 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKARI: KAnari/QCRI's End-to-End systems for the INTERSPEECH 2021 Indian Languages Code-Switching Challenge
Paper and Code
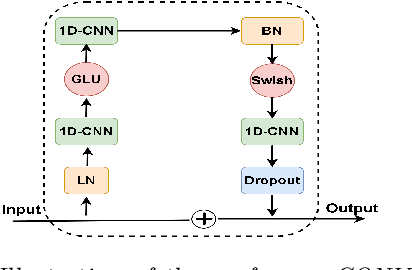
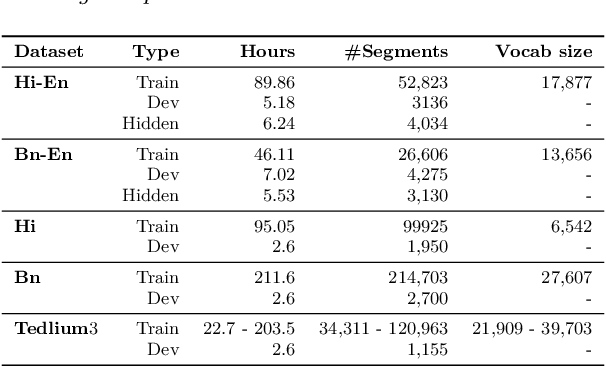
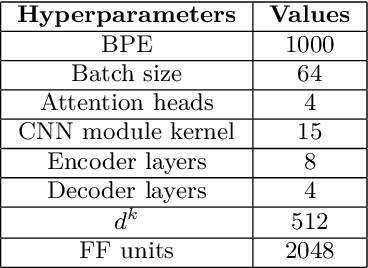

In this paper, we present the Kanari/QCRI (KARI) system and the modeling strategies used to participate in the Interspeech 2021 Code-switching (CS) challenge for low-resource Indian languages. The subtask involved developing a speech recognition system for two CS datasets: Hindi-English and Bengali-English, collected in a real-life scenario. To tackle the CS challenges, we use transfer learning for incorporating the publicly available monolingual Hindi, Bengali, and English speech data. In this work, we study the effectiveness of two steps transfer learning protocol for low-resourced CS data: monolingual pretraining, followed by fine-tuning. For acoustic modeling, we develop an end-to-end convolution-augmented transformer (Conformer). We show that selecting the percentage of each monolingual data affects model biases towards using one language character set over the other in a CS scenario. The models pretrained on well-aligned and accurate monolingual data showed robustness against misalignment between the segments and the transcription. Finally, we develop word-level n-gram language models (LM) to rescore ASR recognition.