 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocal Critic Training for Model-Parallel Learning of Deep Neural Networks
Paper and Code

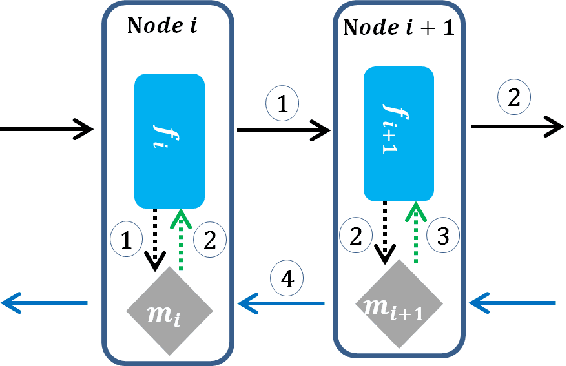

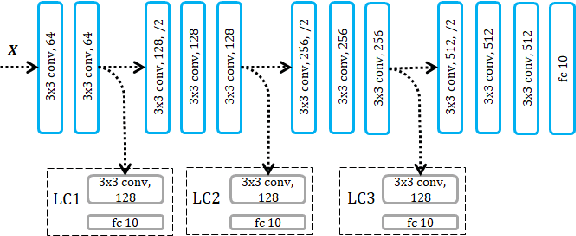
In this paper, we propose a novel model-parallel learning method, called local critic training, which trains neural networks using additional modules called local critic networks. The main network is divided into several layer groups and each layer group is updated through error gradients estimated by the corresponding local critic network. We show that the proposed approach successfully decouples the update process of the layer groups for both convolutional neural networks (CNNs) and recurrent neural networks (RNNs). In addition, we demonstrate that the proposed method is guaranteed to converge to a critical point. We also show that trained networks by the proposed method can be used for structural optimization. Experimental results show that our method achieves satisfactory performance, reduces training time greatly, and decreases memory consumption per machine. Code is available at https://github.com/hjdw2/Local-critic-training.