 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCritical Learning Periods: Leveraging Early Training Dynamics for Efficient Data Pruning
Paper and Code

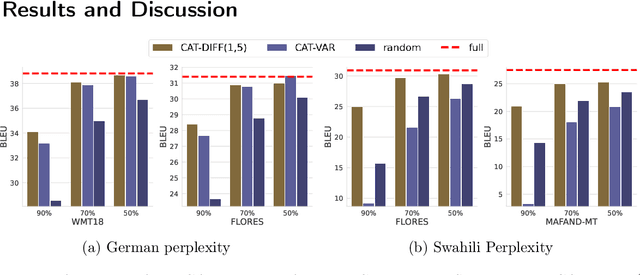
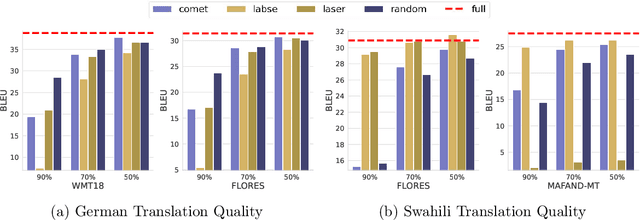
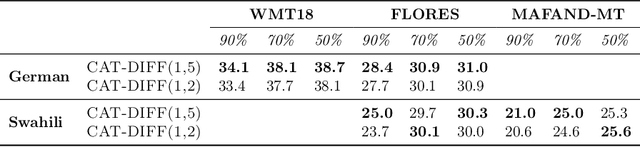
Neural Machine Translation models are extremely data and compute-hungry. However, not all data points contribute equally to model training and generalization. Data pruning to remove the low-value data points has the benefit of drastically reducing the compute budget without significant drop in model performance. In this paper, we propose a new data pruning technique: Checkpoints Across Time (CAT), that leverages early model training dynamics to identify the most relevant data points for model performance. We benchmark CAT against several data pruning techniques including COMET-QE, LASER and LaBSE. We find that CAT outperforms the benchmarks on Indo-European languages on multiple test sets. When applied to English-German, English-French and English-Swahili translation tasks, CAT achieves comparable performance to using the full dataset, while pruning up to 50% of training data. We inspect the data points that CAT selects and find that it tends to favour longer sentences and sentences with unique or rare words.