 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLie Group Formulation of Recursive Dynamics Algorithms of Higher Order for Floating-Base Robots
May 07, 2026In this paper, we describe procedures for computing higher-order time derivatives of the Lie-group Newton-Euler, Articulated-Body Inertia, and hybrid dynamics algorithms for floating-base trees, where the base configuration evolves on SE(3) and the attached mechanism is an open kinematic tree with configuration on the (n1+n2)-dimensional manifold T^{n1} \times R^{n2}, using spatial representation of twists. After presenting the algorithms, we collect the resulting recursions into closed-form equations of motion, identifying an admissible Coriolis matrix satisfying the passivity property, and showing that the articulated inertia tensor remains unchanged across all time derivatives. We then apply the developed methods to a 12-DoF aerial manipulator to derive analytical expressions for its geometric forward and inverse dynamics along with their first time derivatives whereas the numerical simulations successfully evaluate these dynamics up to fifth order. Finally, to demonstrate their practical utility, we benchmark the proposed extensions and show that, in the considered tests, their computational cost scales quadratically with the derivative order, whereas the automatic-differentiation baseline exhibits exponential scaling.
IQRA 2026: Interspeech Challenge on Automatic Assessment Pronunciation for Modern Standard Arabic (MSA)
Mar 31, 2026We present the findings of the second edition of the IQRA Interspeech Challenge, a challenge on automatic Mispronunciation Detection and Diagnosis (MDD) for Modern Standard Arabic (MSA). Building on the previous edition, this iteration introduces \textbf{Iqra\_Extra\_IS26}, a new dataset of authentic human mispronounced speech, complementing the existing training and evaluation resources. Submitted systems employed a diverse range of approaches, spanning CTC-based self-supervised learning models, two-stage fine-tuning strategies, and using large audio-language models. Compared to the first edition, we observe a substantial jump of \textbf{0.28 in F1-score}, attributable both to novel architectures and modeling strategies proposed by participants and to the additional authentic mispronunciation data made available. These results demonstrate the growing maturity of Arabic MDD research and establish a stronger foundation for future work in Arabic pronunciation assessment.
CS-FLEURS: A Massively Multilingual and Code-Switched Speech Dataset
Sep 17, 2025We present CS-FLEURS, a new dataset for developing and evaluating code-switched speech recognition and translation systems beyond high-resourced languages. CS-FLEURS consists of 4 test sets which cover in total 113 unique code-switched language pairs across 52 languages: 1) a 14 X-English language pair set with real voices reading synthetically generated code-switched sentences, 2) a 16 X-English language pair set with generative text-to-speech 3) a 60 {Arabic, Mandarin, Hindi, Spanish}-X language pair set with the generative text-to-speech, and 4) a 45 X-English lower-resourced language pair test set with concatenative text-to-speech. Besides the four test sets, CS-FLEURS also provides a training set with 128 hours of generative text-to-speech data across 16 X-English language pairs. Our hope is that CS-FLEURS helps to broaden the scope of future code-switched speech research. Dataset link: https://huggingface.co/datasets/byan/cs-fleurs.
Towards a Unified Benchmark for Arabic Pronunciation Assessment: Quranic Recitation as Case Study
Jun 09, 2025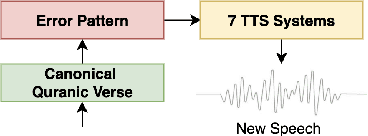
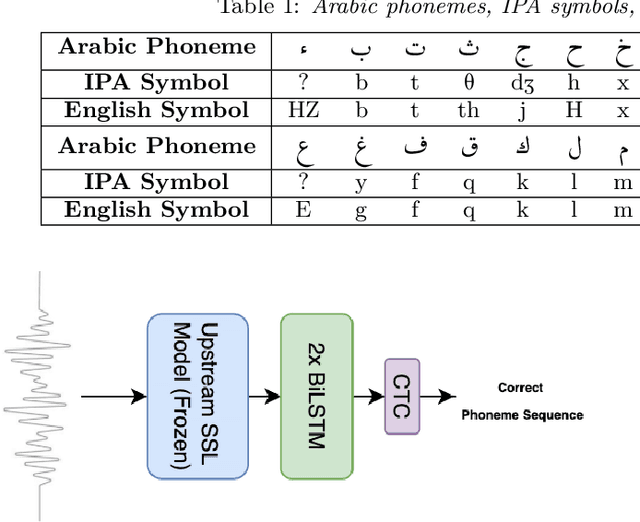

We present a unified benchmark for mispronunciation detection in Modern Standard Arabic (MSA) using Qur'anic recitation as a case study. Our approach lays the groundwork for advancing Arabic pronunciation assessment by providing a comprehensive pipeline that spans data processing, the development of a specialized phoneme set tailored to the nuances of MSA pronunciation, and the creation of the first publicly available test set for this task, which we term as the Qur'anic Mispronunciation Benchmark (QuranMB.v1). Furthermore, we evaluate several baseline models to provide initial performance insights, thereby highlighting both the promise and the challenges inherent in assessing MSA pronunciation. By establishing this standardized framework, we aim to foster further research and development in pronunciation assessment in Arabic language technology and related applications.
