thus yielding the tradeoff. To mitigate this tradeoff, we propose a novel AT method called ARREST, which comprises three components: (i) adversarial finetuning (AFT), (ii) representation-guided knowledge distillation (RGKD), and (iii) noisy replay (NR). AFT trains a DNN on adversarial examples by initializing its parameters with a DNN that is standardly pretrained on clean examples. RGKD and NR respectively entail a regularization term and an algorithm to preserve latent representations of clean examples during AFT. RGKD penalizes the distance between the representations of the standardly pretrained and AFT DNNs. NR switches input adversarial examples to nonadversarial ones when the representation changes significantly during AFT. By combining these components, ARREST achieves both high standard accuracy and robustness. Experimental results demonstrate that ARREST mitigates the tradeoff more effectively than previous AT-based methods do.
End-to-End Joint Target and Non-Target Speakers ASR
Jun 04, 2023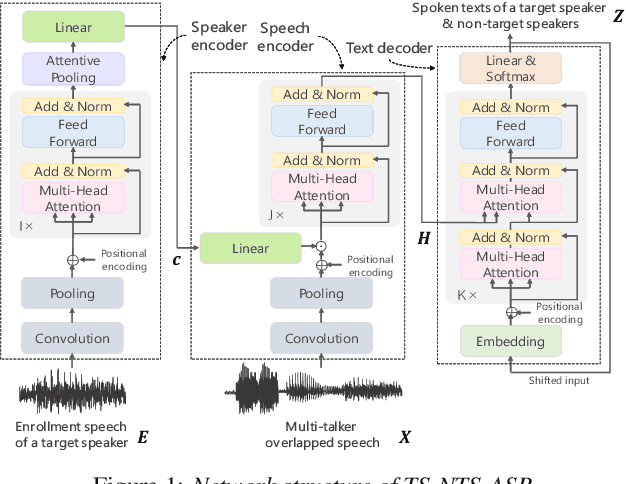


This paper proposes a novel automatic speech recognition (ASR) system that can transcribe individual speaker's speech while identifying whether they are target or non-target speakers from multi-talker overlapped speech. Target-speaker ASR systems are a promising way to only transcribe a target speaker's speech by enrolling the target speaker's information. However, in conversational ASR applications, transcribing both the target speaker's speech and non-target speakers' ones is often required to understand interactive information. To naturally consider both target and non-target speakers in a single ASR model, our idea is to extend autoregressive modeling-based multi-talker ASR systems to utilize the enrollment speech of the target speaker. Our proposed ASR is performed by recursively generating both textual tokens and tokens that represent target or non-target speakers. Our experiments demonstrate the effectiveness of our proposed method.
On the Use of Modality-Specific Large-Scale Pre-Trained Encoders for Multimodal Sentiment Analysis
Oct 28, 2022


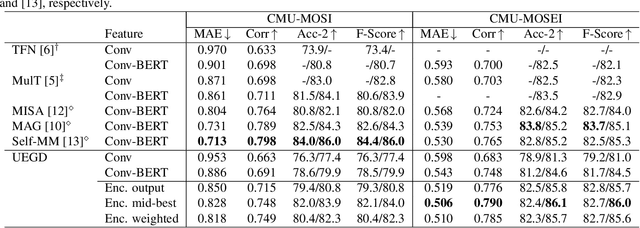
This paper investigates the effectiveness and implementation of modality-specific large-scale pre-trained encoders for multimodal sentiment analysis~(MSA). Although the effectiveness of pre-trained encoders in various fields has been reported, conventional MSA methods employ them for only linguistic modality, and their application has not been investigated. This paper compares the features yielded by large-scale pre-trained encoders with conventional heuristic features. One each of the largest pre-trained encoders publicly available for each modality are used; CLIP-ViT, WavLM, and BERT for visual, acoustic, and linguistic modalities, respectively. Experiments on two datasets reveal that methods with domain-specific pre-trained encoders attain better performance than those with conventional features in both unimodal and multimodal scenarios. We also find it better to use the outputs of the intermediate layers of the encoders than those of the output layer. The codes are available at https://github.com/ando-hub/MSA_Pretrain.
