 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiversity-aware Channel Pruning for StyleGAN Compression
Mar 20, 2024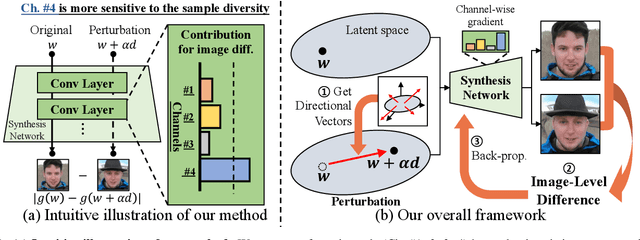
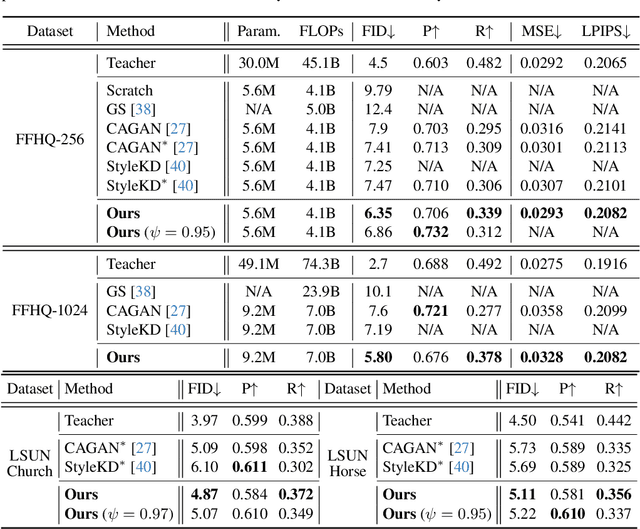
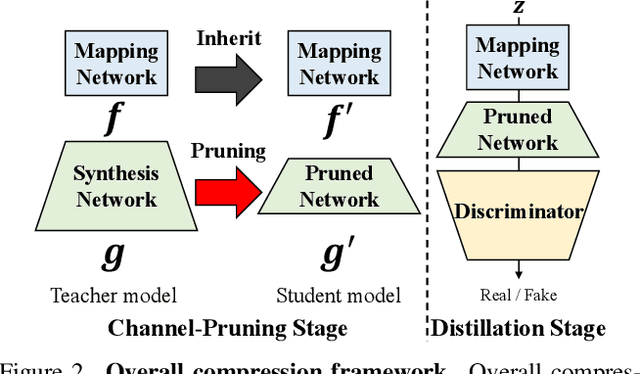
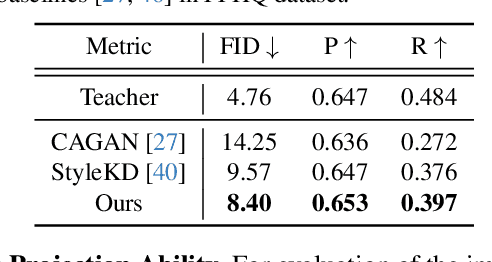
StyleGAN has shown remarkable performance in unconditional image generation. However, its high computational cost poses a significant challenge for practical applications. Although recent efforts have been made to compress StyleGAN while preserving its performance, existing compressed models still lag behind the original model, particularly in terms of sample diversity. To overcome this, we propose a novel channel pruning method that leverages varying sensitivities of channels to latent vectors, which is a key factor in sample diversity. Specifically, by assessing channel importance based on their sensitivities to latent vector perturbations, our method enhances the diversity of samples in the compressed model. Since our method solely focuses on the channel pruning stage, it has complementary benefits with prior training schemes without additional training cost. Extensive experiments demonstrate that our method significantly enhances sample diversity across various datasets. Moreover, in terms of FID scores, our method not only surpasses state-of-the-art by a large margin but also achieves comparable scores with only half training iterations.
Towards Squeezing-Averse Virtual Try-On via Sequential Deformation
Dec 26, 2023In this paper, we first investigate a visual quality degradation problem observed in recent high-resolution virtual try-on approach. The tendency is empirically found that the textures of clothes are squeezed at the sleeve, as visualized in the upper row of Fig.1(a). A main reason for the issue arises from a gradient conflict between two popular losses, the Total Variation (TV) and adversarial losses. Specifically, the TV loss aims to disconnect boundaries between the sleeve and torso in a warped clothing mask, whereas the adversarial loss aims to combine between them. Such contrary objectives feedback the misaligned gradients to a cascaded appearance flow estimation, resulting in undesirable squeezing artifacts. To reduce this, we propose a Sequential Deformation (SD-VITON) that disentangles the appearance flow prediction layers into TV objective-dominant (TVOB) layers and a task-coexistence (TACO) layer. Specifically, we coarsely fit the clothes onto a human body via the TVOB layers, and then keep on refining via the TACO layer. In addition, the bottom row of Fig.1(a) shows a different type of squeezing artifacts around the waist. To address it, we further propose that we first warp the clothes into a tucked-out shirts style, and then partially erase the texture from the warped clothes without hurting the smoothness of the appearance flows. Experimental results show that our SD-VITON successfully resolves both types of artifacts and outperforms the baseline methods. Source code will be available at https://github.com/SHShim0513/SD-VITON.