Beyond Orthography: Automatic Recovery of Short Vowels and Dialectal Sounds in Arabic
Aug 05, 2024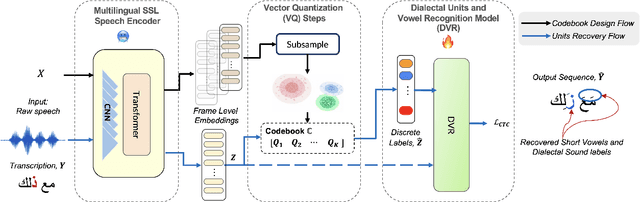


This paper presents a novel Dialectal Sound and Vowelization Recovery framework, designed to recognize borrowed and dialectal sounds within phonologically diverse and dialect-rich languages, that extends beyond its standard orthographic sound sets. The proposed framework utilized a quantized sequence of input with(out) continuous pretrained self-supervised representation. We show the efficacy of the pipeline using limited data for Arabic, a dialect-rich language containing more than 22 major dialects. Phonetically correct transcribed speech resources for dialectal Arabic are scarce. Therefore, we introduce ArabVoice15, a first-of-its-kind, curated test set featuring 5 hours of dialectal speech across 15 Arab countries, with phonetically accurate transcriptions, including borrowed and dialect-specific sounds. We described in detail the annotation guideline along with the analysis of the dialectal confusion pairs. Our extensive evaluation includes both subjective -- human perception tests and objective measures. Our empirical results, reported with three test sets, show that with only one and half hours of training data, our model improve character error rate by ~ 7\% in ArabVoice15 compared to the baseline.
Speech Representation Analysis based on Inter- and Intra-Model Similarities
Jun 23, 2024Self-supervised models have revolutionized speech processing, achieving new levels of performance in a wide variety of tasks with limited resources. However, the inner workings of these models are still opaque. In this paper, we aim to analyze the encoded contextual representation of these foundation models based on their inter- and intra-model similarity, independent of any external annotation and task-specific constraint. We examine different SSL models varying their training paradigm -- Contrastive (Wav2Vec2.0) and Predictive models (HuBERT); and model sizes (base and large). We explore these models on different levels of localization/distributivity of information including (i) individual neurons; (ii) layer representation; (iii) attention weights and (iv) compare the representations with their finetuned counterparts.Our results highlight that these models converge to similar representation subspaces but not to similar neuron-localized concepts\footnote{A concept represents a coherent fragment of knowledge, such as ``a class containing certain objects as elements, where the objects have certain properties. We made the code publicly available for facilitating further research, we publicly released our code.
Automatic Pronunciation Assessment -- A Review
Oct 21, 2023Pronunciation assessment and its application in computer-aided pronunciation training (CAPT) have seen impressive progress in recent years. With the rapid growth in language processing and deep learning over the past few years, there is a need for an updated review. In this paper, we review methods employed in pronunciation assessment for both phonemic and prosodic. We categorize the main challenges observed in prominent research trends, and highlight existing limitations, and available resources. This is followed by a discussion of the remaining challenges and possible directions for future work.
