 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan LLMs Score Medical Diagnoses and Clinical Reasoning as well as Expert Panels?
Apr 16, 2026Evaluating medical AI systems using expert clinician panels is costly and slow, motivating the use of large language models (LLMs) as alternative adjudicators. Here, we evaluate an LLM jury composed of three frontier AI models scoring 3333 diagnoses on 300 real-world middle-income country (MIC) hospital cases. Model performance was benchmarked against expert clinician panel and independent human re-scoring panel evaluations. Both LLM and clinician-generated diagnoses are scored across four dimensions: diagnosis, differential diagnosis, clinical reasoning and negative treatment risk. For each of these, we assess scoring difference, inter-rater agreement, scoring stability, severe safety errors and the effect of post-hoc calibration. We find that: (i) the uncalibrated LLM jury scores are systematically lower than clinician panels scores; (ii) the LLM Jury preserves ordinal agreement and exhibits better concordance with the primary expert panels than the human expert re-score panels do; (iii) the probability of severe errors is lower in \lj models compared to the human expert re-score panels; (iv) the LLM Jury shows excellent agreement with primary expert panels' rankings. We find that the LLM jury combined with AI model diagnoses can be used to identify ward diagnoses at high risk of error, enabling targeted expert review and improved panel efficiency; (v) LLM jury models show no self-preference bias. They did not score diagnoses generated by their own underlying model or models from the same vendor more (or less) favourably than those generated by other models. Finally, we demonstrate that LLM jury calibration using isotonic regression improves alignment with human expert panel evaluations. Together, these results provide compelling evidence that a calibrated, multi-model LLM jury can serve as a trustworthy and reliable proxy for expert clinician evaluation in medical AI benchmarking.
Calibrating Beyond English: Language Diversity for Better Quantized Multilingual LLM
Jan 26, 2026Quantization is an effective technique for reducing the storage footprint and computational costs of Large Language Models (LLMs), but it often results in performance degradation. Existing post-training quantization methods typically use small, English-only calibration sets; however, their impact on multilingual models remains underexplored. We systematically evaluate eight calibration settings (five single-language and three multilingual mixes) on two quantizers (GPTQ, AWQ) on data from 10 languages. Our findings reveal a consistent trend: non-English and multilingual calibration sets significantly improve perplexity compared to English-only baselines. Specifically, we observe notable average perplexity gains across both quantizers on Llama3.1 8B and Qwen2.5 7B, with multilingual mixes achieving the largest overall reductions of up to 3.52 points in perplexity. Furthermore, our analysis indicates that tailoring calibration sets to the evaluation language yields the largest improvements for individual languages, underscoring the importance of linguistic alignment. We also identify specific failure cases where certain language-quantizer combinations degrade performance, which we trace to differences in activation range distributions across languages. These results highlight that static one-size-fits-all calibration is suboptimal and that tailoring calibration data, both in language and diversity, plays a crucial role in robustly quantizing multilingual LLMs.
Critical Learning Periods: Leveraging Early Training Dynamics for Efficient Data Pruning
May 29, 2024
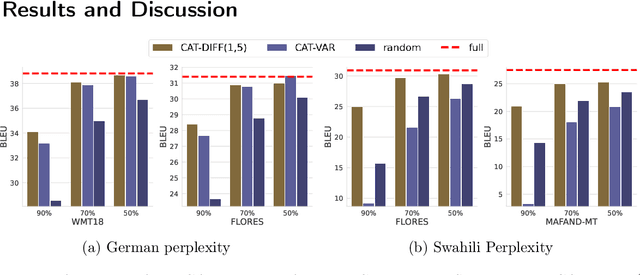
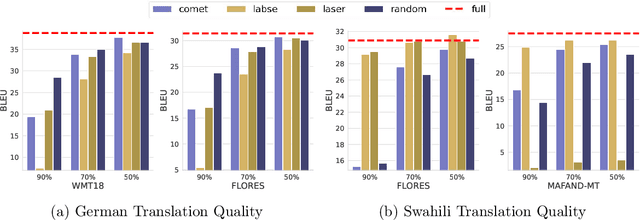
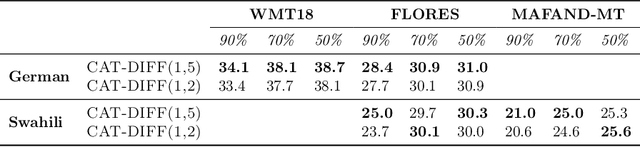
Neural Machine Translation models are extremely data and compute-hungry. However, not all data points contribute equally to model training and generalization. Data pruning to remove the low-value data points has the benefit of drastically reducing the compute budget without significant drop in model performance. In this paper, we propose a new data pruning technique: Checkpoints Across Time (CAT), that leverages early model training dynamics to identify the most relevant data points for model performance. We benchmark CAT against several data pruning techniques including COMET-QE, LASER and LaBSE. We find that CAT outperforms the benchmarks on Indo-European languages on multiple test sets. When applied to English-German, English-French and English-Swahili translation tasks, CAT achieves comparable performance to using the full dataset, while pruning up to 50% of training data. We inspect the data points that CAT selects and find that it tends to favour longer sentences and sentences with unique or rare words.
