 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking LayerNorm in Image Restoration Transformers
Apr 09, 2025This work investigates abnormal feature behaviors observed in image restoration (IR) Transformers. Specifically, we identify two critical issues: feature entropy becoming excessively small and feature magnitudes diverging up to a million-fold scale. We pinpoint the root cause to the per-token normalization aspect of conventional LayerNorm, which disrupts essential spatial correlations and internal feature statistics. To address this, we propose a simple normalization strategy tailored for IR Transformers. Our approach applies normalization across the entire spatio-channel dimension, effectively preserving spatial correlations. Additionally, we introduce an input-adaptive rescaling method that aligns feature statistics to the unique statistical requirements of each input. Experimental results verify that this combined strategy effectively resolves feature divergence, significantly enhancing both the stability and performance of IR Transformers across various IR tasks.
Fine-Tuning Visual Autoregressive Models for Subject-Driven Generation
Apr 03, 2025Recent advances in text-to-image generative models have enabled numerous practical applications, including subject-driven generation, which fine-tunes pretrained models to capture subject semantics from only a few examples. While diffusion-based models produce high-quality images, their extensive denoising steps result in significant computational overhead, limiting real-world applicability. Visual autoregressive~(VAR) models, which predict next-scale tokens rather than spatially adjacent ones, offer significantly faster inference suitable for practical deployment. In this paper, we propose the first VAR-based approach for subject-driven generation. However, na\"{\i}ve fine-tuning VAR leads to computational overhead, language drift, and reduced diversity. To address these challenges, we introduce selective layer tuning to reduce complexity and prior distillation to mitigate language drift. Additionally, we found that the early stages have a greater influence on the generation of subject than the latter stages, which merely synthesize local details. Based on this finding, we propose scale-wise weighted tuning, which prioritizes coarser resolutions for promoting the model to focus on the subject-relevant information instead of local details. Extensive experiments validate that our method significantly outperforms diffusion-based baselines across various metrics and demonstrates its practical usage.
Diversity-aware Channel Pruning for StyleGAN Compression
Mar 20, 2024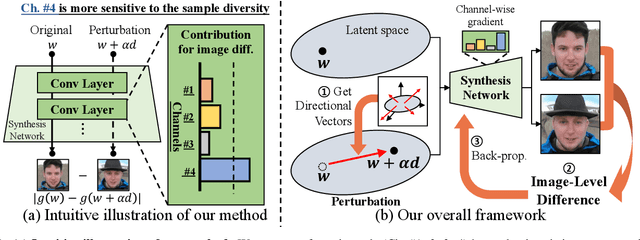
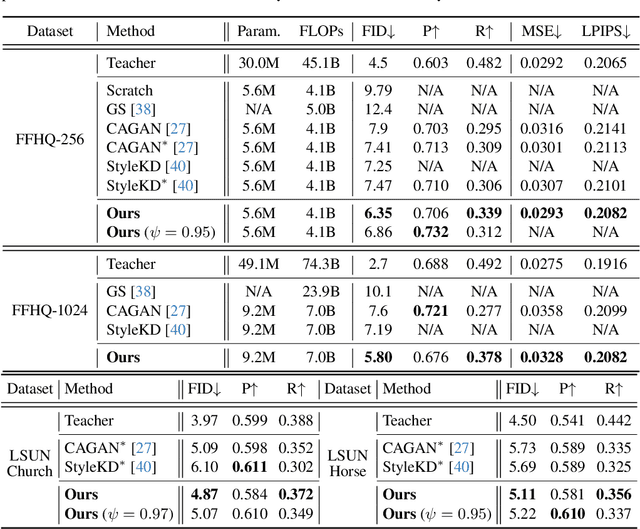
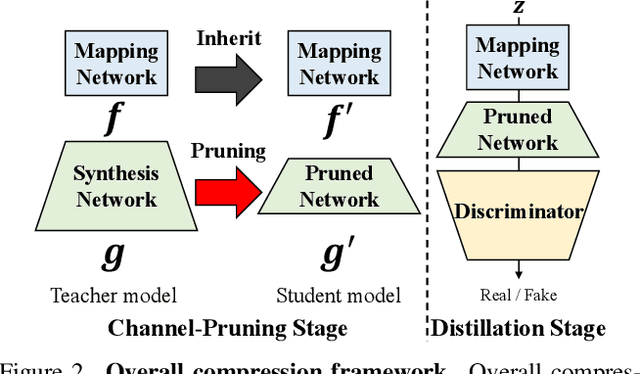
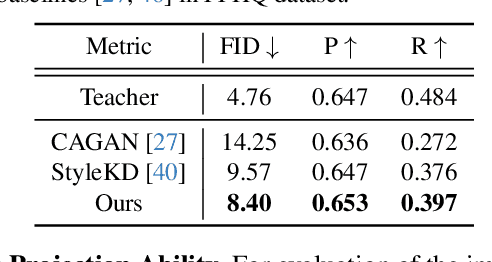
StyleGAN has shown remarkable performance in unconditional image generation. However, its high computational cost poses a significant challenge for practical applications. Although recent efforts have been made to compress StyleGAN while preserving its performance, existing compressed models still lag behind the original model, particularly in terms of sample diversity. To overcome this, we propose a novel channel pruning method that leverages varying sensitivities of channels to latent vectors, which is a key factor in sample diversity. Specifically, by assessing channel importance based on their sensitivities to latent vector perturbations, our method enhances the diversity of samples in the compressed model. Since our method solely focuses on the channel pruning stage, it has complementary benefits with prior training schemes without additional training cost. Extensive experiments demonstrate that our method significantly enhances sample diversity across various datasets. Moreover, in terms of FID scores, our method not only surpasses state-of-the-art by a large margin but also achieves comparable scores with only half training iterations.
