 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Evolution for Facial Emotion Recognition
Oct 13, 2020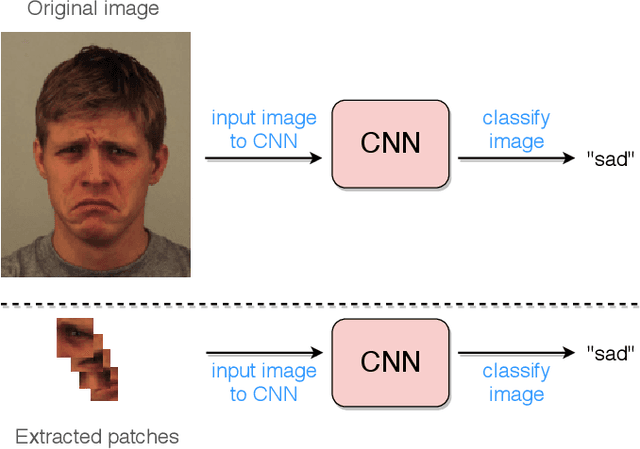
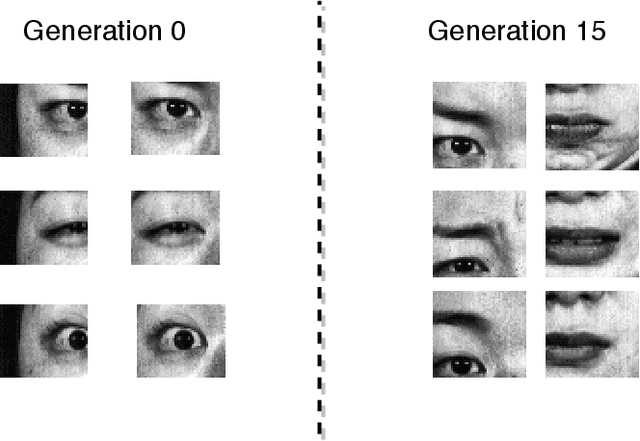
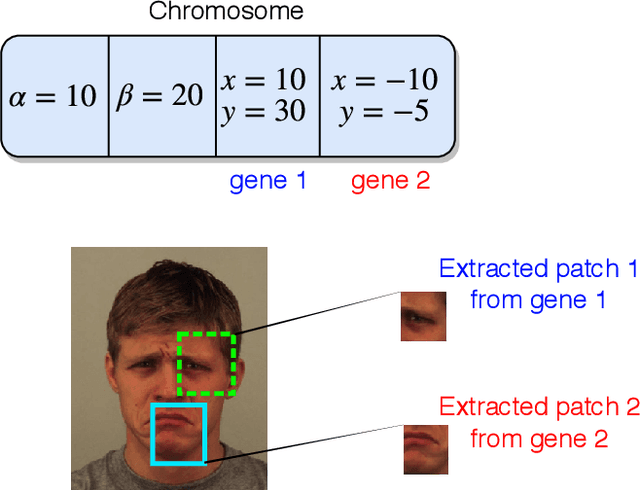

Deep facial expression recognition faces two challenges that both stem from the large number of trainable parameters: long training times and a lack of interpretability. We propose a novel method based on evolutionary algorithms, that deals with both challenges by massively reducing the number of trainable parameters, whilst simultaneously retaining classification performance, and in some cases achieving superior performance. We are robustly able to reduce the number of parameters on average by 95% (e.g. from 2M to 100k parameters) with no loss in classification accuracy. The algorithm learns to choose small patches from the image, relative to the nose, which carry the most important information about emotion, and which coincide with typical human choices of important features. Our work implements a novel form attention and shows that evolutionary algorithms are a valuable addition to machine learning in the deep learning era, both for reducing the number of parameters for facial expression recognition and for providing interpretable features that can help reduce bias.
Automated Classification of Text Sentiment
Apr 05, 2018


The ability to identify sentiment in text, referred to as sentiment analysis, is one which is natural to adult humans. This task is, however, not one which a computer can perform by default. Identifying sentiments in an automated, algorithmic manner will be a useful capability for business and research in their search to understand what consumers think about their products or services and to understand human sociology. Here we propose two new Genetic Algorithms (GAs) for the task of automated text sentiment analysis. The GAs learn whether words occurring in a text corpus are either sentiment or amplifier words, and their corresponding magnitude. Sentiment words, such as 'horrible', add linearly to the final sentiment. Amplifier words in contrast, which are typically adjectives/adverbs like 'very', multiply the sentiment of the following word. This increases, decreases or negates the sentiment of the following word. The sentiment of the full text is then the sum of these terms. This approach grows both a sentiment and amplifier dictionary which can be reused for other purposes and fed into other machine learning algorithms. We report the results of multiple experiments conducted on large Amazon data sets. The results reveal that our proposed approach was able to outperform several public and/or commercial sentiment analysis algorithms.
