 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLow-Cost Self-Ensembles Based on Multi-Branch Transformation and Grouped Convolution
Aug 05, 2024Recent advancements in low-cost ensemble learning have demonstrated improved efficiency for image classification. However, the existing low-cost ensemble methods show relatively lower accuracy compared to conventional ensemble learning. In this paper, we propose a new low-cost ensemble learning, which can simultaneously achieve high efficiency and classification performance. A CNN is transformed into a multi-branch structure without introduction of additional components, which maintains the computational complexity as that of the original single model and also enhances diversity among the branches' outputs via sufficient separation between different pathways of the branches. In addition, we propose a new strategy that applies grouped convolution in the branches with different numbers of groups in different branches, which boosts the diversity of the branches' outputs. For training, we employ knowledge distillation using the ensemble of the outputs as the teacher signal. The high diversity among the outputs enables to form a powerful teacher, enhancing the individual branch's classification performance and consequently the overall ensemble performance. Experimental results show that our method achieves state-of-the-art classification accuracy and higher uncertainty estimation performance compared to previous low-cost ensemble methods. The code is available at https://github.com/hjdw2/SEMBG.
Network Fission Ensembles for Low-Cost Self-Ensembles
Aug 05, 2024Recent ensemble learning methods for image classification have been shown to improve classification accuracy with low extra cost. However, they still require multiple trained models for ensemble inference, which eventually becomes a significant burden when the model size increases. In this paper, we propose a low-cost ensemble learning and inference, called Network Fission Ensembles (NFE), by converting a conventional network itself into a multi-exit structure. Starting from a given initial network, we first prune some of the weights to reduce the training burden. We then group the remaining weights into several sets and create multiple auxiliary paths using each set to construct multi-exits. We call this process Network Fission. Through this, multiple outputs can be obtained from a single network, which enables ensemble learning. Since this process simply changes the existing network structure to multi-exits without using additional networks, there is no extra computational burden for ensemble learning and inference. Moreover, by learning from multiple losses of all exits, the multi-exits improve performance via regularization, and high performance can be achieved even with increased network sparsity. With our simple yet effective method, we achieve significant improvement compared to existing ensemble methods. The code is available at https://github.com/hjdw2/NFE.
Students are the Best Teacher: Exit-Ensemble Distillation with Multi-Exits
Apr 05, 2021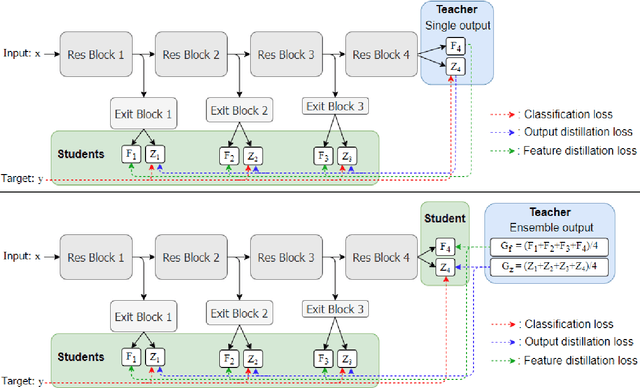
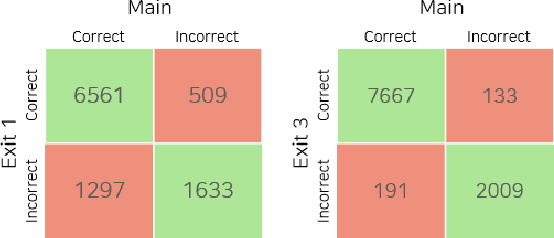