Speaker consistency loss and step-wise optimization for semi-supervised joint training of TTS and ASR using unpaired text data
Jul 11, 2022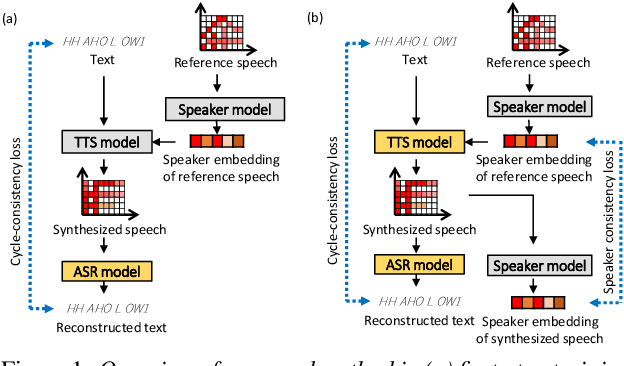
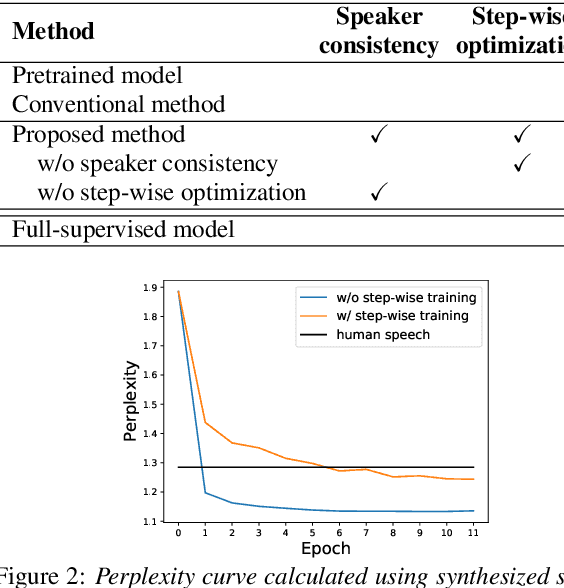
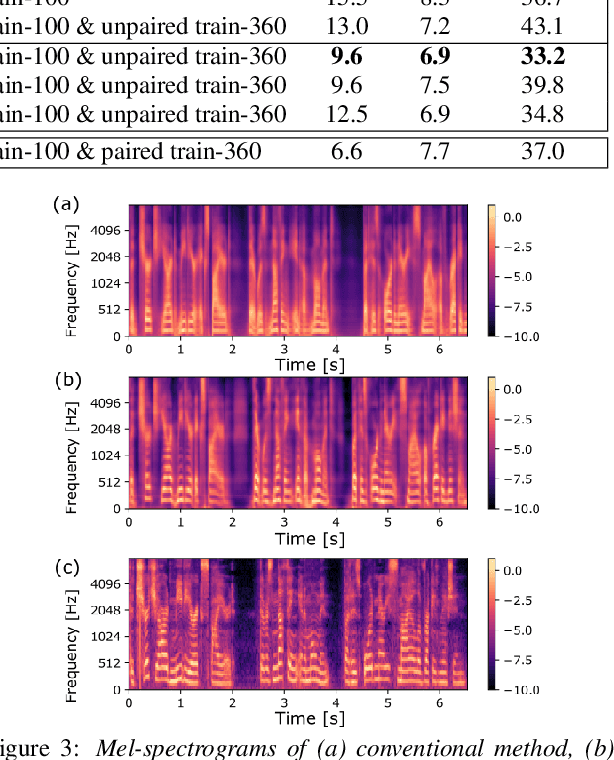
In this paper, we investigate the semi-supervised joint training of text to speech (TTS) and automatic speech recognition (ASR), where a small amount of paired data and a large amount of unpaired text data are available. Conventional studies form a cycle called the TTS-ASR pipeline, where the multispeaker TTS model synthesizes speech from text with a reference speech and the ASR model reconstructs the text from the synthesized speech, after which both models are trained with a cycle-consistency loss. However, the synthesized speech does not reflect the speaker characteristics of the reference speech and the synthesized speech becomes overly easy for the ASR model to recognize after training. This not only decreases the TTS model quality but also limits the ASR model improvement. To solve this problem, we propose improving the cycleconsistency-based training with a speaker consistency loss and step-wise optimization. The speaker consistency loss brings the speaker characteristics of the synthesized speech closer to that of the reference speech. In the step-wise optimization, we first freeze the parameter of the TTS model before both models are trained to avoid over-adaptation of the TTS model to the ASR model. Experimental results demonstrate the efficacy of the proposed method.