EDEN: Evolutionary Deep Networks for Efficient Machine Learning
Sep 26, 2017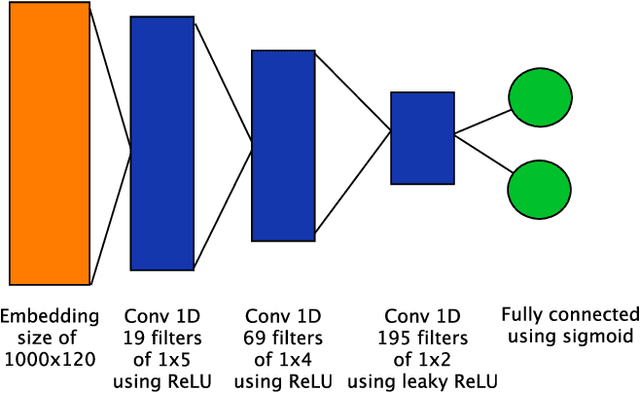
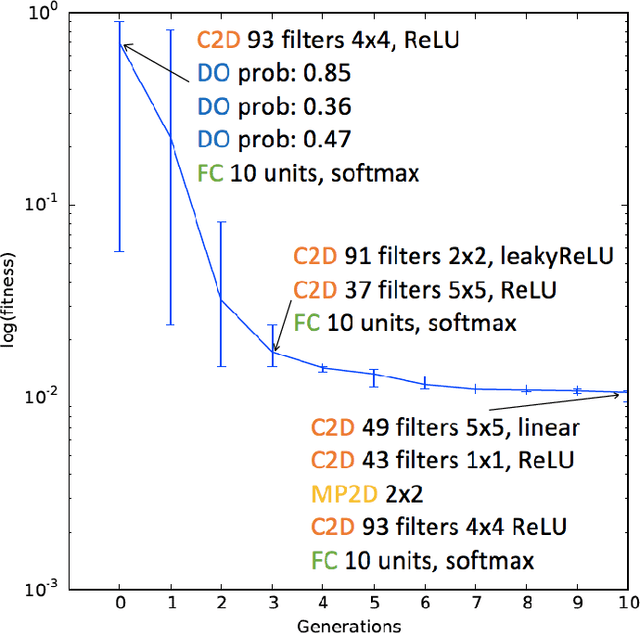
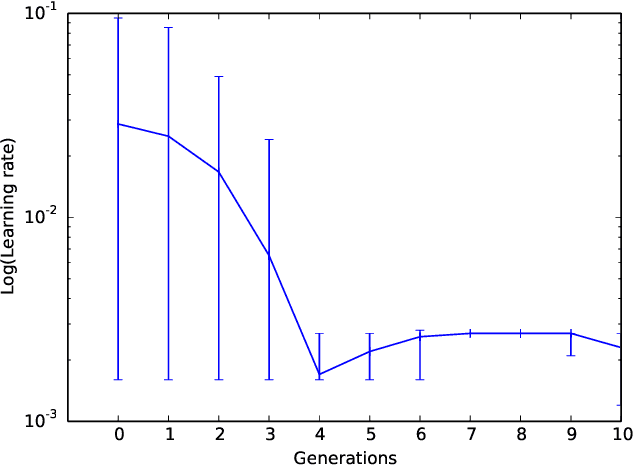
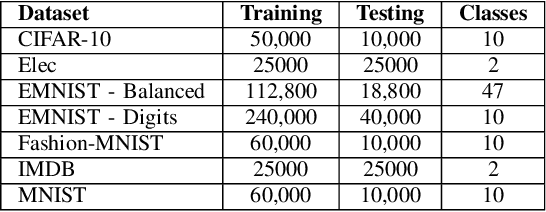
Deep neural networks continue to show improved performance with increasing depth, an encouraging trend that implies an explosion in the possible permutations of network architectures and hyperparameters for which there is little intuitive guidance. To address this increasing complexity, we propose Evolutionary DEep Networks (EDEN), a computationally efficient neuro-evolutionary algorithm which interfaces to any deep neural network platform, such as TensorFlow. We show that EDEN evolves simple yet successful architectures built from embedding, 1D and 2D convolutional, max pooling and fully connected layers along with their hyperparameters. Evaluation of EDEN across seven image and sentiment classification datasets shows that it reliably finds good networks -- and in three cases achieves state-of-the-art results -- even on a single GPU, in just 6-24 hours. Our study provides a first attempt at applying neuro-evolution to the creation of 1D convolutional networks for sentiment analysis including the optimisation of the embedding layer.