Speech collage: code-switched audio generation by collaging monolingual corpora
Sep 27, 2023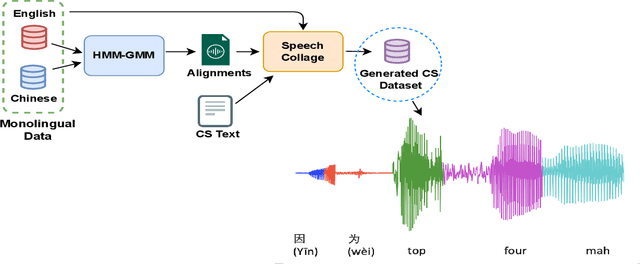
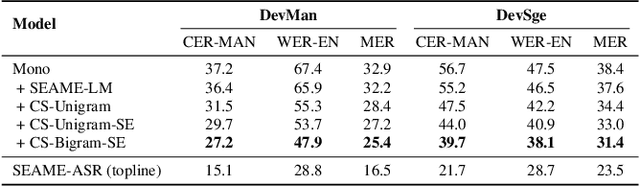
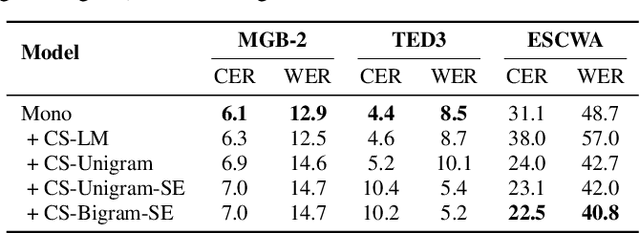
Designing effective automatic speech recognition (ASR) systems for Code-Switching (CS) often depends on the availability of the transcribed CS resources. To address data scarcity, this paper introduces Speech Collage, a method that synthesizes CS data from monolingual corpora by splicing audio segments. We further improve the smoothness quality of audio generation using an overlap-add approach. We investigate the impact of generated data on speech recognition in two scenarios: using in-domain CS text and a zero-shot approach with synthesized CS text. Empirical results highlight up to 34.4% and 16.2% relative reductions in Mixed-Error Rate and Word-Error Rate for in-domain and zero-shot scenarios, respectively. Lastly, we demonstrate that CS augmentation bolsters the model's code-switching inclination and reduces its monolingual bias.
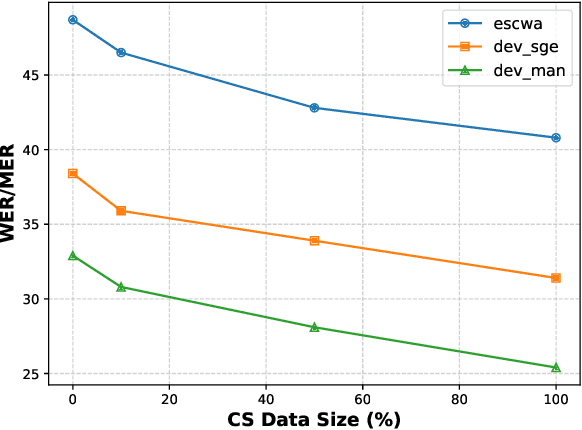
L1-aware Multilingual Mispronunciation Detection Framework
Sep 21, 2023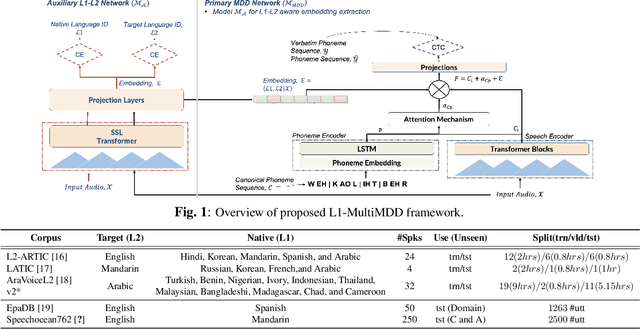
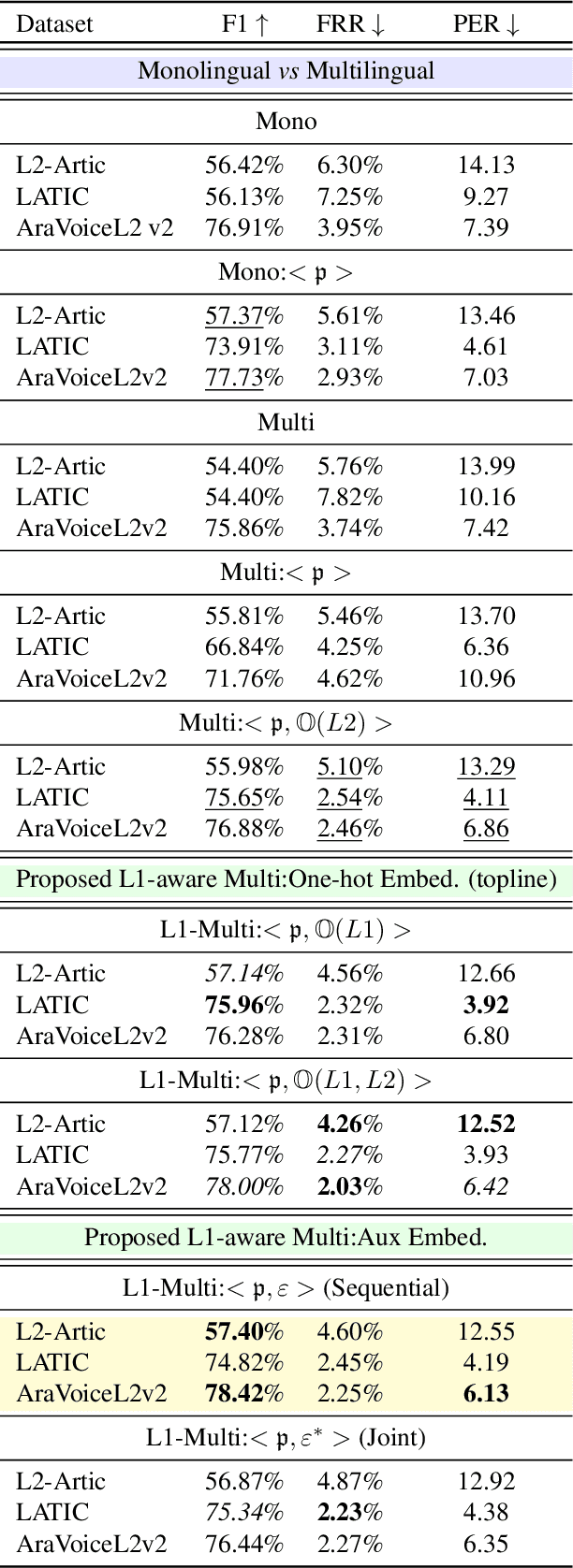

The phonological discrepancies between a speaker's native (L1) and the non-native language (L2) serves as a major factor for mispronunciation. This paper introduces a novel multilingual MDD architecture, L1-MultiMDD, enriched with L1-aware speech representation. An end-to-end speech encoder is trained on the input signal and its corresponding reference phoneme sequence. First, an attention mechanism is deployed to