Strategies to Improve Robustness of Target Speech Extraction to Enrollment Variations
Jun 16, 2022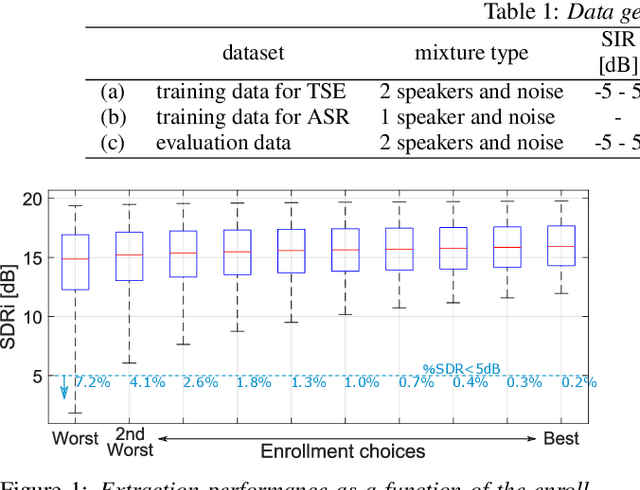
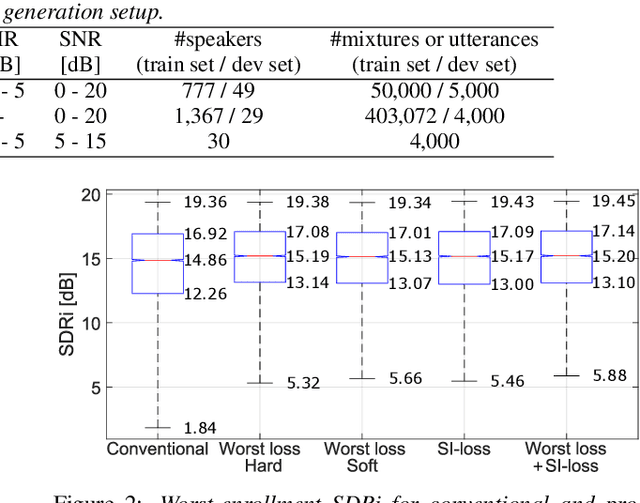
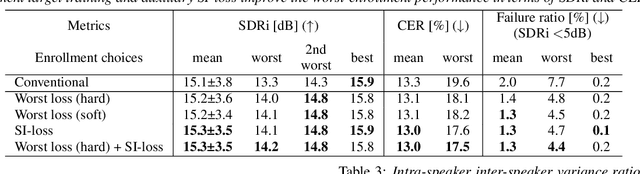
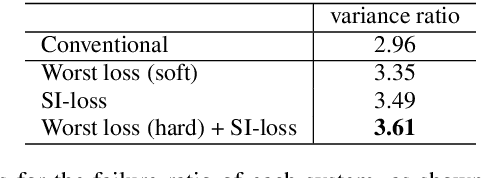
Target speech extraction is a technique to extract the target speaker's voice from mixture signals using a pre-recorded enrollment utterance that characterize the voice characteristics of the target speaker. One major difficulty of target speech extraction lies in handling variability in ``intra-speaker'' characteristics, i.e., characteristics mismatch between target speech and an enrollment utterance. While most conventional approaches focus on improving {\it average performance} given a set of enrollment utterances, here we propose to guarantee the {\it worst performance}, which we believe is of great practical importance. In this work, we propose an evaluation metric called worst-enrollment source-to-distortion ratio (SDR) to quantitatively measure the robustness towards enrollment variations. We also introduce a novel training scheme that aims at directly optimizing the worst-case performance by focusing on training with difficult enrollment cases where extraction does not perform well. In addition, we investigate the effectiveness of auxiliary speaker identification loss (SI-loss) as another way to improve robustness over enrollments. Experimental validation reveals the effectiveness of both worst-enrollment target training and SI-loss training to improve robustness against enrollment variations, by increasing speaker discriminability.
