 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Voice Behind the Words: Quantifying Intersectional Bias in SpeechLLMs
Mar 15, 2026Speech Large Language Models (SpeechLLMs) process spoken input directly, retaining cues such as accent and perceived gender that were previously removed in cascaded pipelines. This introduces speaker identity dependent variation in responses. We present a large-scale intersectional evaluation of accent and gender bias in three SpeechLLMs using 2,880 controlled interactions across six English accents and two gender presentations, keeping linguistic content constant through voice cloning. Using pointwise LLM-judge ratings, pairwise comparisons, and Best-Worst Scaling with human validation, we detect consistent disparities. Eastern European-accented speech receives lower helpfulness scores, particularly for female-presenting voices. The bias is implicit: responses remain polite but differ in helpfulness. While LLM judges capture the directional trend of these biases, human evaluators exhibit significantly higher sensitivity, uncovering sharper intersectional disparities.
A Practitioner's Guide to Building ASR Models for Low-Resource Languages: A Case Study on Scottish Gaelic
Jun 05, 2025An effective approach to the development of ASR systems for low-resource languages is to fine-tune an existing multilingual end-to-end model. When the original model has been trained on large quantities of data from many languages, fine-tuning can be effective with limited training data, even when the language in question was not present in the original training data. The fine-tuning approach has been encouraged by the availability of public-domain E2E models and is widely believed to lead to state-of-the-art results. This paper, however, challenges that belief. We show that an approach combining hybrid HMMs with self-supervised models can yield substantially better performance with limited training data. This combination allows better utilisation of all available speech and text data through continued self-supervised pre-training and semi-supervised training. We benchmark our approach on Scottish Gaelic, achieving WER reductions of 32% relative over our best fine-tuned Whisper model.
Speech Recognition for Automatically Assessing Afrikaans and isiXhosa Preschool Oral Narratives
Jan 11, 2025We develop automatic speech recognition (ASR) systems for stories told by Afrikaans and isiXhosa preschool children. Oral narratives provide a way to assess children's language development before they learn to read. We consider a range of prior child-speech ASR strategies to determine which is best suited to this unique setting. Using Whisper and only 5 minutes of transcribed in-domain child speech, we find that additional in-domain adult data (adult speech matching the story domain) provides the biggest improvement, especially when coupled with voice conversion. Semi-supervised learning also helps for both languages, while parameter-efficient fine-tuning helps on Afrikaans but not on isiXhosa (which is under-represented in the Whisper model). Few child-speech studies look at non-English data, and even fewer at the preschool ages of 4 and 5. Our work therefore represents a unique validation of a wide range of previous child-speech ASR strategies in an under-explored setting.
TTSDS -- Text-to-Speech Distribution Score
Jul 17, 2024



Many recently published Text-to-Speech (TTS) systems produce audio close to real speech. However, TTS evaluation needs to be revisited to make sense of the results obtained with the new architectures, approaches and datasets. We propose evaluating the quality of synthetic speech as a combination of multiple factors such as prosody, speaker identity, and intelligibility. Our approach assesses how well synthetic speech mirrors real speech by obtaining correlates of each factor and measuring their distance from both real speech datasets and noise datasets. We benchmark 35 TTS systems developed between 2008 and 2024 and show that our score computed as an unweighted average of factors strongly correlates with the human evaluations from each time period.