Towards hate speech detection in low-resource languages: Comparing ASR to acoustic word embeddings on Wolof and Swahili
Jun 01, 2023
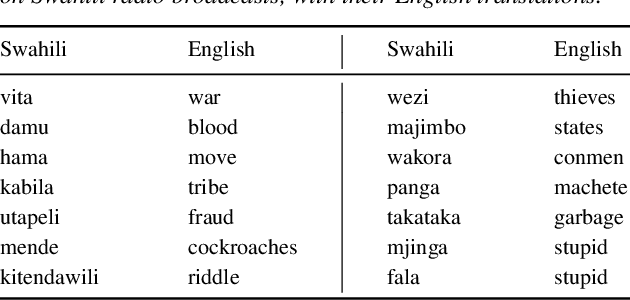

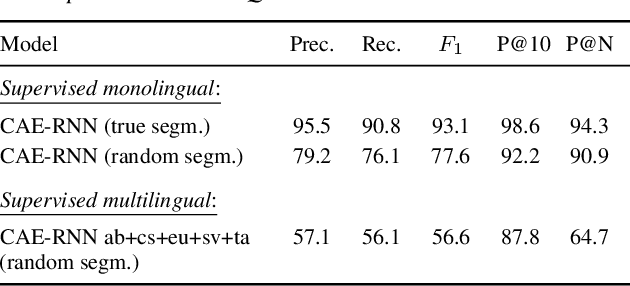
We consider hate speech detection through keyword spotting on radio broadcasts. One approach is to build an automatic speech recognition (ASR) system for the target low-resource language. We compare this to using acoustic word embedding (AWE) models that map speech segments to a space where matching words have similar vectors. We specifically use a multilingual AWE model trained on labelled data from well-resourced languages to spot keywords in data in the unseen target language. In contrast to ASR, the AWE approach only requires a few keyword exemplars. In controlled experiments on Wolof and Swahili where training and test data are from the same domain, an ASR model trained on just five minutes of data outperforms the AWE approach. But in an in-the-wild test on Swahili radio broadcasts with actual hate speech keywords, the AWE model (using one minute of template data) is more robust, giving similar performance to an ASR system trained on 30 hours of labelled data.
Very Low Resource Sentence Alignment: Luhya and Swahili
Oct 31, 2022



Language-agnostic sentence embeddings generated by pre-trained models such as LASER and LaBSE are attractive options for mining large datasets to produce parallel corpora for low-resource machine translation. We test LASER and LaBSE in extracting bitext for two related low-resource African languages: Luhya and Swahili. For this work, we created a new parallel set of nearly 8000 Luhya-English sentences which allows a new zero-shot test of LASER and LaBSE. We find that LaBSE significantly outperforms LASER on both languages. Both LASER and LaBSE however perform poorly at zero-shot alignment on Luhya, achieving just 1.5% and 22.0% successful alignments respectively (P@1 score). We fine-tune the embeddings on a small set of parallel Luhya sentences and show significant gains, improving the LaBSE alignment accuracy to 53.3%. Further, restricting the dataset to sentence embedding pairs with cosine similarity above 0.7 yielded alignments with over 85% accuracy.
Learning to Detect Interesting Anomalies
Oct 28, 2022Anomaly detection algorithms are typically applied to static, unchanging, data features hand-crafted by the user. But how does a user systematically craft good features for anomalies that have never been seen? Here we couple deep learning with active learning -- in which an Oracle iteratively labels small amounts of data selected algorithmically over a series of rounds -- to automatically and dynamically improve the data features for efficient outlier detection. This approach, AHUNT, shows excellent performance on MNIST, CIFAR10, and Galaxy-DESI data, significantly outperforming both standard anomaly detection and active learning algorithms with static feature spaces. Beyond improved performance, AHUNT also allows the number of anomaly classes to grow organically in response to Oracle's evaluations. Extensive ablation studies explore the impact of Oracle question selection strategy and loss function on performance. We illustrate how the dynamic anomaly class taxonomy represents another step towards fully personalized rankings of different anomaly classes that reflect a user's interests, allowing the algorithm to learn to ignore statistically significant but uninteresting outliers (e.g., noise). This should prove useful in the era of massive astronomical datasets serving diverse sets of users who can only review a tiny subset of the incoming data.