Utilizing Resource-Rich Language Datasets for End-to-End Scene Text Recognition in Resource-Poor Languages
Nov 24, 2021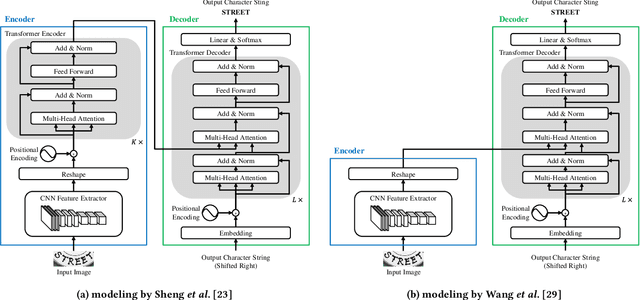
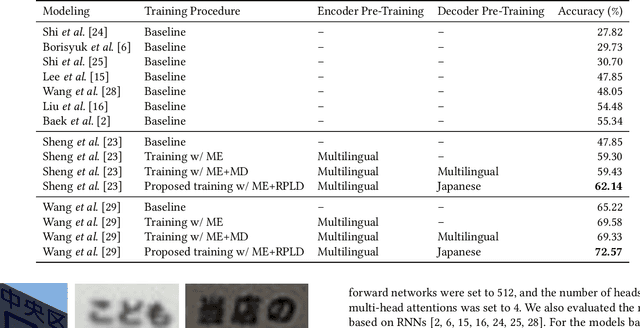
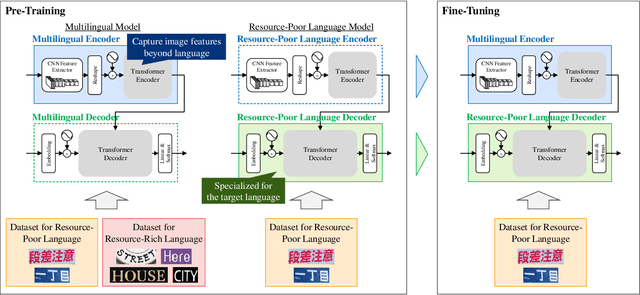
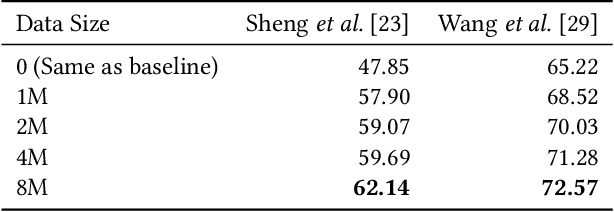
This paper presents a novel training method for end-to-end scene text recognition. End-to-end scene text recognition offers high recognition accuracy, especially when using the encoder-decoder model based on Transformer. To train a highly accurate end-to-end model, we need to prepare a large image-to-text paired dataset for the target language. However, it is difficult to collect this data, especially for resource-poor languages. To overcome this difficulty, our proposed method utilizes well-prepared large datasets in resource-rich languages such as English, to train the resource-poor encoder-decoder model. Our key idea is to build a model in which the encoder reflects knowledge of multiple languages while the decoder specializes in knowledge of just the resource-poor language. To this end, the proposed method pre-trains the encoder by using a multilingual dataset that combines the resource-poor language's dataset and the resource-rich language's dataset to learn language-invariant knowledge for scene text recognition. The proposed method also pre-trains the decoder by using the resource-poor language's dataset to make the decoder better suited to the resource-poor language. Experiments on Japanese scene text recognition using a small, publicly available dataset demonstrate the effectiveness of the proposed method.
