 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-End Rich Transcription-Style Automatic Speech Recognition with Semi-Supervised Learning
Paper and Code
Jul 07, 2021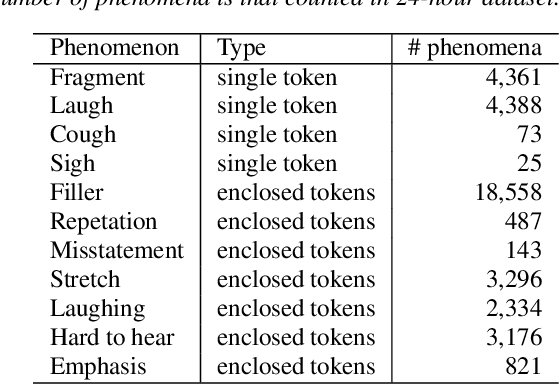
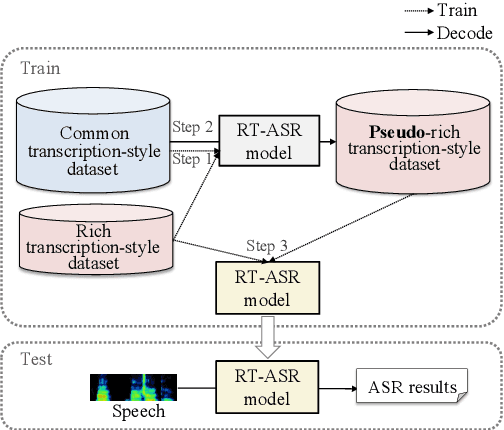
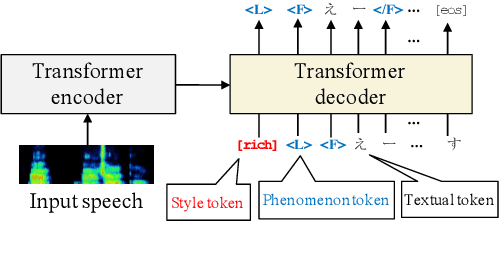
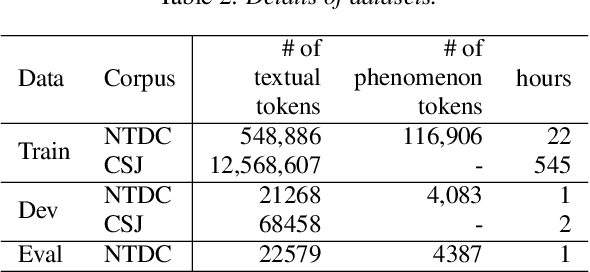
We propose a semi-supervised learning method for building end-to-end rich transcription-style automatic speech recognition (RT-ASR) systems from small-scale rich transcription-style and large-scale common transcription-style datasets. In spontaneous speech tasks, various speech phenomena such as fillers, word fragments, laughter and coughs, etc. are often included. While common transcriptions do not give special awareness to these phenomena, rich transcriptions explicitly convert them into special phenomenon tokens as well as textual tokens. In previous studies, the textual and phenomenon tokens were simultaneously estimated in an end-to-end manner. However, it is difficult to build accurate RT-ASR systems because large-scale rich transcription-style datasets are often unavailable. To solve this problem, our training method uses a limited rich transcription-style dataset and common transcription-style dataset simultaneously. The Key process in our semi-supervised learning is to convert the common transcription-style dataset into a pseudo-rich transcription-style dataset. To this end, we introduce style tokens which control phenomenon tokens are generated or not into transformer-based autoregressive modeling. We use this modeling for generating the pseudo-rich transcription-style datasets and for building RT-ASR system from the pseudo and original datasets. Our experiments on spontaneous ASR tasks showed the effectiveness of the proposed method.