 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompSRT: Quantization and Pruning for Image Super Resolution Transformers
Jan 28, 2026Model compression has become an important tool for making image super resolution models more efficient. However, the gap between the best compressed models and the full precision model still remains large and a need for deeper understanding of compression theory on more performant models remains. Prior research on quantization of LLMs has shown that Hadamard transformations lead to weights and activations with reduced outliers, which leads to improved performance. We argue that while the Hadamard transform does reduce the effect of outliers, an empirical analysis on how the transform functions remains needed. By studying the distributions of weights and activations of SwinIR-light, we show with statistical analysis that lower errors is caused by the Hadamard transforms ability to reduce the ranges, and increase the proportion of values around $0$. Based on these findings, we introduce CompSRT, a more performant way to compress the image super resolution transformer network SwinIR-light. We perform Hadamard-based quantization, and we also perform scalar decomposition to introduce two additional trainable parameters. Our quantization performance statistically significantly surpasses the SOTA in metrics with gains as large as 1.53 dB, and visibly improves visual quality by reducing blurriness at all bitwidths. At $3$-$4$ bits, to show our method is compatible with pruning for increased compression, we also prune $40\%$ of weights and show that we can achieve $6.67$-$15\%$ reduction in bits per parameter with comparable performance to SOTA.
Learning to Generate Context-Sensitive Backchannel Smiles for Embodied AI Agents with Applications in Mental Health Dialogues
Feb 13, 2024Addressing the critical shortage of mental health resources for effective screening, diagnosis, and treatment remains a significant challenge. This scarcity underscores the need for innovative solutions, particularly in enhancing the accessibility and efficacy of therapeutic support. Embodied agents with advanced interactive capabilities emerge as a promising and cost-effective supplement to traditional caregiving methods. Crucial to these agents' effectiveness is their ability to simulate non-verbal behaviors, like backchannels, that are pivotal in establishing rapport and understanding in therapeutic contexts but remain under-explored. To improve the rapport-building capabilities of embodied agents we annotated backchannel smiles in videos of intimate face-to-face conversations over topics such as mental health, illness, and relationships. We hypothesized that both speaker and listener behaviors affect the duration and intensity of backchannel smiles. Using cues from speech prosody and language along with the demographics of the speaker and listener, we found them to contain significant predictors of the intensity of backchannel smiles. Based on our findings, we introduce backchannel smile production in embodied agents as a generation problem. Our attention-based generative model suggests that listener information offers performance improvements over the baseline speaker-centric generation approach. Conditioned generation using the significant predictors of smile intensity provides statistically significant improvements in empirical measures of generation quality. Our user study by transferring generated smiles to an embodied agent suggests that agent with backchannel smiles is perceived to be more human-like and is an attractive alternative for non-personal conversations over agent without backchannel smiles.
Speech collage: code-switched audio generation by collaging monolingual corpora
Sep 27, 2023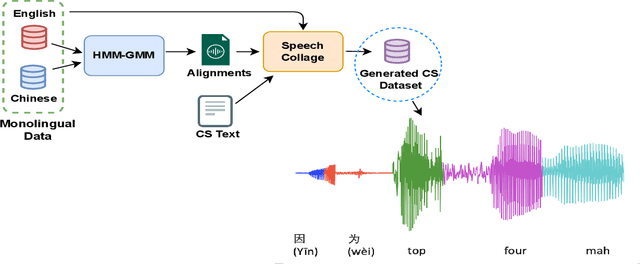
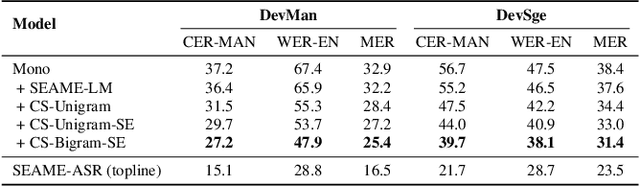
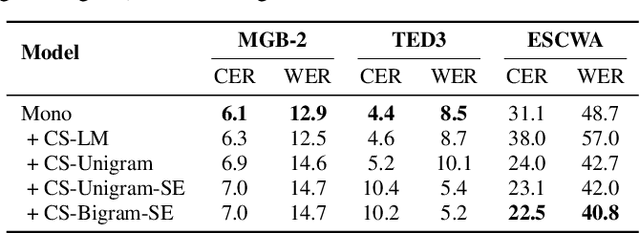
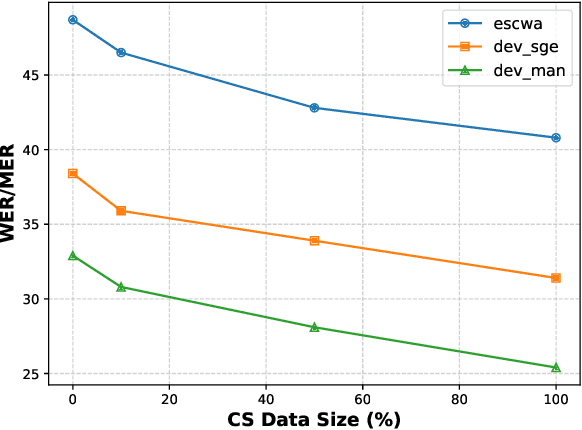
Designing effective automatic speech recognition (ASR) systems for Code-Switching (CS) often depends on the availability of the transcribed CS resources. To address data scarcity, this paper introduces Speech Collage, a method that synthesizes CS data from monolingual corpora by splicing audio segments. We further improve the smoothness quality of audio generation using an overlap-add approach. We investigate the impact of generated data on speech recognition in two scenarios: using in-domain CS text and a zero-shot approach with synthesized CS text. Empirical results highlight up to 34.4% and 16.2% relative reductions in Mixed-Error Rate and Word-Error Rate for in-domain and zero-shot scenarios, respectively. Lastly, we demonstrate that CS augmentation bolsters the model's code-switching inclination and reduces its monolingual bias.