Hierarchical Knowledge Distillation for Dialogue Sequence Labeling
Nov 22, 2021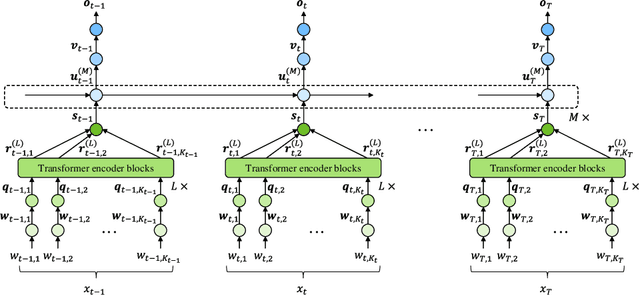
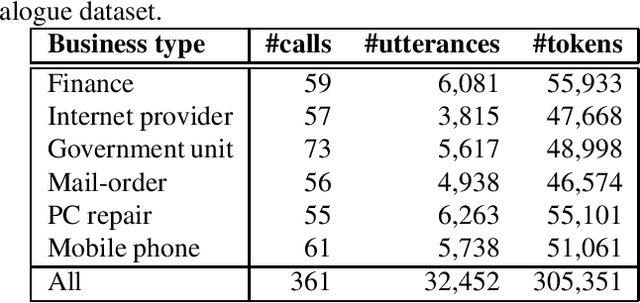
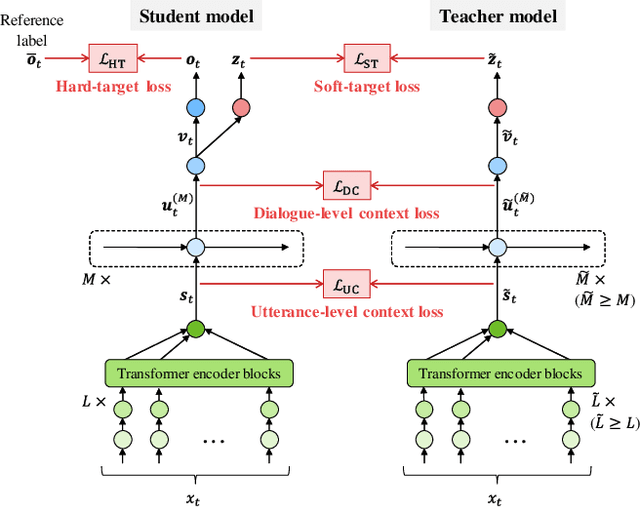
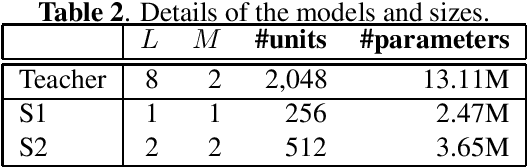
This paper presents a novel knowledge distillation method for dialogue sequence labeling. Dialogue sequence labeling is a supervised learning task that estimates labels for each utterance in the target dialogue document, and is useful for many applications such as dialogue act estimation. Accurate labeling is often realized by a hierarchically-structured large model consisting of utterance-level and dialogue-level networks that capture the contexts within an utterance and between utterances, respectively. However, due to its large model size, such a model cannot be deployed on resource-constrained devices. To overcome this difficulty, we focus on knowledge distillation which trains a small model by distilling the knowledge of a large and high performance teacher model. Our key idea is to distill the knowledge while keeping the complex contexts captured by the teacher model. To this end, the proposed method, hierarchical knowledge distillation, trains the small model by distilling not only the probability distribution of the label classification, but also the knowledge of utterance-level and dialogue-level contexts trained in the teacher model by training the model to mimic the teacher model's output in each level. Experiments on dialogue act estimation and call scene segmentation demonstrate the effectiveness of the proposed method.