COMET-QE and Active Learning for Low-Resource Machine Translation
Oct 27, 2022Active learning aims to deliver maximum benefit when resources are scarce. We use COMET-QE, a reference-free evaluation metric, to select sentences for low-resource neural machine translation. Using Swahili, Kinyarwanda and Spanish for our experiments, we show that COMET-QE significantly outperforms two variants of Round Trip Translation Likelihood (RTTL) and random sentence selection by up to 5 BLEU points for 20k sentences selected by Active Learning on a 30k baseline. This suggests that COMET-QE is a powerful tool for sentence selection in the very low-resource limit.
Low-Resource Neural Machine Translation for Southern African Languages
Apr 03, 2021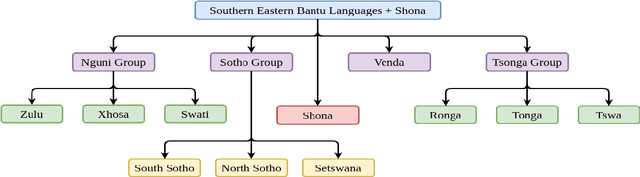

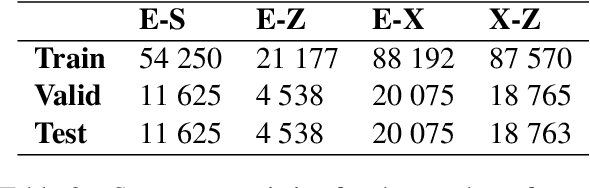

Low-resource African languages have not fully benefited from the progress in neural machine translation because of a lack of data. Motivated by this challenge we compare zero-shot learning, transfer learning and multilingual learning on three Bantu languages (Shona, isiXhosa and isiZulu) and English. Our main target is English-to-isiZulu translation for which we have just 30,000 sentence pairs, 28% of the average size of our other corpora. We show the importance of language similarity on the performance of English-to-isiZulu transfer learning based on English-to-isiXhosa and English-to-Shona parent models whose BLEU scores differ by 5.2. We then demonstrate that multilingual learning surpasses both transfer learning and zero-shot learning on our dataset, with BLEU score improvements relative to the baseline English-to-isiZulu model of 9.9, 6.1 and 2.0 respectively. Our best model also improves the previous SOTA BLEU score by more than 10.
Deep Evolution for Facial Emotion Recognition
Oct 13, 2020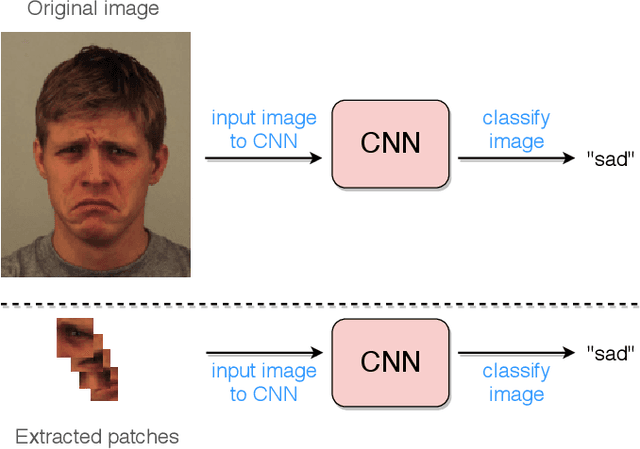
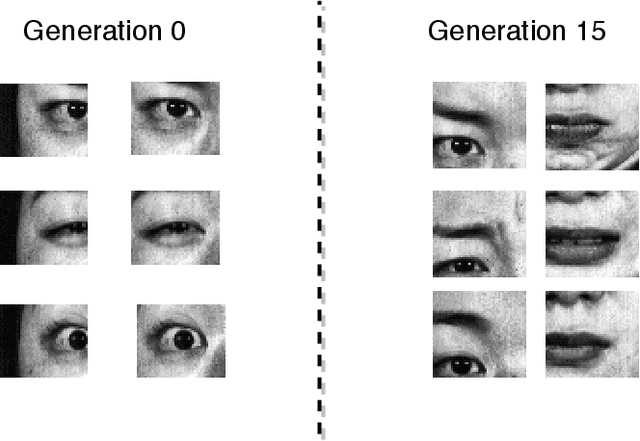
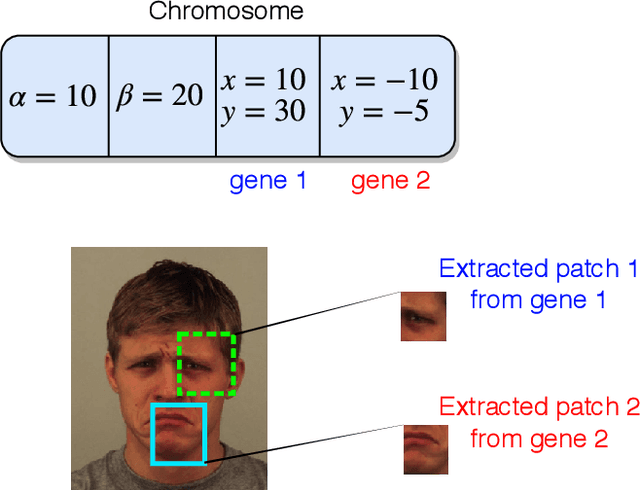

Deep facial expression recognition faces two challenges that both stem from the large number of trainable parameters: long training times and a lack of interpretability. We propose a novel method based on evolutionary algorithms, that deals with both challenges by massively reducing the number of trainable parameters, whilst simultaneously retaining classification performance, and in some cases achieving superior performance. We are robustly able to reduce the number of parameters on average by 95% (e.g. from 2M to 100k parameters) with no loss in classification accuracy. The algorithm learns to choose small patches from the image, relative to the nose, which carry the most important information about emotion, and which coincide with typical human choices of important features. Our work implements a novel form attention and shows that evolutionary algorithms are a valuable addition to machine learning in the deep learning era, both for reducing the number of parameters for facial expression recognition and for providing interpretable features that can help reduce bias.
