 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFanar 2.0: Arabic Generative AI Stack
Mar 17, 2026We present Fanar 2.0, the second generation of Qatar's Arabic-centric Generative AI platform. Sovereignty is a first-class design principle: every component, from data pipelines to deployment infrastructure, was designed and operated entirely at QCRI, Hamad Bin Khalifa University. Fanar 2.0 is a story of resource-constrained excellence: the effort ran on 256 NVIDIA H100 GPUs, with Arabic having only ~0.5% of web data despite 400 million native speakers. Fanar 2.0 adopts a disciplined strategy of data quality over quantity, targeted continual pre-training, and model merging to achieve substantial gains within these constraints. At the core is Fanar-27B, continually pre-trained from a Gemma-3-27B backbone on a curated corpus of 120 billion high-quality tokens across three data recipes. Despite using 8x fewer pre-training tokens than Fanar 1.0, it delivers substantial benchmark improvements: Arabic knowledge (+9.1 pts), language (+7.3 pts), dialects (+3.5 pts), and English capability (+7.6 pts). Beyond the core LLM, Fanar 2.0 introduces a rich stack of new capabilities. FanarGuard is a state-of-the-art 4B bilingual moderation filter for Arabic safety and cultural alignment. The speech family Aura gains a long-form ASR model for hours-long audio. Oryx vision family adds Arabic-aware image and video understanding alongside culturally grounded image generation. An agentic tool-calling framework enables multi-step workflows. Fanar-Sadiq utilizes a multi-agent architecture for Islamic content. Fanar-Diwan provides classical Arabic poetry generation. FanarShaheen delivers LLM-powered bilingual translation. A redesigned multi-layer orchestrator coordinates all components through intent-aware routing and defense-in-depth safety validation. Taken together, Fanar 2.0 demonstrates that sovereign, resource-constrained AI development can produce systems competitive with those built at far greater scale.
Once Correct, Still Wrong: Counterfactual Hallucination in Multilingual Vision-Language Models
Feb 05, 2026Vision-language models (VLMs) can achieve high accuracy while still accepting culturally plausible but visually incorrect interpretations. Existing hallucination benchmarks rarely test this failure mode, particularly outside Western contexts and English. We introduce M2CQA, a culturally grounded multimodal benchmark built from images spanning 17 MENA countries, paired with contrastive true and counterfactual statements in English, Arabic, and its dialects. To isolate hallucination beyond raw accuracy, we propose the CounterFactual Hallucination Rate (CFHR), which measures counterfactual acceptance conditioned on correctly answering the true statement. Evaluating state-of-the-art VLMs under multiple prompting strategies, we find that CFHR rises sharply in Arabic, especially in dialects, even when true-statement accuracy remains high. Moreover, reasoning-first prompting consistently increases counterfactual hallucination, while answering before justifying improves robustness. We will make the experimental resources and dataset publicly available for the community.
