 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Use of Modality-Specific Large-Scale Pre-Trained Encoders for Multimodal Sentiment Analysis
Paper and Code



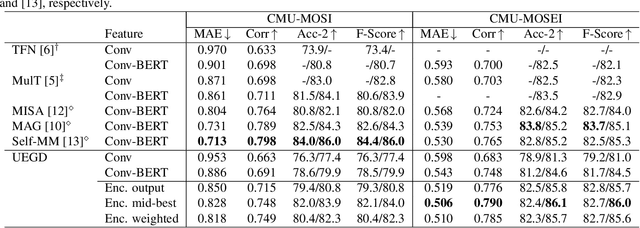
This paper investigates the effectiveness and implementation of modality-specific large-scale pre-trained encoders for multimodal sentiment analysis~(MSA). Although the effectiveness of pre-trained encoders in various fields has been reported, conventional MSA methods employ them for only linguistic modality, and their application has not been investigated. This paper compares the features yielded by large-scale pre-trained encoders with conventional heuristic features. One each of the largest pre-trained encoders publicly available for each modality are used; CLIP-ViT, WavLM, and BERT for visual, acoustic, and linguistic modalities, respectively. Experiments on two datasets reveal that methods with domain-specific pre-trained encoders attain better performance than those with conventional features in both unimodal and multimodal scenarios. We also find it better to use the outputs of the intermediate layers of the encoders than those of the output layer. The codes are available at https://github.com/ando-hub/MSA_Pretrain.