 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAcoustic Model Adaptation from Raw Waveforms with SincNet
Paper and Code
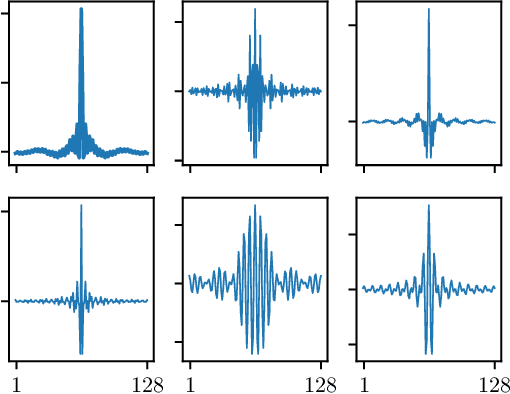
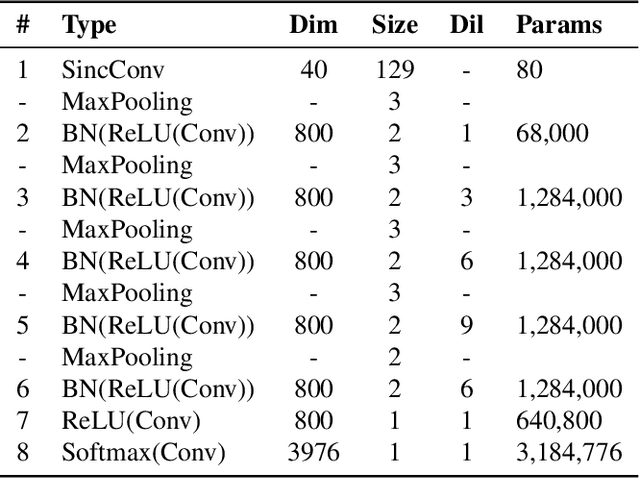
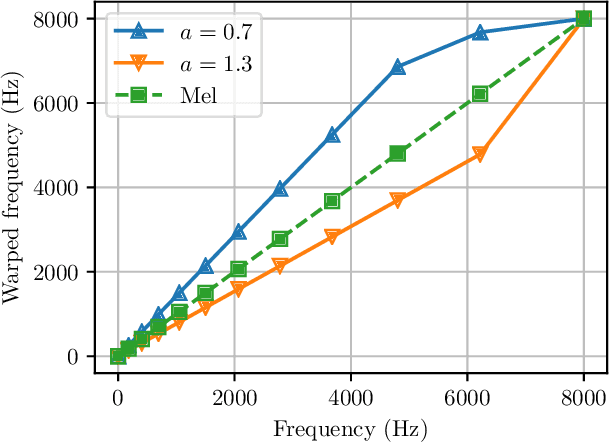
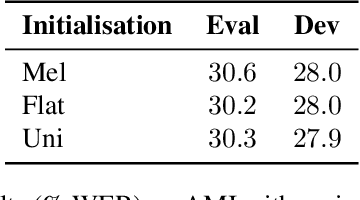
Raw waveform acoustic modelling has recently gained interest due to neural networks' ability to learn feature extraction, and the potential for finding better representations for a given scenario than hand-crafted features. SincNet has been proposed to reduce the number of parameters required in raw-waveform modelling, by restricting the filter functions, rather than having to learn every tap of each filter. We study the adaptation of the SincNet filter parameters from adults' to children's speech, and show that the parameterisation of the SincNet layer is well suited for adaptation in practice: we can efficiently adapt with a very small number of parameters, producing error rates comparable to techniques using orders of magnitude more parameters.