Towards Squeezing-Averse Virtual Try-On via Sequential Deformation
Dec 26, 2023In this paper, we first investigate a visual quality degradation problem observed in recent high-resolution virtual try-on approach. The tendency is empirically found that the textures of clothes are squeezed at the sleeve, as visualized in the upper row of Fig.1(a). A main reason for the issue arises from a gradient conflict between two popular losses, the Total Variation (TV) and adversarial losses. Specifically, the TV loss aims to disconnect boundaries between the sleeve and torso in a warped clothing mask, whereas the adversarial loss aims to combine between them. Such contrary objectives feedback the misaligned gradients to a cascaded appearance flow estimation, resulting in undesirable squeezing artifacts. To reduce this, we propose a Sequential Deformation (SD-VITON) that disentangles the appearance flow prediction layers into TV objective-dominant (TVOB) layers and a task-coexistence (TACO) layer. Specifically, we coarsely fit the clothes onto a human body via the TVOB layers, and then keep on refining via the TACO layer. In addition, the bottom row of Fig.1(a) shows a different type of squeezing artifacts around the waist. To address it, we further propose that we first warp the clothes into a tucked-out shirts style, and then partially erase the texture from the warped clothes without hurting the smoothness of the appearance flows. Experimental results show that our SD-VITON successfully resolves both types of artifacts and outperforms the baseline methods. Source code will be available at https://github.com/SHShim0513/SD-VITON.
Style Injection in Diffusion: A Training-free Approach for Adapting Large-scale Diffusion Models for Style Transfer
Dec 11, 2023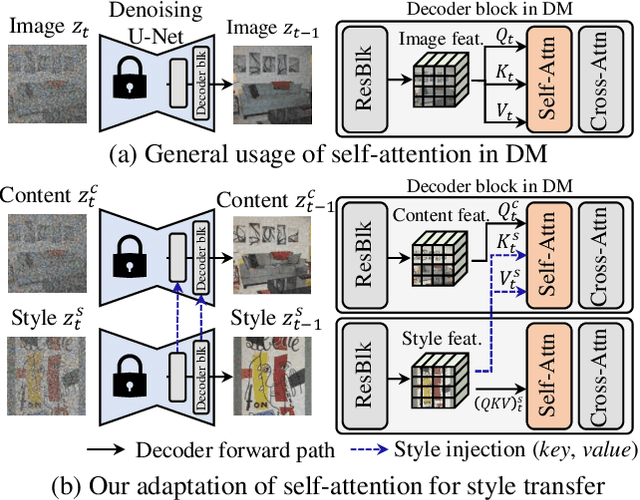

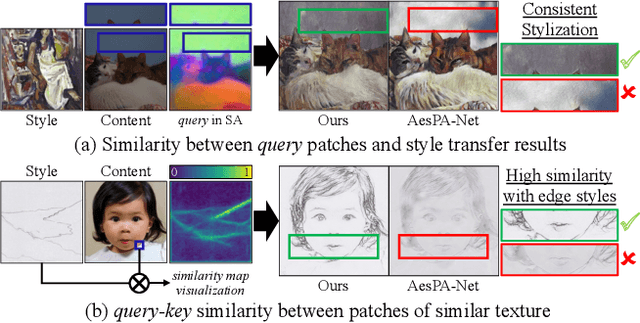
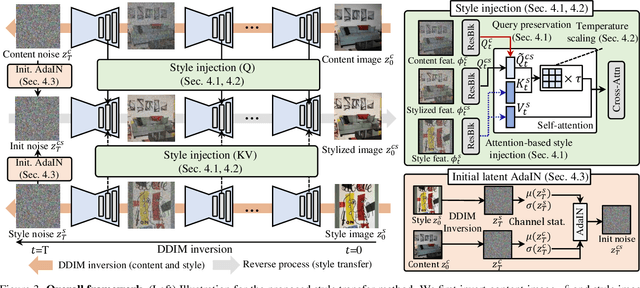
Despite the impressive generative capabilities of diffusion models, existing diffusion model-based style transfer methods require inference-stage optimization (e.g. fine-tuning or textual inversion of style) which is time-consuming, or fails to leverage the generative ability of large-scale diffusion models. To address these issues, we introduce a novel artistic style transfer method based on a pre-trained large-scale diffusion model without any optimization. Specifically, we manipulate the features of self-attention layers as the way the cross-attention mechanism works; in the generation process, substituting the key and value of content with those of style image. This approach provides several desirable characteristics for style transfer including 1) preservation of content by transferring similar styles into similar image patches and 2) transfer of style based on similarity of local texture (e.g. edge) between content and style images. Furthermore, we introduce query preservation and attention temperature scaling to mitigate the issue of disruption of original content, and initial latent Adaptive Instance Normalization (AdaIN) to deal with the disharmonious color (failure to transfer the colors of style). Our experimental results demonstrate that our proposed method surpasses state-of-the-art methods in both conventional and diffusion-based style transfer baselines.