Text Compression for Sentiment Analysis via Evolutionary Algorithms
Sep 20, 2017
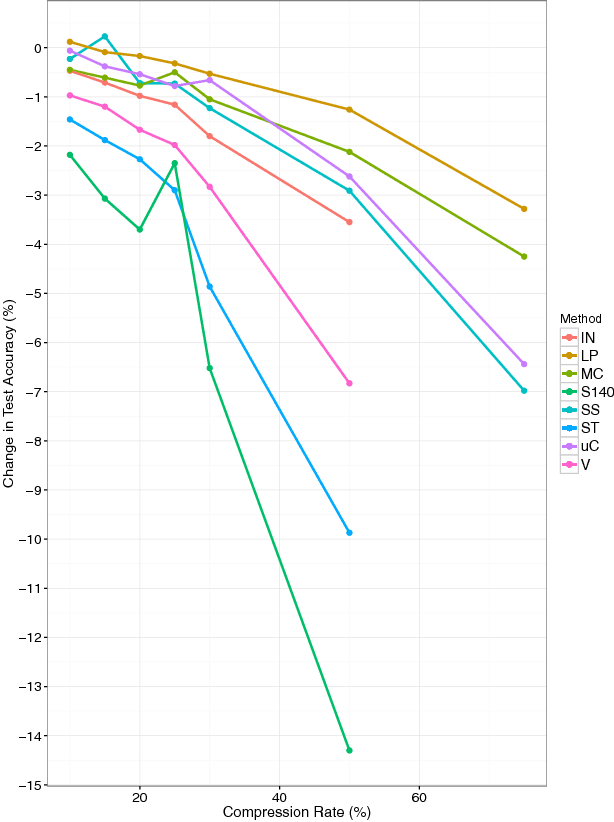

Can textual data be compressed intelligently without losing accuracy in evaluating sentiment? In this study, we propose a novel evolutionary compression algorithm, PARSEC (PARts-of-Speech for sEntiment Compression), which makes use of Parts-of-Speech tags to compress text in a way that sacrifices minimal classification accuracy when used in conjunction with sentiment analysis algorithms. An analysis of PARSEC with eight commercial and non-commercial sentiment analysis algorithms on twelve English sentiment data sets reveals that accurate compression is possible with (0%, 1.3%, 3.3%) loss in sentiment classification accuracy for (20%, 50%, 75%) data compression with PARSEC using LingPipe, the most accurate of the sentiment algorithms. Other sentiment analysis algorithms are more severely affected by compression. We conclude that significant compression of text data is possible for sentiment analysis depending on the accuracy demands of the specific application and the specific sentiment analysis algorithm used.
Automated Problem Identification: Regression vs Classification via Evolutionary Deep Networks
Jul 03, 2017



Regression or classification? This is perhaps the most basic question faced when tackling a new supervised learning problem. We present an Evolutionary Deep Learning (EDL) algorithm that automatically solves this by identifying the question type with high accuracy, along with a proposed deep architecture. Typically, a significant amount of human insight and preparation is required prior to executing machine learning algorithms. For example, when creating deep neural networks, the number of parameters must be selected in advance and furthermore, a lot of these choices are made based upon pre-existing knowledge of the data such as the use of a categorical cross entropy loss function. Humans are able to study a dataset and decide whether it represents a classification or a regression problem, and consequently make decisions which will be applied to the execution of the neural network. We propose the Automated Problem Identification (API) algorithm, which uses an evolutionary algorithm interface to TensorFlow to manipulate a deep neural network to decide if a dataset represents a classification or a regression problem. We test API on 16 different classification, regression and sentiment analysis datasets with up to 10,000 features and up to 17,000 unique target values. API achieves an average accuracy of $96.3\%$ in identifying the problem type without hardcoding any insights about the general characteristics of regression or classification problems. For example, API successfully identifies classification problems even with 1000 target values. Furthermore, the algorithm recommends which loss function to use and also recommends a neural network architecture. Our work is therefore a step towards fully automated machine learning.