 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Explicit Knowledge Transfer for Knowledge Distillation
Sep 03, 2024Logit-based knowledge distillation (KD) for classification is cost-efficient compared to feature-based KD but often subject to inferior performance. Recently, it was shown that the performance of logit-based KD can be improved by effectively delivering the probability distribution for the non-target classes from the teacher model, which is known as `implicit (dark) knowledge', to the student model. Through gradient analysis, we first show that this actually has an effect of adaptively controlling the learning of implicit knowledge. Then, we propose a new loss that enables the student to learn explicit knowledge (i.e., the teacher's confidence about the target class) along with implicit knowledge in an adaptive manner. Furthermore, we propose to separate the classification and distillation tasks for effective distillation and inter-class relationship modeling. Experimental results demonstrate that the proposed method, called adaptive explicit knowledge transfer (AEKT) method, achieves improved performance compared to the state-of-the-art KD methods on the CIFAR-100 and ImageNet datasets.
Local Critic Training of Deep Neural Networks
Sep 27, 2018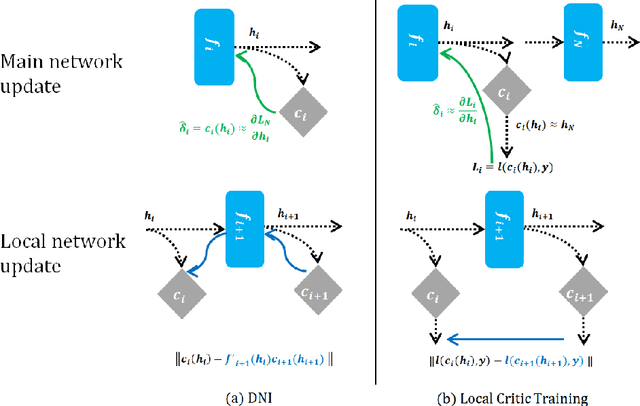
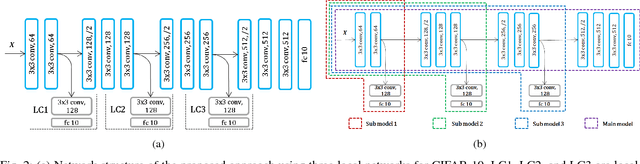


This paper proposes a novel approach to train deep neural networks by unlocking the layer-wise dependency of backpropagation training. The approach employs additional modules called local critic networks besides the main network model to be trained, which are used to obtain error gradients without complete feedforward and backward propagation processes. We propose a cascaded learning strategy for these local networks. In addition, the approach is also useful from multi-model perspectives, including structural optimization of neural networks, computationally efficient progressive inference, and ensemble classification for performance improvement. Experimental results show the effectiveness of the proposed approach and suggest guidelines for determining appropriate algorithm parameters.