align the input audio with the reference phoneme sequence. Afterwards, the L1-L2-speech embedding are extracted from an auxiliary model, pretrained in a multi-task setup identifying L1 and L2 language, and are infused with the primary network. Finally, the L1-MultiMDD is then optimized for a unified multilingual phoneme recognition task using connectionist temporal classification (CTC) loss for the target languages: English, Arabic, and Mandarin. Our experiments demonstrate the effectiveness of the proposed L1-MultiMDD framework on both seen -- L2-ARTIC, LATIC, and AraVoiceL2v2; and unseen -- EpaDB and Speechocean762 datasets. The consistent gains in PER, and false rejection rate (FRR) across all target languages confirm our approach's robustness, efficacy, and generalizability.
The complementary roles of non-verbal cues for Robust Pronunciation Assessment
Sep 14, 2023Research on pronunciation assessment systems focuses on utilizing phonetic and phonological aspects of non-native (L2) speech, often neglecting the rich layer of information hidden within the non-verbal cues. In this study, we proposed a novel pronunciation assessment framework, IntraVerbalPA. % The framework innovatively incorporates both fine-grained frame- and abstract utterance-level non-verbal cues, alongside the conventional speech and phoneme representations. Additionally, we introduce ''Goodness of phonemic-duration'' metric to effectively model duration distribution within the framework. Our results validate the effectiveness of the proposed IntraVerbalPA framework and its individual components, yielding performance that either matches or outperforms existing research works.