 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Voice Behind the Words: Quantifying Intersectional Bias in SpeechLLMs
Mar 15, 2026Speech Large Language Models (SpeechLLMs) process spoken input directly, retaining cues such as accent and perceived gender that were previously removed in cascaded pipelines. This introduces speaker identity dependent variation in responses. We present a large-scale intersectional evaluation of accent and gender bias in three SpeechLLMs using 2,880 controlled interactions across six English accents and two gender presentations, keeping linguistic content constant through voice cloning. Using pointwise LLM-judge ratings, pairwise comparisons, and Best-Worst Scaling with human validation, we detect consistent disparities. Eastern European-accented speech receives lower helpfulness scores, particularly for female-presenting voices. The bias is implicit: responses remain polite but differ in helpfulness. While LLM judges capture the directional trend of these biases, human evaluators exhibit significantly higher sensitivity, uncovering sharper intersectional disparities.
TTSDS2: Resources and Benchmark for Evaluating Human-Quality Text to Speech Systems
Jun 24, 2025
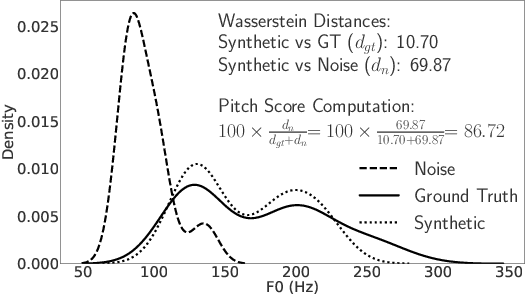
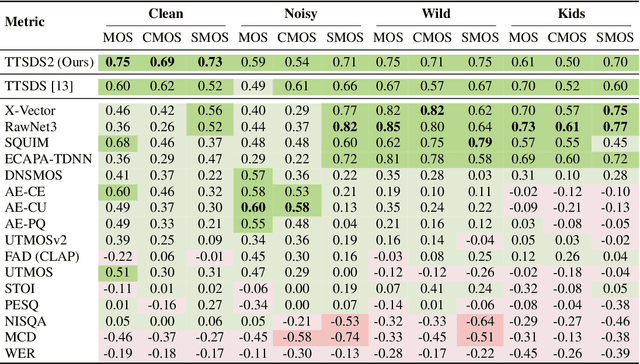
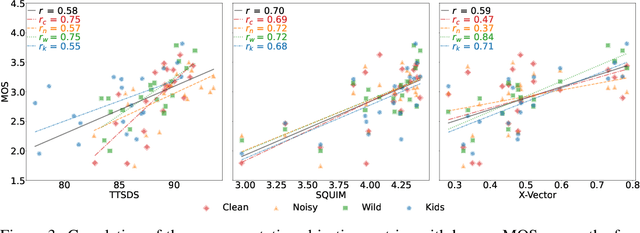
Evaluation of Text to Speech (TTS) systems is challenging and resource-intensive. Subjective metrics such as Mean Opinion Score (MOS) are not easily comparable between works. Objective metrics are frequently used, but rarely validated against subjective ones. Both kinds of metrics are challenged by recent TTS systems capable of producing synthetic speech indistinguishable from real speech. In this work, we introduce Text to Speech Distribution Score 2 (TTSDS2), a more robust and improved version of TTSDS. Across a range of domains and languages, it is the only one out of 16 compared metrics to correlate with a Spearman correlation above 0.50 for every domain and subjective score evaluated. We also release a range of resources for evaluating synthetic speech close to real speech: A dataset with over 11,000 subjective opinion score ratings; a pipeline for continually recreating a multilingual test dataset to avoid data leakage; and a continually updated benchmark for TTS in 14 languages.
Beyond Oversmoothing: Evaluating DDPM and MSE for Scalable Speech Synthesis in ASR
Oct 16, 2024


Synthetically generated speech has rapidly approached human levels of naturalness. However, the paradox remains that ASR systems, when trained on TTS output that is judged as natural by humans, continue to perform badly on real speech. In this work, we explore whether this phenomenon is due to the oversmoothing behaviour of models commonly used in TTS, with a particular focus on the behaviour of TTS-for-ASR as the amount of TTS training data is scaled up. We systematically compare Denoising Diffusion Probabilistic Models (DDPM) to Mean Squared Error (MSE) based models for TTS, when used for ASR model training. We test the scalability of the two approaches, varying both the number hours, and the number of different speakers. We find that for a given model size, DDPM can make better use of more data, and a more diverse set of speakers, than MSE models. We achieve the best reported ratio between real and synthetic speech WER to date (1.46), but also find that a large gap remains.