Speech collage: code-switched audio generation by collaging monolingual corpora
Sep 27, 2023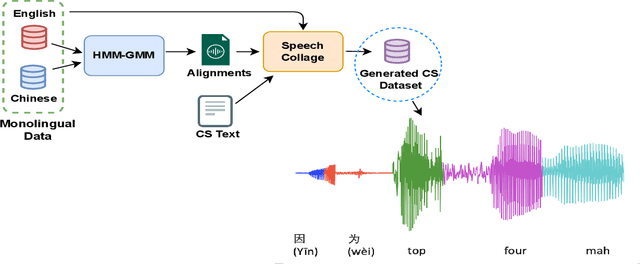
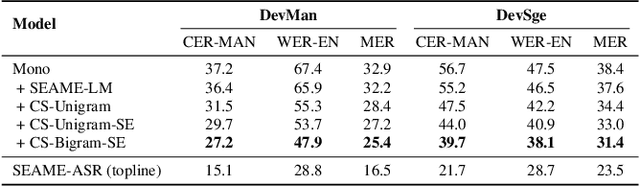
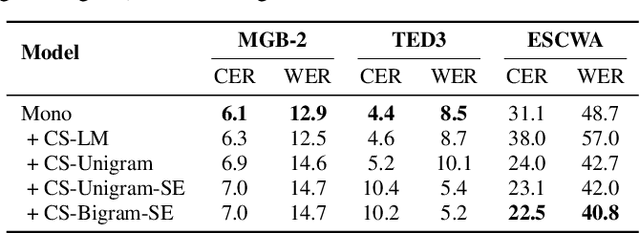
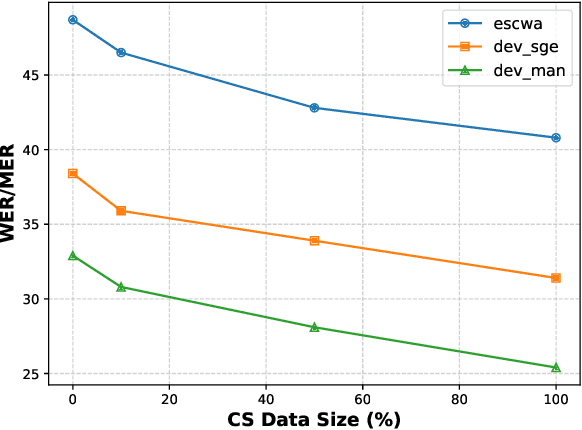
Designing effective automatic speech recognition (ASR) systems for Code-Switching (CS) often depends on the availability of the transcribed CS resources. To address data scarcity, this paper introduces Speech Collage, a method that synthesizes CS data from monolingual corpora by splicing audio segments. We further improve the smoothness quality of audio generation using an overlap-add approach. We investigate the impact of generated data on speech recognition in two scenarios: using in-domain CS text and a zero-shot approach with synthesized CS text. Empirical results highlight up to 34.4% and 16.2% relative reductions in Mixed-Error Rate and Word-Error Rate for in-domain and zero-shot scenarios, respectively. Lastly, we demonstrate that CS augmentation bolsters the model's code-switching inclination and reduces its monolingual bias.
Evaluating and reducing the distance between synthetic and real speech distributions
Nov 29, 2022While modern Text-to-Speech (TTS) systems can produce speech rated highly in terms of subjective evaluation, the distance between real and synthetic speech distributions remains understudied, where we use the term \textit{distribution} to mean the sample space of all possible real speech recordings from a given set of speakers; or of the synthetic samples that could be generated for the same set of speakers. We evaluate the distance of real and synthetic speech distributions along the dimensions of the acoustic environment, speaker characteristics and prosody using a range of speech processing measures and the respective Wasserstein distances of their distributions. We reduce these distribution distances along said dimensions by providing utterance-level information derived from the measures to the model and show they can be generated at inference time. The improvements to the dimensions translate to overall distribution distance reduction approximated using Automatic Speech Recognition (ASR) by evaluating the fitness of the synthetic data as training data.
