 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatically assessing oral narratives of Afrikaans and isiXhosa children
Jul 18, 2025Developing narrative and comprehension skills in early childhood is critical for later literacy. However, teachers in large preschool classrooms struggle to accurately identify students who require intervention. We present a system for automatically assessing oral narratives of preschool children in Afrikaans and isiXhosa. The system uses automatic speech recognition followed by a machine learning scoring model to predict narrative and comprehension scores. For scoring predicted transcripts, we compare a linear model to a large language model (LLM). The LLM-based system outperforms the linear model in most cases, but the linear system is competitive despite its simplicity. The LLM-based system is comparable to a human expert in flagging children who require intervention. We lay the foundation for automatic oral assessments in classrooms, giving teachers extra capacity to focus on personalised support for children's learning.
Speech Recognition for Automatically Assessing Afrikaans and isiXhosa Preschool Oral Narratives
Jan 11, 2025We develop automatic speech recognition (ASR) systems for stories told by Afrikaans and isiXhosa preschool children. Oral narratives provide a way to assess children's language development before they learn to read. We consider a range of prior child-speech ASR strategies to determine which is best suited to this unique setting. Using Whisper and only 5 minutes of transcribed in-domain child speech, we find that additional in-domain adult data (adult speech matching the story domain) provides the biggest improvement, especially when coupled with voice conversion. Semi-supervised learning also helps for both languages, while parameter-efficient fine-tuning helps on Afrikaans but not on isiXhosa (which is under-represented in the Whisper model). Few child-speech studies look at non-English data, and even fewer at the preschool ages of 4 and 5. Our work therefore represents a unique validation of a wide range of previous child-speech ASR strategies in an under-explored setting.
Multilingual acoustic word embeddings for zero-resource languages
Jan 23, 2024This research addresses the challenge of developing speech applications for zero-resource languages that lack labelled data. It specifically uses acoustic word embedding (AWE) -- fixed-dimensional representations of variable-duration speech segments -- employing multilingual transfer, where labelled data from several well-resourced languages are used for pertaining. The study introduces a new neural network that outperforms existing AWE models on zero-resource languages. It explores the impact of the choice of well-resourced languages. AWEs are applied to a keyword-spotting system for hate speech detection in Swahili radio broadcasts, demonstrating robustness in real-world scenarios. Additionally, novel semantic AWE models improve semantic query-by-example search.
Leveraging multilingual transfer for unsupervised semantic acoustic word embeddings
Jul 05, 2023Acoustic word embeddings (AWEs) are fixed-dimensional vector representations of speech segments that encode phonetic content so that different realisations of the same word have similar embeddings. In this paper we explore semantic AWE modelling. These AWEs should not only capture phonetics but also the meaning of a word (similar to textual word embeddings). We consider the scenario where we only have untranscribed speech in a target language. We introduce a number of strategies leveraging a pre-trained multilingual AWE model -- a phonetic AWE model trained on labelled data from multiple languages excluding the target. Our best semantic AWE approach involves clustering word segments using the multilingual AWE model, deriving soft pseudo-word labels from the cluster centroids, and then training a Skipgram-like model on the soft vectors. In an intrinsic word similarity task measuring semantics, this multilingual transfer approach outperforms all previous semantic AWE methods. We also show -- for the first time -- that AWEs can be used for downstream semantic query-by-example search.
Towards hate speech detection in low-resource languages: Comparing ASR to acoustic word embeddings on Wolof and Swahili
Jun 01, 2023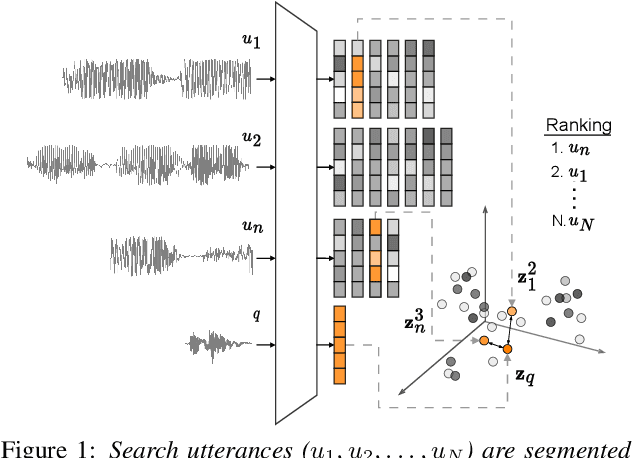

We consider hate speech detection through keyword spotting on radio broadcasts. One approach is to build an automatic speech recognition (ASR) system for the target low-resource language. We compare this to using acoustic word embedding (AWE) models that map speech segments to a space where matching words have similar vectors. We specifically use a multilingual AWE model trained on labelled data from well-resourced languages to spot keywords in data in the unseen target language. In contrast to ASR, the AWE approach only requires a few keyword exemplars. In controlled experiments on Wolof and Swahili where training and test data are from the same domain, an ASR model trained on just five minutes of data outperforms the AWE approach. But in an in-the-wild test on Swahili radio broadcasts with actual hate speech keywords, the AWE model (using one minute of template data) is more robust, giving similar performance to an ASR system trained on 30 hours of labelled data.
