 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Modal Transformer-Based Neural Correction Models for Automatic Speech Recognition
Paper and Code
Jul 04, 2021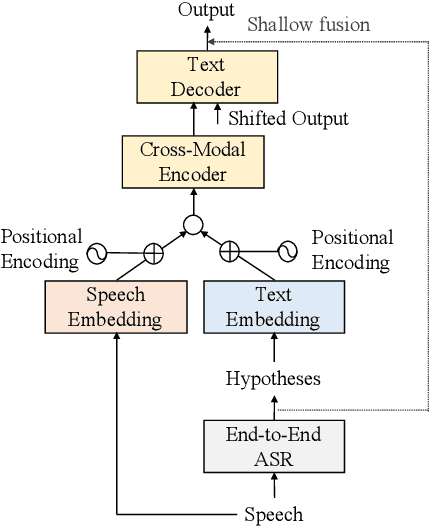
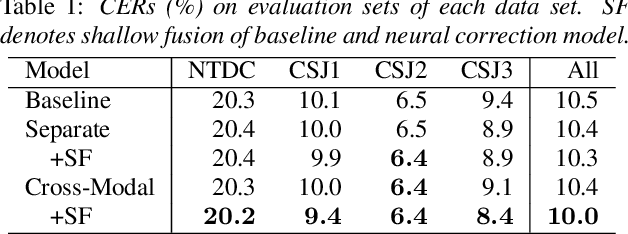
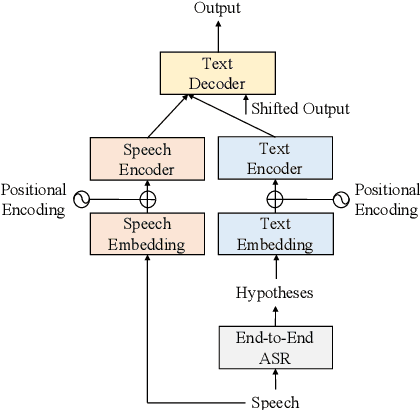
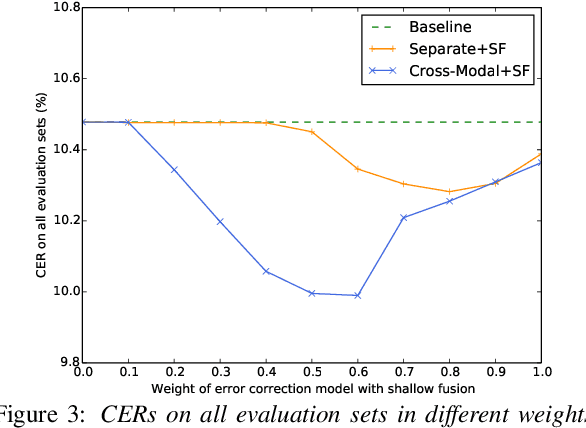
We propose a cross-modal transformer-based neural correction models that refines the output of an automatic speech recognition (ASR) system so as to exclude ASR errors. Generally, neural correction models are composed of encoder-decoder networks, which can directly model sequence-to-sequence mapping problems. The most successful method is to use both input speech and its ASR output text as the input contexts for the encoder-decoder networks. However, the conventional method cannot take into account the relationships between these two different modal inputs because the input contexts are separately encoded for each modal. To effectively leverage the correlated information between the two different modal inputs, our proposed models encode two different contexts jointly on the basis of cross-modal self-attention using a transformer. We expect that cross-modal self-attention can effectively capture the relationships between two different modals for refining ASR hypotheses. We also introduce a shallow fusion technique to efficiently integrate the first-pass ASR model and our proposed neural correction model. Experiments on Japanese natural language ASR tasks demonstrated that our proposed models achieve better ASR performance than conventional neural correction models.