Speech collage: code-switched audio generation by collaging monolingual corpora
Sep 27, 2023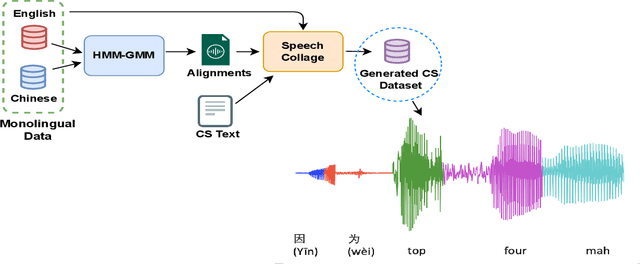
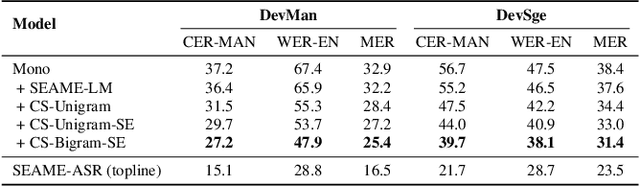
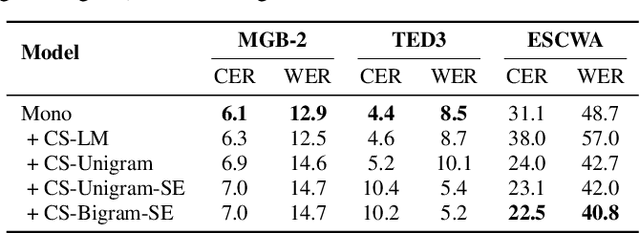
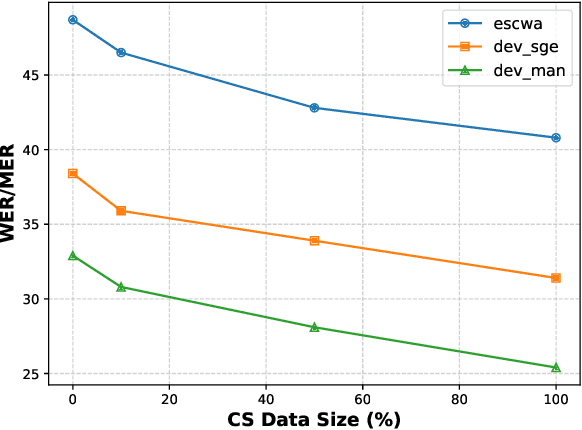
Designing effective automatic speech recognition (ASR) systems for Code-Switching (CS) often depends on the availability of the transcribed CS resources. To address data scarcity, this paper introduces Speech Collage, a method that synthesizes CS data from monolingual corpora by splicing audio segments. We further improve the smoothness quality of audio generation using an overlap-add approach. We investigate the impact of generated data on speech recognition in two scenarios: using in-domain CS text and a zero-shot approach with synthesized CS text. Empirical results highlight up to 34.4% and 16.2% relative reductions in Mixed-Error Rate and Word-Error Rate for in-domain and zero-shot scenarios, respectively. Lastly, we demonstrate that CS augmentation bolsters the model's code-switching inclination and reduces its monolingual bias.
Benchmarking Evaluation Metrics for Code-Switching Automatic Speech Recognition
Nov 22, 2022Code-switching poses a number of challenges and opportunities for multilingual automatic speech recognition. In this paper, we focus on the question of robust and fair evaluation metrics. To that end, we develop a reference benchmark data set of code-switching speech recognition hypotheses with human judgments. We define clear guidelines for minimal editing of automatic hypotheses. We validate the guidelines using 4-way inter-annotator agreement. We evaluate a large number of metrics in terms of correlation with human judgments. The metrics we consider vary in terms of representation (orthographic, phonological, semantic), directness (intrinsic vs extrinsic), granularity (e.g. word, character), and similarity computation method. The highest correlation to human judgment is achieved using transliteration followed by text normalization. We release the first corpus for human acceptance of code-switching speech recognition results in dialectal Arabic/English conversation speech.