Mask-combine Decoding and Classification Approach for Punctuation Prediction with real-time Inference Constraints
Dec 17, 2021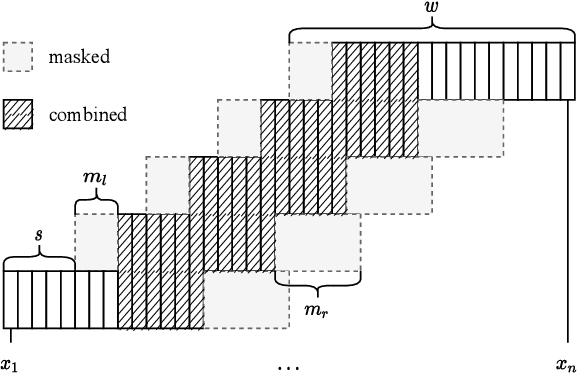
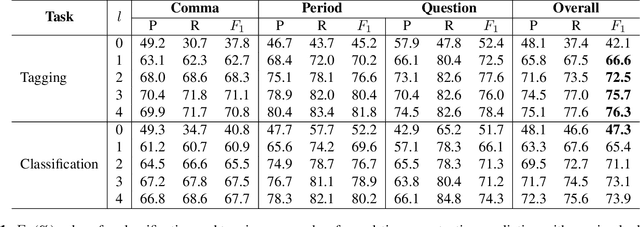
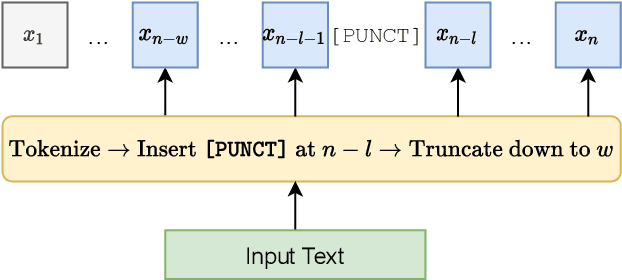
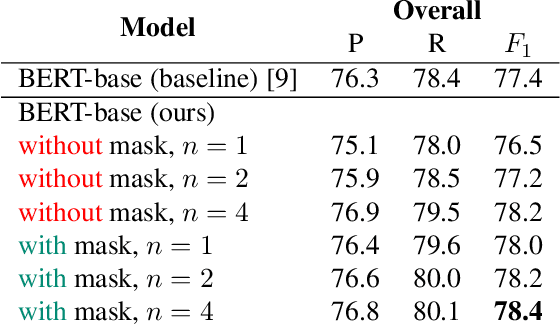
In this work, we unify several existing decoding strategies for punctuation prediction in one framework and introduce a novel strategy which utilises multiple predictions at each word across different windows. We show that significant improvements can be achieved by optimising these strategies after training a model, only leading to a potential increase in inference time, with no requirement for retraining. We further use our decoding strategy framework for the first comparison of tagging and classification approaches for punctuation prediction in a real-time setting. Our results show that a classification approach for punctuation prediction can be beneficial when little or no right-side context is available.
Speaker Adaptive Training using Model Agnostic Meta-Learning
Oct 23, 2019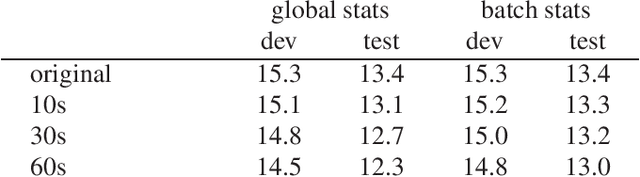


Speaker adaptive training (SAT) of neural network acoustic models learns models in a way that makes them more suitable for adaptation to test conditions. Conventionally, model-based speaker adaptive training is performed by having a set of speaker dependent parameters that are jointly optimised with speaker independent parameters in order to remove speaker variation. However, this does not scale well if all neural network weights are to be adapted to the speaker. In this paper we formulate speaker adaptive training as a meta-learning task, in which an adaptation process using gradient descent is encoded directly into the training of the model. We compare our approach with test-only adaptation of a standard baseline model and a SAT-LHUC model with a learned speaker adaptation schedule and demonstrate that the meta-learning approach achieves comparable results.
Acoustic Model Adaptation from Raw Waveforms with SincNet