Multilingual transfer of acoustic word embeddings improves when training on languages related to the target zero-resource language
Jun 24, 2021


Acoustic word embedding models map variable duration speech segments to fixed dimensional vectors, enabling efficient speech search and discovery. Previous work explored how embeddings can be obtained in zero-resource settings where no labelled data is available in the target language. The current best approach uses transfer learning: a single supervised multilingual model is trained using labelled data from multiple well-resourced languages and then applied to a target zero-resource language (without fine-tuning). However, it is still unclear how the specific choice of training languages affect downstream performance. Concretely, here we ask whether it is beneficial to use training languages related to the target. Using data from eleven languages spoken in Southern Africa, we experiment with adding data from different language families while controlling for the amount of data per language. In word discrimination and query-by-example search evaluations, we show that training on languages from the same family gives large improvements. Through finer-grained analysis, we show that training on even just a single related language gives the largest gain. We also find that adding data from unrelated languages generally doesn't hurt performance.
Acoustic word embeddings for zero-resource languages using self-supervised contrastive learning and multilingual adaptation
Mar 19, 2021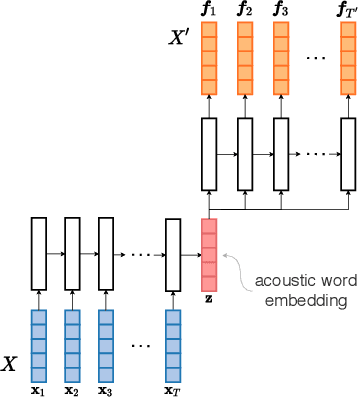
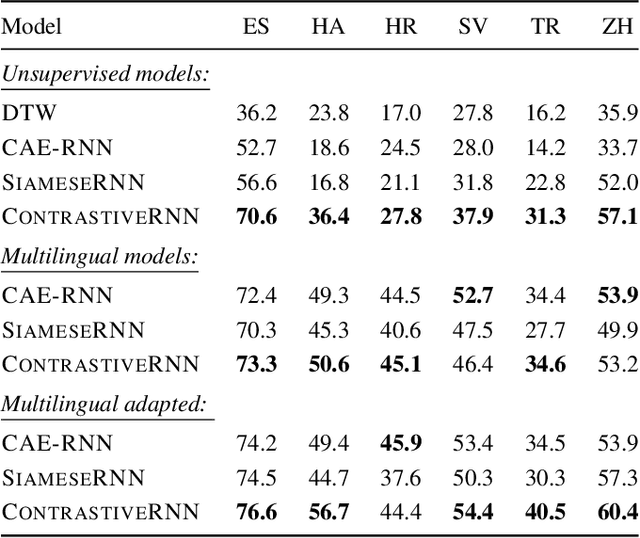
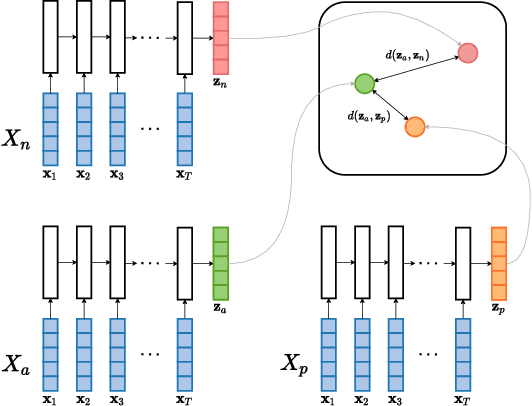
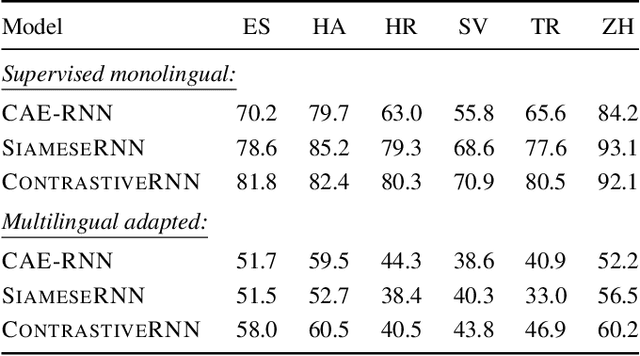
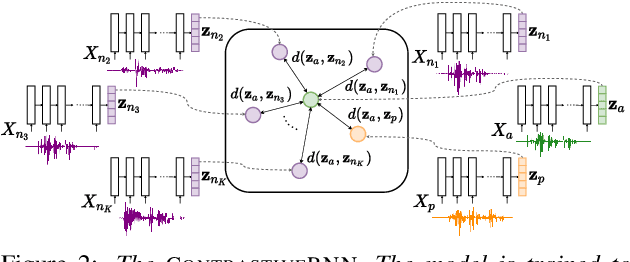
Acoustic word embeddings (AWEs) are fixed-dimensional representations of variable-length speech segments. For zero-resource languages where labelled data is not available, one AWE approach is to use unsupervised autoencoder-based recurrent models. Another recent approach is to use multilingual transfer: a supervised AWE model is trained on several well-resourced languages and then applied to an unseen zero-resource language. We consider how a recent contrastive learning loss can be used in both the purely unsupervised and multilingual transfer settings. Firstly, we show that terms from an unsupervised term discovery system can be used for contrastive self-supervision, resulting in improvements over previous unsupervised monolingual AWE models. Secondly, we consider how multilingual AWE models can be adapted to a specific zero-resource language using discovered terms. We find that self-supervised contrastive adaptation outperforms adapted multilingual correspondence autoencoder and Siamese AWE models, giving the best overall results in a word discrimination task on six zero-resource languages.