Arabic Code-Switching Speech Recognition using Monolingual Data
Jul 04, 2021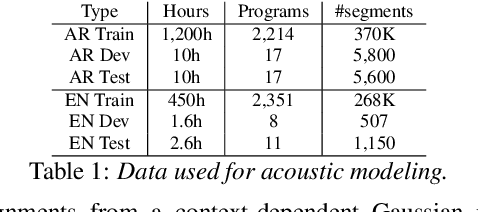
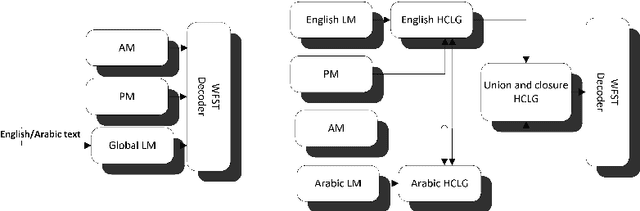
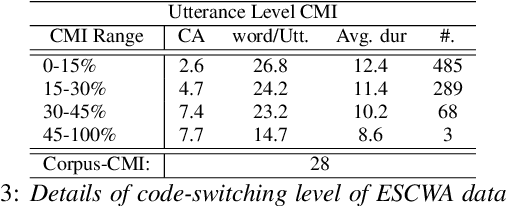
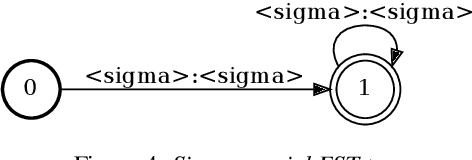
Code-switching in automatic speech recognition (ASR) is an important challenge due to globalization. Recent research in multilingual ASR shows potential improvement over monolingual systems. We study key issues related to multilingual modeling for ASR through a series of large-scale ASR experiments. Our innovative framework deploys a multi-graph approach in the weighted finite state transducers (WFST) framework. We compare our WFST decoding strategies with a transformer sequence to sequence system trained on the same data. Given a code-switching scenario between Arabic and English languages, our results show that the WFST decoding approaches were more suitable for the intersentential code-switching datasets. In addition, the transformer system performed better for intrasentential code-switching task. With this study, we release an artificially generated development and test sets, along with ecological code-switching test set, to benchmark the ASR performance.
KARI: KAnari/QCRI's End-to-End systems for the INTERSPEECH 2021 Indian Languages Code-Switching Challenge
Jun 10, 2021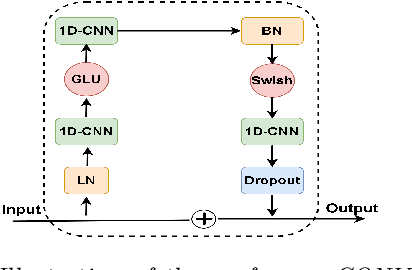
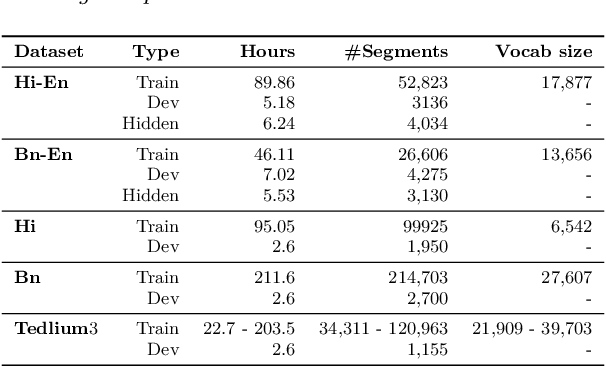
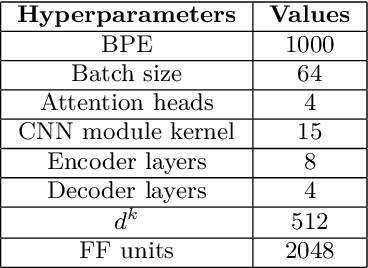

In this paper, we present the Kanari/QCRI (KARI) system and the modeling strategies used to participate in the Interspeech 2021 Code-switching (CS) challenge for low-resource Indian languages. The subtask involved developing a speech recognition system for two CS datasets: Hindi-English and Bengali-English, collected in a real-life scenario. To tackle the CS challenges, we use transfer learning for incorporating the publicly available monolingual Hindi, Bengali, and English speech data. In this work, we study the effectiveness of two steps transfer learning protocol for low-resourced CS data: monolingual pretraining, followed by fine-tuning. For acoustic modeling, we develop an end-to-end convolution-augmented transformer (Conformer). We show that selecting the percentage of each monolingual data affects model biases towards using one language character set over the other in a CS scenario. The models pretrained on well-aligned and accurate monolingual data showed robustness against misalignment between the segments and the transcription. Finally, we develop word-level n-gram language models (LM) to rescore ASR recognition.