Sep 30, 2019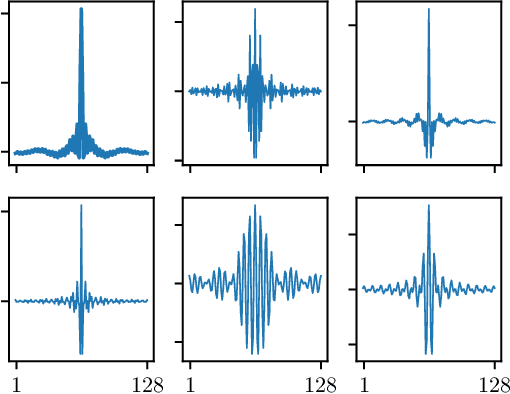
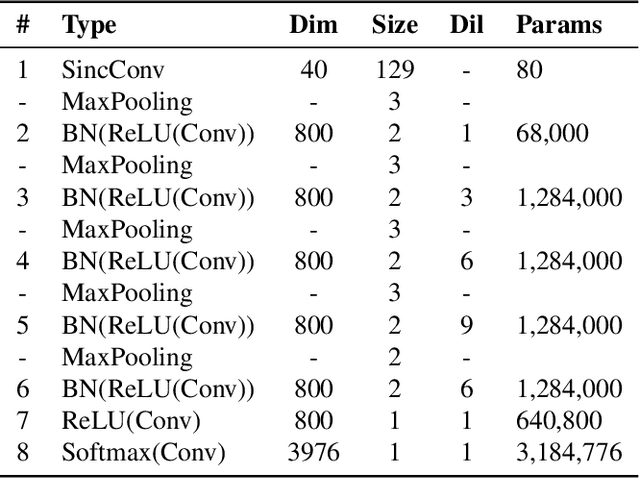
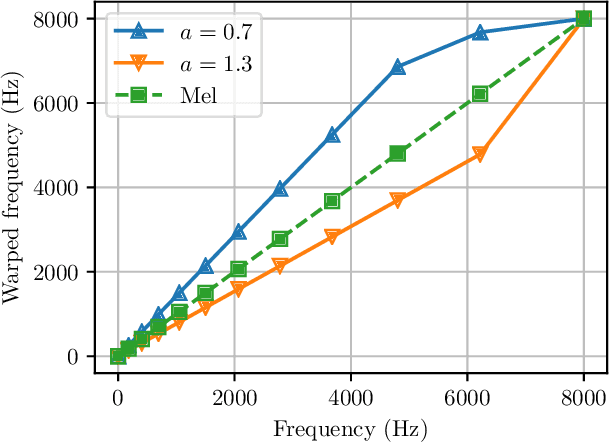
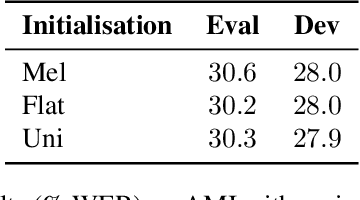
Raw waveform acoustic modelling has recently gained interest due to neural networks' ability to learn feature extraction, and the potential for finding better representations for a given scenario than hand-crafted features. SincNet has been proposed to reduce the number of parameters required in raw-waveform modelling, by restricting the filter functions, rather than having to learn every tap of each filter. We study the adaptation of the SincNet filter parameters from adults' to children's speech, and show that the parameterisation of the SincNet layer is well suited for adaptation in practice: we can efficiently adapt with a very small number of parameters, producing error rates comparable to techniques using orders of magnitude more parameters.
Lattice-based lightly-supervised acoustic model training
May 30, 2019
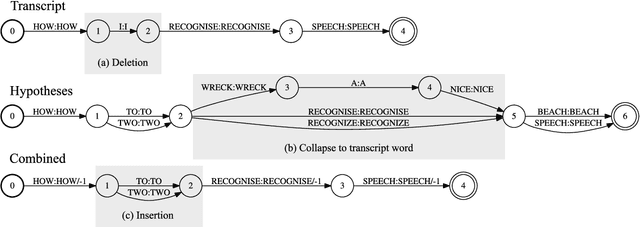
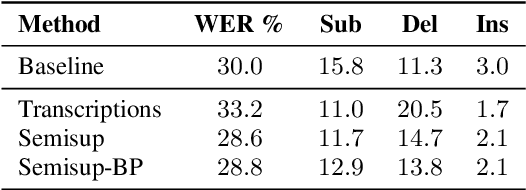
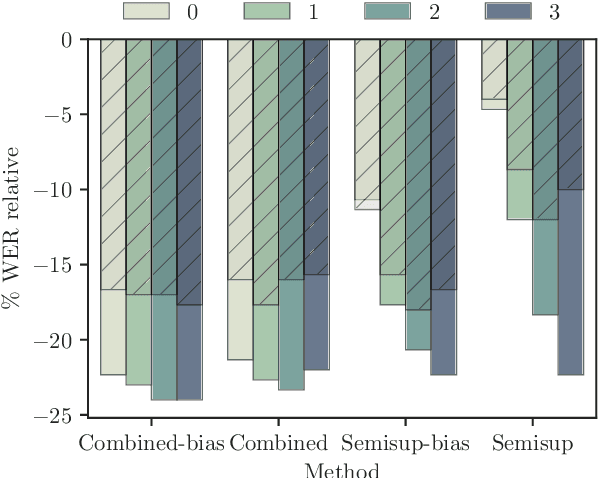
In the broadcast domain there is an abundance of related text data and partial transcriptions, such as closed captions and subtitles. This text data can be used for lightly supervised training, in which text matching the audio is selected using an existing speech recognition model. Current approaches to light supervision typically filter the data based on matching error rates between the transcriptions and biased decoding hypotheses. In contrast, semi-supervised training does not require matching text data, instead generating a hypothesis using a background language model. State-of-the-art semi-supervised training uses lattice-based supervision with the lattice-free MMI (LF-MMI) objective function. We propose a technique to combine inaccurate transcriptions with the lattices generated for semi-supervised training, thus preserving uncertainty in the lattice where appropriate. We demonstrate that this combined approach reduces the expected error rates over the lattices, and reduces the word error rate (WER) on a broadcast task.