 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUtilizing Resource-Rich Language Datasets for End-to-End Scene Text Recognition in Resource-Poor Languages
Paper and Code
Nov 24, 2021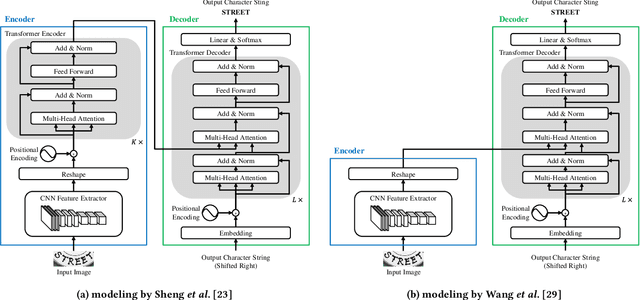
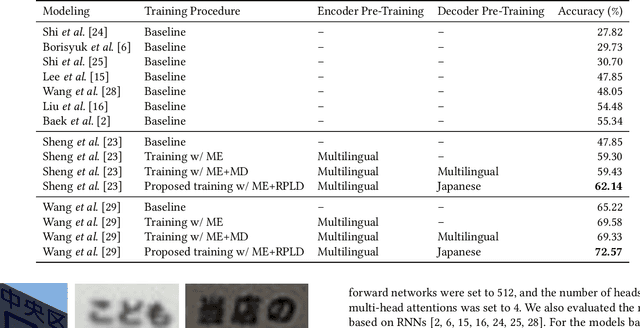
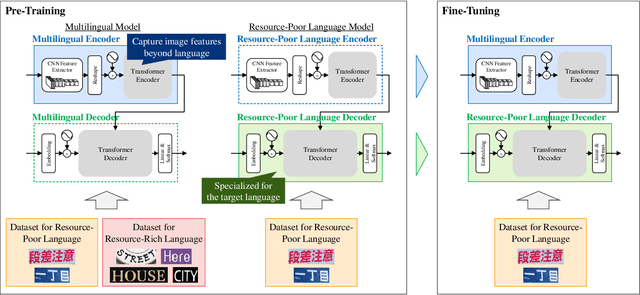
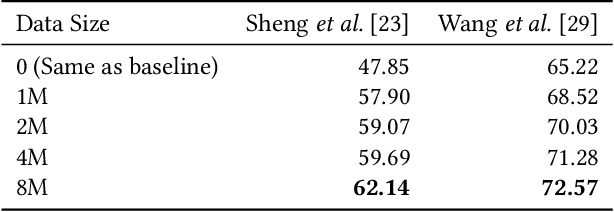
This paper presents a novel training method for end-to-end scene text recognition. End-to-end scene text recognition offers high recognition accuracy, especially when using the encoder-decoder model based on Transformer. To train a highly accurate end-to-end model, we need to prepare a large image-to-text paired dataset for the target language. However, it is difficult to collect this data, especially for resource-poor languages. To overcome this difficulty, our proposed method utilizes well-prepared large datasets in resource-rich languages such as English, to train the resource-poor encoder-decoder model. Our key idea is to build a model in which the encoder reflects knowledge of multiple languages while the decoder specializes in knowledge of just the resource-poor language. To this end, the proposed method pre-trains the encoder by using a multilingual dataset that combines the resource-poor language's dataset and the resource-rich language's dataset to learn language-invariant knowledge for scene text recognition. The proposed method also pre-trains the decoder by using the resource-poor language's dataset to make the decoder better suited to the resource-poor language. Experiments on Japanese scene text recognition using a small, publicly available dataset demonstrate the effectiveness of the proposed method.