A Flexible Framework for Anomaly Detection via Dimensionality Reduction
Sep 09, 2019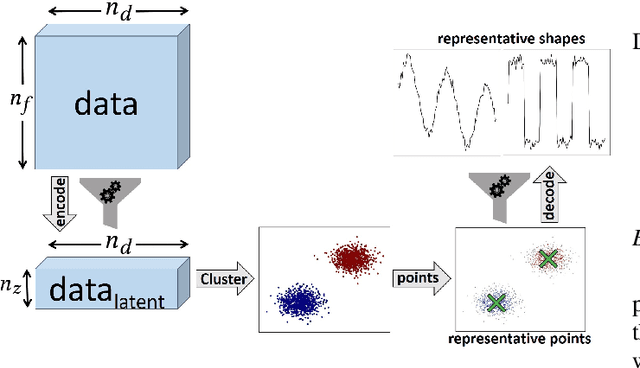
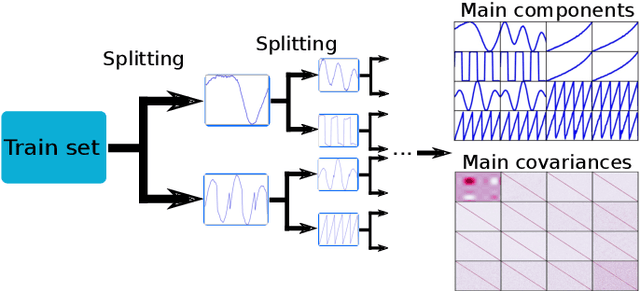
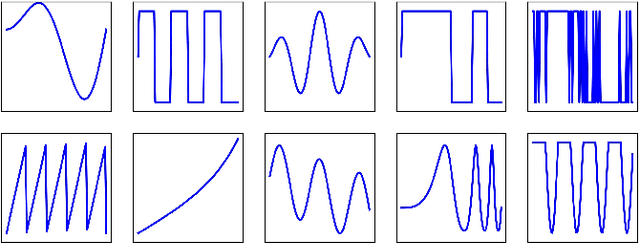
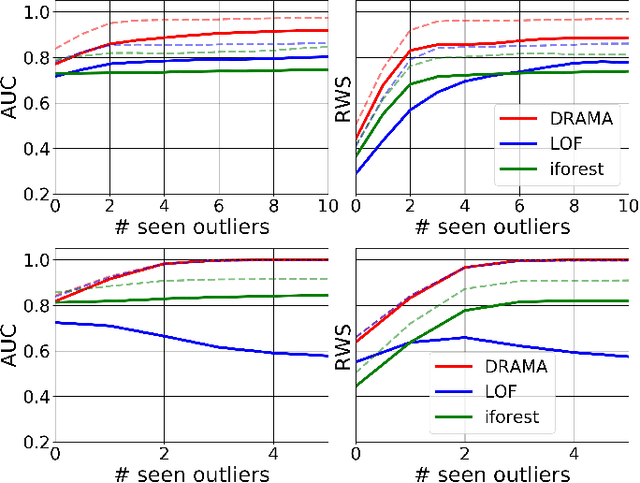
Anomaly detection is challenging, especially for large datasets in high dimensions. Here we explore a general anomaly detection framework based on dimensionality reduction and unsupervised clustering. We release DRAMA, a general python package that implements the general framework with a wide range of built-in options. We test DRAMA on a wide variety of simulated and real datasets, in up to 3000 dimensions, and find it robust and highly competitive with commonly-used anomaly detection algorithms, especially in high dimensions. The flexibility of the DRAMA framework allows for significant optimization once some examples of anomalies are available, making it ideal for online anomaly detection, active learning and highly unbalanced datasets.