TTSDS -- Text-to-Speech Distribution Score
Jul 17, 2024



Many recently published Text-to-Speech (TTS) systems produce audio close to real speech. However, TTS evaluation needs to be revisited to make sense of the results obtained with the new architectures, approaches and datasets. We propose evaluating the quality of synthetic speech as a combination of multiple factors such as prosody, speaker identity, and intelligibility. Our approach assesses how well synthetic speech mirrors real speech by obtaining correlates of each factor and measuring their distance from both real speech datasets and noise datasets. We benchmark 35 TTS systems developed between 2008 and 2024 and show that our score computed as an unweighted average of factors strongly correlates with the human evaluations from each time period.
Evaluating and reducing the distance between synthetic and real speech distributions
Nov 29, 2022While modern Text-to-Speech (TTS) systems can produce speech rated highly in terms of subjective evaluation, the distance between real and synthetic speech distributions remains understudied, where we use the term \textit{distribution} to mean the sample space of all possible real speech recordings from a given set of speakers; or of the synthetic samples that could be generated for the same set of speakers. We evaluate the distance of real and synthetic speech distributions along the dimensions of the acoustic environment, speaker characteristics and prosody using a range of speech processing measures and the respective Wasserstein distances of their distributions. We reduce these distribution distances along said dimensions by providing utterance-level information derived from the measures to the model and show they can be generated at inference time. The improvements to the dimensions translate to overall distribution distance reduction approximated using Automatic Speech Recognition (ASR) by evaluating the fitness of the synthetic data as training data.
Mask-combine Decoding and Classification Approach for Punctuation Prediction with real-time Inference Constraints
Dec 17, 2021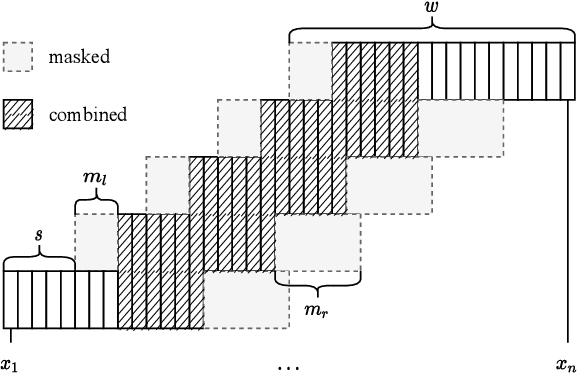
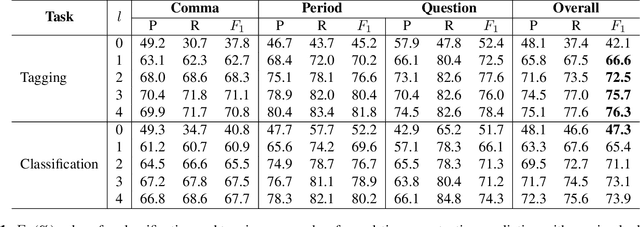
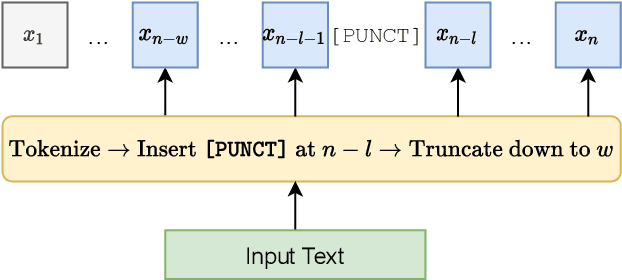
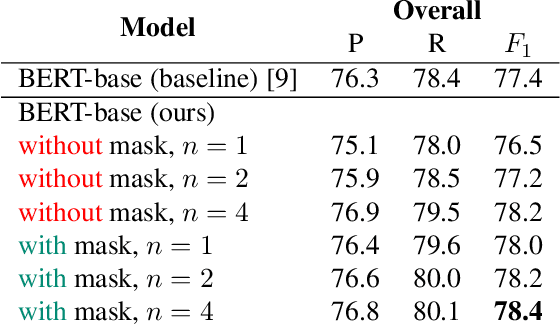
In this work, we unify several existing decoding strategies for punctuation prediction in one framework and introduce a novel strategy which utilises multiple predictions at each word across different windows. We show that significant improvements can be achieved by optimising these strategies after training a model, only leading to a potential increase in inference time, with no requirement for retraining. We further use our decoding strategy framework for the first comparison of tagging and classification approaches for punctuation prediction in a real-time setting. Our results show that a classification approach for punctuation prediction can be beneficial when little or no right-side context is available.