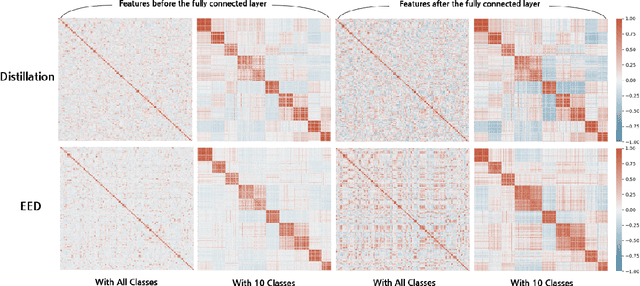
This paper proposes a novel knowledge distillation-based learning method to improve the classification performance of convolutional neural networks (CNNs) without a pre-trained teacher network, called exit-ensemble distillation. Our method exploits the multi-exit architecture that adds auxiliary classifiers (called exits) in the middle of a conventional CNN, through which early inference results can be obtained. The idea of our method is to train the network using the ensemble of the exits as the distillation target, which greatly improves the classification performance of the overall network. Our method suggests a new paradigm of knowledge distillation; unlike the conventional notion of distillation where teachers only teach students, we show that students can also help other students and even the teacher to learn better. Experimental results demonstrate that our method achieves significant improvement of classification performance on various popular CNN architectures (VGG, ResNet, ResNeXt, WideResNet, etc.). Furthermore, the proposed method can expedite the convergence of learning with improved stability. Our code will be available on Github.
Local Critic Training for Model-Parallel Learning of Deep Neural Networks
Feb 03, 2021
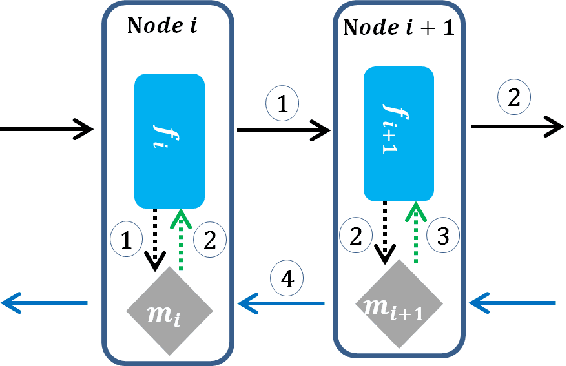

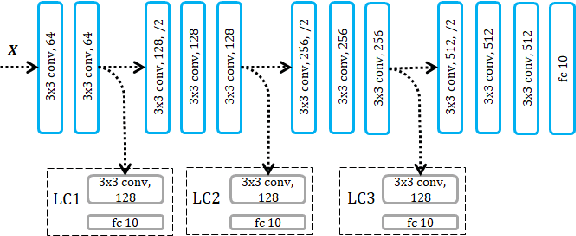
In this paper, we propose a novel model-parallel learning method, called local critic training, which trains neural networks using additional modules called local critic networks. The main network is divided into several layer groups and each layer group is updated through error gradients estimated by the corresponding local critic network. We show that the proposed approach successfully decouples the update process of the layer groups for both convolutional neural networks (CNNs) and recurrent neural networks (RNNs). In addition, we demonstrate that the proposed method is guaranteed to converge to a critical point. We also show that trained networks by the proposed method can be used for structural optimization. Experimental results show that our method achieves satisfactory performance, reduces training time greatly, and decreases memory consumption per machine. Code is available at https://github.com/hjdw2/Local-critic-training.
Local Critic Training of Deep Neural Networks
Sep 27, 2018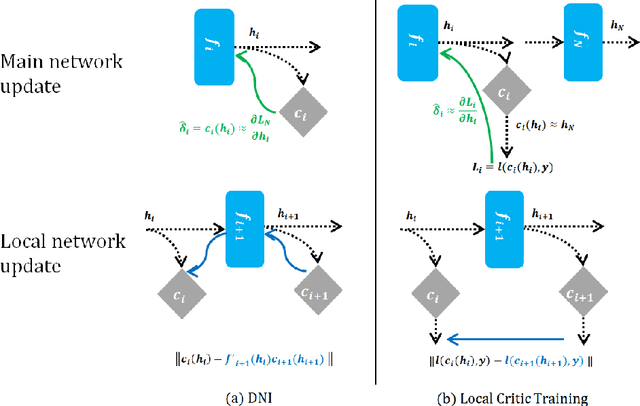
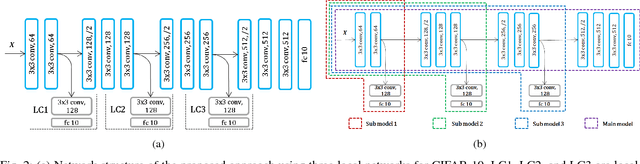


This paper proposes a novel approach to train deep neural networks by unlocking the layer-wise dependency of backpropagation training. The approach employs additional modules called local critic networks besides the main network model to be trained, which are used to obtain error gradients without complete feedforward and backward propagation processes. We propose a cascaded learning strategy for these local networks. In addition, the approach is also useful from multi-model perspectives, including structural optimization of neural networks, computationally efficient progressive inference, and ensemble classification for performance improvement. Experimental results show the effectiveness of the proposed approach and suggest guidelines for determining appropriate algorithm parameters.